안녕하세요. 밍기뉴와제제입니다.
많이 바빴습니다. 논문을 엄청 많이 보긴 했는데...정리할 시간이 없었습니다. 그런데 다행히도(?) 이번에 봤던 논문들이 죄다 한가지 task에 관한 논문이여서 한번에 묶어서 정리하면 된다는 사실을 알아냈습니다.
그래서, 이번 주제는 최근 몇주간 공부한 AUTOMATED AUDIO CAPTIONING(AAC)에 대해 간단히 알아보는 시간을 갖도록 하겠습니다.
Audio Captioning?
Audio Captioning은 '소리를 설명하는 몇 줄의 글(caption)을 생성하는 것'을 말합니다. 간단히 말하면 소리의 자막을 만드는 것이죠.
Audio Captioning은 들리는 소리를 인지(Recognition)하는 것을 넘어서 소리를 설명할 수 있어야합니다. 소리의 description을 만들어야 하는 것이죠. 고차원의 task입니다.
딥러닝 알고리즘으로 Audio Captioning을 수행해보자
Audio Captioning을 딥러닝 알고리즘으로 수행하려는 시도는 역사가 그리 길지 않습니다.
Audio Captioning을 딥러닝 알고리즘을 이용해 수행하려는 첫 시도는 2017년에 일어났습니다. 그리스 출신의 'Konstantinos Drossos'가 딥러닝 알고리즘으로 Audio Captioning을 수행하는 Task를 AUTOMATED AUDIO CAPTIONING(AAC)이라 정의하며 AAC를 수행하는 네트워크를 처음 제안했습니다. 역사적인 순간이죠.
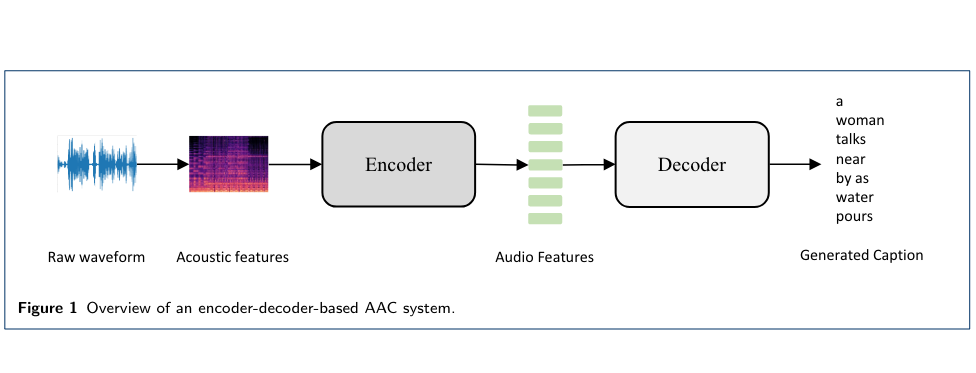
이 때 제시된 네트워크의 구조는
위와 같습니다. Image Captioning을 수행하는 딥러닝 알고리즘 기반 네트워크가 가지는 Encoder-Decoder구조를 사용하였으며 Encoder, Decoder 모두 RNN기반의 네트워크를 사용했습니다. 입력 데이터와 출력 데이터의 domain이 다르기 때문에 Encoder-Decoder 구조를 사용한 것 같습니다.
Drossos는 AAC에 첫 발을 내딛은 것으로 멈추지 않고 지금까지 계속해서 AAC를 위한 연구를 수행하고 있습니다. 여기에 더해 AAC에 관련된 논문이 대다수 등장하는 DCASE Challenge:Task6의 운영진도 하고 있어 저는 이 분을 AAC의 아버지라고 불러도 괜찮지 않을까 생각하고 있습니다.
아무튼, Drossos는 대단한 사람입니다.
AAC의 구성요소
AAC를 수행하는데 필요한 요소들을 간략히 정리해봤습니다. 하나씩 알아봅시다
1. Data form : Mel-Spectrogram
우선 네트워크가 입력받는 데이터 형식을 말씀드릴까 합니다. 데이터 형식에 따라 네트워크의 성능이 많이 달라지기 때문에 매우 중요한 요소라고 할 수 있겠습니다.
우리가 귀로 들을 수 있는 음성 신호는 여러가지 소리가 합쳐진 것입니다. 이를 분석하려면 어떤 신호들이 결합된 것인지 알아야 합니다. 그래서 '주파수' 대역에서 신호의 특성을 파악하려고 했으며 이 때 사용되는 연산이 바로 Fourier Transform, 푸리에 변환입니다.
