SpinalNet
SpinalNet paper(2022)
Computer Vision분야의 분류 딥러닝 모델은 보통 feature extractor + classification으로 나뉜다.
- classification는 많은 파라미터를 가진다.
- CNN모델에서 파라미터 수가 가장 많은 부분이 fc layer임
- SpinalNet은 FC층 (classification층)의 효율적이고 높은 성능의 방법을 제시한다.
기존의 fc layer vs Spinal layer
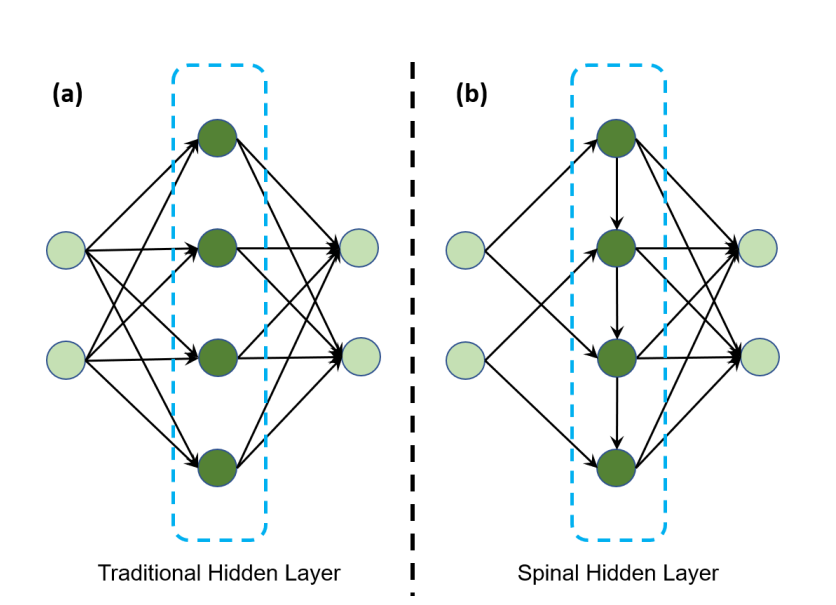
- 인간의 생물학적 구조에서 영감을 받음
- 핵심은 CNN층에서 뽑은 feature를 모든 layer에서 입력으로 받으므로 모든 레이어가 마지막 out_layer결정에 기여함
- 이는 일종의 gradient highway를 갖음
CODE
- 기존 fc층
- 파라미터수 : (9216+1)x4096 + (4096+1)x4096 + (4096*1)x10 = 54,575,104개
Spinal의 output_size와 맞춤(10class)
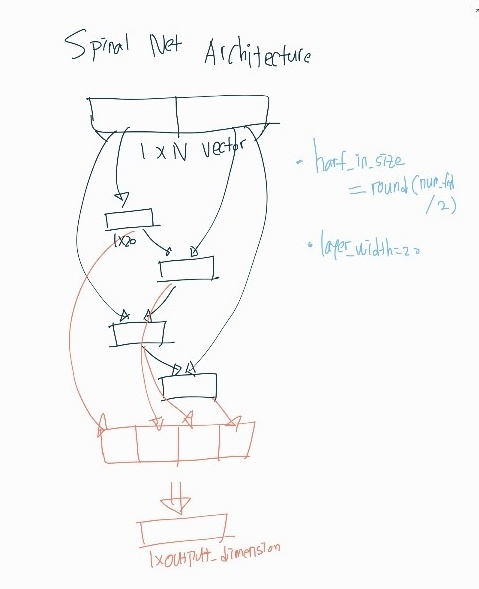
- spinal 구조의 fc층
- (4608+1)x20 + (4608+20+1)X20X3 + (20X4+1)X10 = 370,730개
num_ftrs = model_ft.classifier[1].in_features
#model_ft = models.wide_resnet101_2(pretrained=True)
#num_ftrs = model_ft.fc.in_features
half_in_size = round(num_ftrs/2)
layer_width = 20 #Small for Resnet, large for VGG
Num_class=10
class SpinalNet_ResNet(nn.Module):
def __init__(self):
super(SpinalNet_ResNet, self).__init__()
self.fc_spinal_layer1 = nn.Sequential(
#nn.Dropout(p = 0.5),
nn.Linear(half_in_size, layer_width),
#nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_spinal_layer2 = nn.Sequential(
#nn.Dropout(p = 0.5),
nn.Linear(half_in_size+layer_width, layer_width),
#nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_spinal_layer3 = nn.Sequential(
#nn.Dropout(p = 0.5),
nn.Linear(half_in_size+layer_width, layer_width),
#nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_spinal_layer4 = nn.Sequential(
#nn.Dropout(p = 0.5),
nn.Linear(half_in_size+layer_width, layer_width),
#nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_out = nn.Sequential(
#nn.Dropout(p = 0.5),
nn.Linear(layer_width*4, Num_class),)
def forward(self, x):
x = torch.flatten(x, start_dim=1)
#print('length of x:', len(x))
x1 = self.fc_spinal_layer1(x[:, 0:half_in_size])
x2 = self.fc_spinal_layer2(torch.cat([ x[:,half_in_size:2*half_in_size], x1], dim=1))
x3 = self.fc_spinal_layer3(torch.cat([ x[:,0:half_in_size], x2], dim=1))
