KoBART 코드 리뷰
SKT - KoBART Github 에서 진행함.
Hugginface Code KoBART는 Huggingface Bart Code Base임
Huggingface - BartForConditionalGeneration
핵심내용 - Bartmodel 위에 Task에 맞는 추가적인 layer 및 모듈을 쌓아야한다.
Bart Architecture
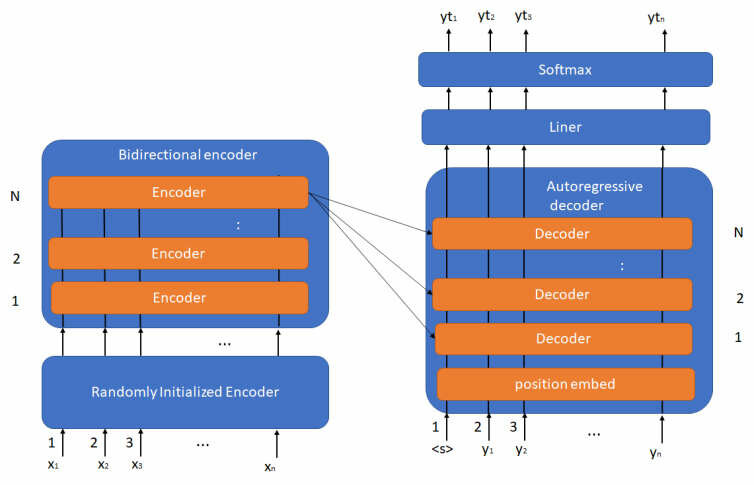
- Bart는 Transformer의 기본 아키텍처인 Encoder-Decoder구조를 갖고 있다.
- 따라서 코드도 Encoder와 Decoder를 차례로 통과한다.
- Input data도 Encoder_input과 Decoder_input을 따로 준비해야한다.
- 어떻게 input을 넣어주냐에 따라 Task마다 학습/추론 방법이 갈린다.
Encoder 모듈 코드
class BartEncoder(BartPreTrainedModel):
def __init__(self):
super().__init__()
self.dropout = config.dropout
self.layerdrop = config.encoder_layerdrop
embed_dim = config.d_model
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if config.scale_embedding else 1.0
self.embed_tokens = nn.Embedding(config.vocab_size, embed_dim, self.padding_idx)
self.embed_positions = BartLearnedPositionalEmbedding(
config.max_position_embeddings,
embed_dim,
)
self.layers = nn.ModuleList([BartEncoderLayer(config) for _ in range(config.encoder_layers)])
self.layernorm_embedding = nn.LayerNorm(embed_dim)
def forward(self,
input_ids, attention_mask,
inputs_embeds: Optional[torch.FloatTensor] = None,
):
input = input_ids
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input)
embed_pos = embed_pos.to(inputs_embeds.device)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
for idx, encoder_layer in enumerate(self.layers):
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
# hidden_states는 Decoder의 encoder_hidden_states인자로 들어감- 이때 encoder_output[0]은 hidden_states이고 (B,Seq_len,Model_D)
Decoder 모듈 코드
class BartDecoder(BartPreTrainedModel):
def forward(
self,
input_ids,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
):
inputs_embeds = self.embed_tokens(input) * self.embed_scale
positions = self.embed_positions(input, past_key_values_length)
positions = positions.to(inputs_embeds.device)
hidden_states = inputs_embeds + positions
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
for idx, decoder_layer in enumerate(self.layers):
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
cross_attn_layer_head_mask=(
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None
),
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
return tuple(
v
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
if v is not None
)Decoder Layer
디코터 Layer 한층 , Cross Attention사용
class BartDecoderLayer(nn.Module):
def forward(
self,
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
layer_head_mask,
cross_attn_layer_head_mask,
past_key_value,
output_attentions,
use_cache,
)
residual = hidden_states
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
return outputsText Classification
Decoder_input없이 Encoder_input만 들어감 -> 사실 복사해서 사용 [참고]
class BartForConditionalGeneration(BartPreTrainedModel):
def forward(self,):
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,)
# Decoder_input을 만들어 주기 위한 함수
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
shifted_input_ids[:, 0] = decoder_start_token_id
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
return shifted_input_ids- 의문점 : SKT의 KoBART에서 BOS , EOS , Decoder_start_token_id 는 모두 1임.Huggingface - KoBART Config
- 아래는 Huggingface - BartForSequenceClassification의 코드
eos_mask = input_ids.eq(self.config.eos_token_id).to(hidden_states.device)
if len(torch.unique_consecutive(eos_mask.sum(1))) > 1:
raise ValueError("All examples must have the same number of <eos> tokens.")
sentence_representation = hidden_states[eos_mask, :].view(hidden_states.size(0), -1, hidden_states.size(-1))[:, -1, :]를 보면 eos토큰의 Vector를 추출함
나는 BOS + 내용 + EOS를 해서 EOS가 중복이 안되지만 전처리를 기존 Config파일 대로 하면 EOS EOS 내용 EOS 가 되어 에러가 나지않을지???
ㄴ> model import 후 직접 출력해보니 BOS:0 / EOS:1 / Decoder_start : 2
- 느낀점 : 첫번째 패착원인은 내가 참조링크가 서로 달랐다는 점이고 두번째는 config파일이나 Docs에 있는 하이퍼파라미터는 참고하되 직접 출력해보자.
Text Generation
pytorch의 Text Generation은 transformers.GenerationMixin에서 실행 [참고]
내부동작 예제코드
from transformers import BartForConditionalGeneration, BartTokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v1')
model = BartForConditionalGeneration.from_pretrained('gogamza/kobart-base-v1')
inputs = tokenizer(["This is a test. Hello world"], return_tensors="pt")
encoder = model.model.encoder
# z.last_hidden_state has the encoded output. If you manipulate it, you may need to
# rebuild the `BaseModelOutput` data class, which `.generate()` expects
z = encoder(input_ids=inputs["input_ids"])
A = model.generate(encoder_outputs=z, max_new_tokens=20)
print(tokenizer.decode(A[0], skip_special_tokens=True))-
위와 같은 방법으로 생성
-
리뷰 코드는 학습할 땐 autoregressive한 방법이 아니라 전체를 CrossAttention하며 생성할 때만 순차적으로 입력.
-
학습할 땐 Decoder_input에 대한 모든 hidden에 대해서 cross_entropy loss를 구한다.

Trendy AI Developer