(이미지 출처 : https://darkpgmr.tistory.com/171)
그런데 이렇게 주파수 대역에서 신호를 분석하려고 하니까 어느 시간대에 해당 주파수의 신호의 크기가 얼마나 되는지를 알 수 없습니다. 소리를 분석할 때 소리가 들리는 시간에 관한 정보도 중요한데 말이죠.
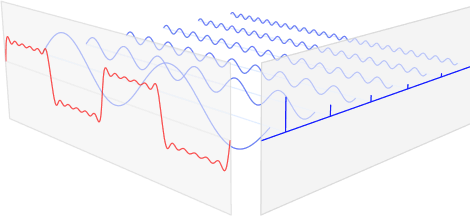
그래서, 우리는 '일정한 시간대별로' 푸리에 변환을 적용하는 Short-time Fourier transform (STFT) 이라는 걸 사용합니다.
우리는 STFT를 이용해 '시간대' 정보와 '주파수' 정보를 모두 가지게 되었습니다. 그러면 이를 하나의 데이터 형식으로 표현할 수 있을겁니다. 이를 Spectrogram이라고 합니다.
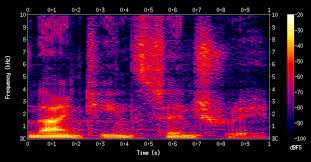
그런데! Spectrogram은 사람이 들을 수 있는 주파수 대역을 고려하지 않았습니다. 사람이 들을 수 있는 주파수 대역은 한정적인데 말이죠.
그래서 사람이 들을 수 있는 범위에 맞게 Log Scaling을 수행한 것이 바로 Mel-Spectrogram입니다.
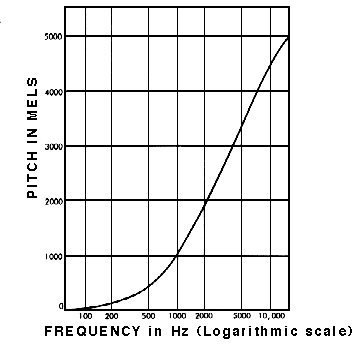
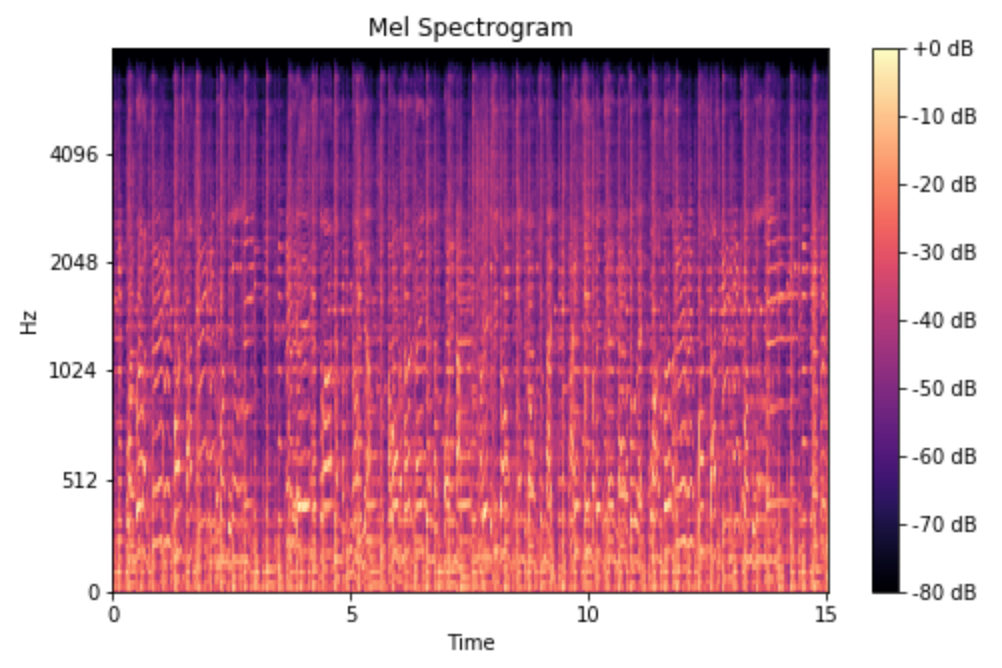
두 이미지의 출처 : https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53
Mel-spectrogram까지 오는데 오랜 시간이 걸렸네요. Mel-spectrogram은 음성 신호를 분석할 때 정말 많이 사용되는 데이터 양식입니다. 왜냐하면 Mel-spectrogram을 사용하니 성능이 잘 나왔기 때문이죠.
정확히 기억 나지는 않지만 데이터 손실이 줄어들어 mel-spectrogram을 사용한다는 말을 들은 것 같습니다.
정리하자면, Mel-Spectrogram을 입력 데이터로 많이 사용합니다.