x4 = self.fc_spinal_layer4(torch.cat([ x[:,half_in_size:2*half_in_size], x3], dim=1))
x = torch.cat([x1, x2], dim=1)
x = torch.cat([x, x3], dim=1)
x = torch.cat([x, x4], dim=1)
x = self.fc_out(x)
return x
model_ft.classifier = SpinalNet_ResNet()#VGG_fc#SpinalNet_VGG() - vgg(깊은 딥러닝 모델)
class SpinalNet_VGG(nn.Module):
def __init__(self):
super(SpinalNet_VGG, self).__init__()
self.fc_spinal_layer1 = nn.Sequential(
nn.Dropout(p = 0.5), nn.Linear(half_in_size, layer_width),
nn.BatchNorm1d(layer_width), nn.ReLU(inplace=True),)
self.fc_spinal_layer2 = nn.Sequential(
nn.Dropout(p = 0.5),
nn.Linear(half_in_size+layer_width, layer_width),
nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_spinal_layer3 = nn.Sequential(
nn.Dropout(p = 0.5),
nn.Linear(half_in_size+layer_width, layer_width),
nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_spinal_layer4 = nn.Sequential(
nn.Dropout(p = 0.5),
nn.Linear(half_in_size+layer_width, layer_width),
nn.BatchNorm1d(layer_width),
nn.ReLU(inplace=True),)
self.fc_out = nn.Sequential(
nn.Dropout(p = 0.5),
nn.Linear(layer_width*4, Num_class),)
def forward(self, x):
x1 = self.fc_spinal_layer1(x[:, 0:half_in_size])
x2 = self.fc_spinal_layer2(torch.cat([ x[:,half_in_size:2*half_in_size], x1], dim=1))
x3 = self.fc_spinal_layer3(torch.cat([ x[:,0:half_in_size], x2], dim=1))
x4 = self.fc_spinal_layer4(torch.cat([ x[:,half_in_size:2*half_in_size], x3], dim=1))
x = torch.cat([x1, x2], dim=1)
x = torch.cat([x, x3], dim=1)
x = torch.cat([x, x4], dim=1)
x = self.fc_out(x)
return x파라미터가 54,575,104개에서 370,730개로 확 줄었지만 성능은 오히려 증가함
총평(내생각)
-
이미 score가 높은 데이터셋 MNIST시리즈 같은 경우는 99.81% -> 99.82% 와 같이 acc변화가 별로 없다고 생각했지만 Error reduction은 5.3%나 향상 된 것이었다.
- 확실히 일반적인 fc layer를 쓰는 것 보다 성능향상이 확실히 있었다.
-
하지만 가장 중요한 부분은 파라미터가 눈에 띄게 줄어든다는 것이다.
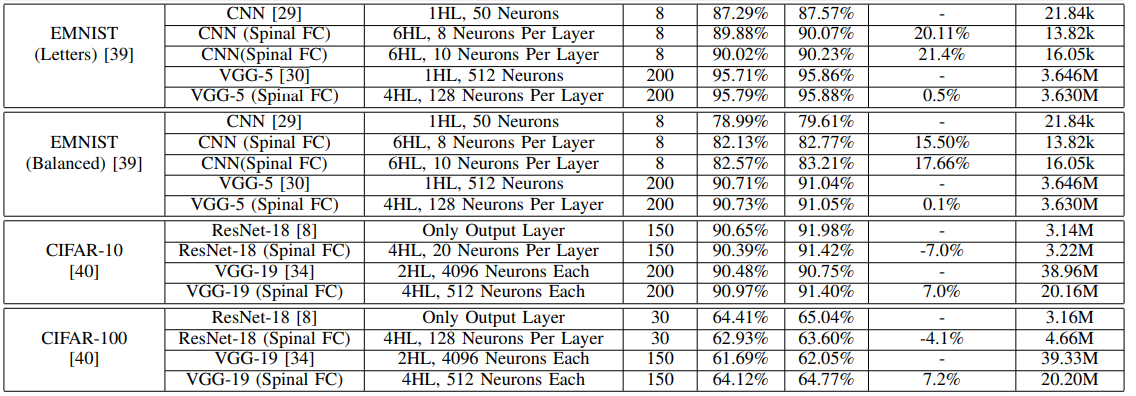
-
잘보면 복잡한 데이터셋은 히든레이어가 2개씩 사용되고 MNIST같은 간단한 데이터 셋은 히든레이어가 1개씩 사용된다.
-
히든레이어가 많이 사용되던 모델일 수록 spinal구조를 사용하여 fc층의 파라미터를 획기적으로 줄일 수 있다.
-
효율적인 측면에서 짱인듯!~!
-
ResNet의 잔차 학습에서도 느꼈지만 spinal net도 일종의 skip connection이라고 생각한다.

Trendy AI Developer