2.Model Architecture
다음으로 네트워크의 구조를 설명해드리고자 합니다. 하나씩 정리해보겠습니다.
[1] Encoder – Decoder 구조 : 앞서 말씀드렸듯 AAC는 encoder-decoder 구조를 기본 구조로 사용하고 있습니다. 입력 받은 데이터를 특정 크기의 feature vector로 encode 한 뒤, 이를 가지고 caption으로 decode하는 구조인 것이죠. 다른 구조의 네트워크를 AAC에 사용하여 성능을 비교한 실험이 있으면 더 확실한 근거가 되었겠으나 아쉽게도 그러한 실험은 찾지 못했습니다.
[2] Encoder의 구조가 다양하다 : 주로 CNN 등 이미지의 feature map을 생성하는 네트워크를 Encoder로 사용하는 Image Captioning 네트워크와는 달리 AAC는 GRU, LSTM 등 자연어 처리에 주로 쓰이는 네트워크를 사용하기도 하면서 CNN을 encoder로 사용하기도 하였습니다.
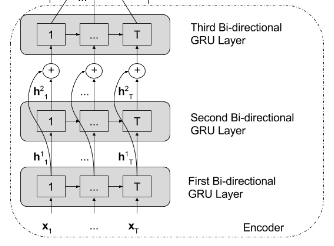
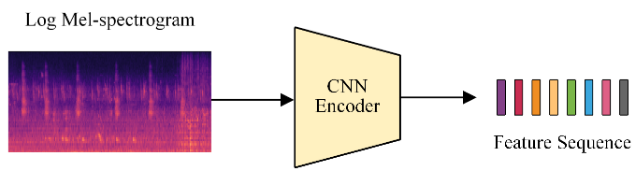
(출처 : https://arxiv.org/pdf/1706.10006.pdf)
(https://dcase.community/documents/workshop2020/proceedings/DCASE2020Workshop_Chen_16.pdf)
[3] Decoder의 구조는 자연어 처리 네트워크의 Decoder를 사용 : Encoder는 다양한 종류의 네트워크를 사용하지만 Decoder는 caption 생성을 담당하기 때문에 자연어 처리를 수행할 때 사용되는 Encoder-Decoder 구조의 네트워크에 있는 Decoder를 사용합니다. 맨 처음 AAC를 위해 제안된 논문에서는 2개의 GRU를 지닌 비교적 간단한 네트워크를 사용했으나 점차 더 복잡한 네트워크를 제안하였고 최근엔 나온 AAC 관련 논문에서는 Decoder로 자연어 처리에서 탁월한 성능을 보여준 Attention mechanism 기반 네트워크를 많이 사용합니다.
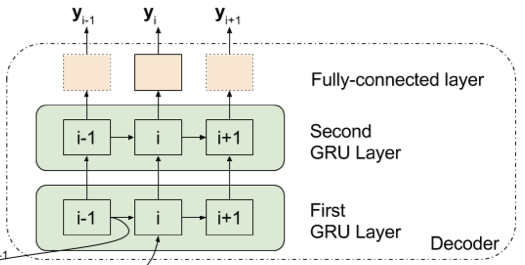
4. 부가적인 정보를 사용 : audio clip 외에도 부가적인 정보를 네트워크에 입력해 성능 향상을 이뤄내기도 합니니다. 대표적인 예로 'keyword'가 있습니다. 허나 keyword를 사용할 때 상승하는 계산량 증가에 비해 성능 향상이 미미한데다 '사전학습 된' 키워드 추출 네트워크를 사용하면 성능향상이 있을 '수' 있다는 불확실한 점이 있어 많은 연구가 필요하다고 볼 수 있겠습니다.
3. Dataset
다음으로 AAC 학습에 사용하는 데이터셋을 몇가지 알아보겠습니다. AAC 데이터셋의 구조는 [음성 데이터, caption] 조합으로 구성되어 있습니다. 주로 Clotho, Audiocaps를 학습, 평가용 데이터셋으로 많이 사용합니다. 사실상 100%라고 볼 수 있겠습니다.
둘 중 하나만 사용하는 논문은 있을지라도 데이터셋을 소개하는 논문이 아닌 이상 두가지 데이터셋을 모두 사용하지 않은 경우는 없다고 보시면 되겠습니다.
그러면 하나씩 간략히 소개해드리도록 하겠습니다.
주요 데이터셋
[1] Clotho : Clotho는 Konstantinos Drossos가 제작에 기여한 데이터셋입니다.

총 4931개의 audio sample과 sample당 5개의 caption을 가지고 있으며 6:2:2의 비율로 training, validation, testing 데이터셋으로 나눠서 사용하게끔 제작되었습니다.
입력 데이터에 해당하는 audio sample은 Freesound에서 가져온 오디오 파일들을 파일의 종류, 오디오의 품질, 재생시간, 오디오에 달린 tag 종류 등의 기준을 가지고 선별한 뒤 trim, resample 의 전처리 과정을 거쳤고 caption은 AMT(Amazon Mechanical Turk)를 통해 라벨링에 지원한 annotator들이 audio sample을 통해 제공받는 정보만 가지고 8~20 단어로 구성된 caption을 제작, 문장 교정 등의 과정을 거쳐 생성됩니다.
이 때 특이한 점은 training 데이터셋에 있는 단어가 validation이나 testing 데이터셋에 한 번 이상 등장하게끔 제작했다는 겁니다. 마지막으로 생성한 caption을 tokenize 합니다.
Clotho는 audio sample당 caption의 종류가 많으며 train, valid, test로 구성되었고 학습에 적합한 형태로 전처리가 수행되어서 그런지 많이 사용되었습니다.
특히, AAC의 대표적인 challenge이자 AAC에 관련한 논문의 상당수가 출간되는 DCASE challenge의 task 6 : Automated Audio Captioning and Language-Based Audio Retrieval에서 사용하게끔 규정된 데이터셋으로 지정되었다는 점, Clotho의 개선판인 Clotho v2가 등장했다는 점을 고려했을 때 향후 몇년간 AAC에서 필수적으로 사용될 데이터셋으로 생각됩니다.
[2] AudioCaps : : AudioCaps는 서울대학교 컴퓨터공학부의 김건희 교수님의 연구실에서 만들어진 데이터셋입니다. 총 39,597개의 audio sample과 45,513개의 caption을 가지고 있으며 다음과 같은 데이터셋 구성을 가지고 있습니다.

데이터셋에 있는 audio sample은 audio event를 위해 만들어진 AudioSet이라는 데이터셋에서 ‘시각적 정보’만 있어도 captioning이 가능한 소리, 전문 지식이 없어도 captioning이 가능한 소리를 선별하였습니다. 그리고 caption은 Clotho와 같이 AMT에서 annotator들을 모집해 아래와 같은 annotation interface에서 생성했습니다.

위 사진은 caption 생성을 위한 Interface입니다. 보시면 단어 힌트와 비디오 힌트가 있는걸 확인하실 수 있습니다.
두가지 힌트는 모두 Audio sample을 가져온 AudioSet에서 해당 Audio sample을 위해 제공되던 것들이며 음성 신호만 가지고 caption을 생성하면 모호한 표현이 나올 수 있어 caption의 정확도를 높이고 풍부한 표현을 생성하도록 만들기 위해 제공하였습니다.
그리고 annotator들의 captioning 능력도 계속해서 검사해 높은 품질의 Caption만 생성되게끔 하였습니다. 이러한 과정을 거쳐 최종적으로 생성된 caption들은 문법 교정 등 몇가지 처리 과정을 거친 뒤 단어 단위로 tokenize하여 최종적인 caption을 완성합니다.

위 그림은 두가지 Video captioning 데이터셋과 AudioCaps를 비교한 그림입니다. Video Captioning 데이터셋의 caption들은 시각적 정보가 있어야 표현할 수 있는 caption들이지만 AudioCaps에 있는 caption들은 청각적 정보만 있어도 표현할 수 있는 caption들이라는 것을 위 그림을 통해 확인하실 수 있습니다.
Conclusion
지금까지 AAC에 대한 정의와 구성요소를 알아봤습니다. 원래 더 자세히 쓰려고 했는데 쓰다보니 서베이 논문를 번역한 것과 뭔 차이가 있을까 싶어서 글의 구성을 바꿨습니다. 그래도 서베이 논문의 다운그레이드로 보이는 느낌이 많이 드는군요.
근데 다시 생각해보니, 특정 분야를 소개하는 글은 서베이 논문과 내용이 비슷한게 정상이 아닌가 싶기도 합니다. 아무튼 그렇네요. 홀홀.
다음글은 AAC에서 좋은 성능을 거둔 네트워크를 제안한 논문 몇가지를 소개해볼 계획입니다. 근데 음...제가 다음주가 기말고사라 빨라야 종강 이후에 올릴 수 있지 않을까 추측해봅니다.
AAC는 최근에 들어서야 많은 관심을 얻기 시작했기 때문에 많은 잠재력을 지니는 분야입니다. 아직은 Image Captioning 등 다른 task에서 잘 쓰이던 방식을 사용하는 것에 그치긴 하지만 조금만 시간이 지나면 AAC에서 제안된 방식이 다른 task에서 사용되는 날이 오지 않을까...요? 전 그렇게 믿고 싶습니다.
다음 글에서 뵙겠습니다.
