
머신러닝 입문: 미분, 손실함수, 경사하강법, 편미분 이해
머신러닝에서 모델을 학습시키기 위해서 필요한 핵심 개념
- 손실함수(Loss Function)
- 미분(Differentiation)
- 경사하강법(Gradient Descent)
이를 입문자의 입장에서 이해할 수 있도록 정리함.
1. 미분이란?
미분은 함수의 순간 변화율을 나타내는 도구임.
쉽게 말해, 함수가 특정 지점에서 얼마나 가파르게 변하는지를 수치화한 것임.
예시:
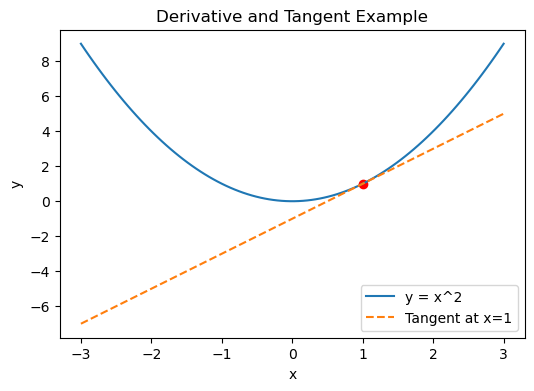
-
미분과 접선 예시
- 곡선과 에서의 접선을 보여주는 그래프임.
- 빨간 점은 접점, 주황색 선은 접선을 나타냄.
1.1 합성함수의 미분 (Chain Rule)
합성함수 ()는 속함수(inner function)와 겉함수(outer function)로 나누어 미분함.
예시:
- 겉함수: , 속함수:
- 속함수 미분:
- 겉함수 미분:
- Chain Rule 적용:
1.2 시그모이드 함수 미분 예시
시그모이드:
미분:
중요 포인트: 시그모이드는 출력값을 이용해서 간단히 미분 가능
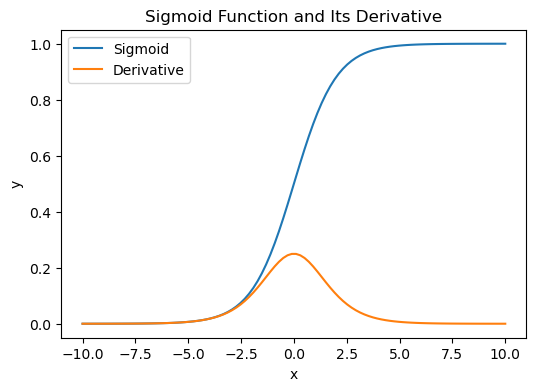
-
시그모이드 함수와 도함수
- 시그모이드 함수 와 그 도함수 를 나타낸 그래프
- 도함수는 시그모이드가 가장 가파른 구간에서 최대값을 가짐.
2. 손실 함수(Loss Function)
손실 함수는 모델의 예측이 실제값과 얼마나 차이 나는지 수치화하는 함수
-
손실 함수 값이 크면 실제값과 예측값의 차이가 크고, 값이 작으면 차이가 작다는 것을 의미한다.
-
따라서 손실 함수 값이 작을수록 더 좋은 모델이라고 이해할 수 있다.
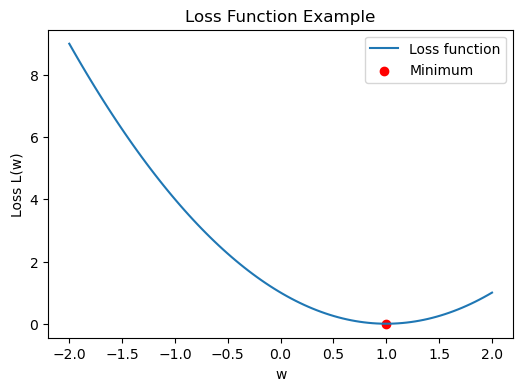
-
손실 함수 예제
- 손실 함수 L(w)의 그래프와 최소점을 표시한 예제
- 빨간 점은 손실이 최소가 되는 w 값으로, 최적화 목표를 나타냄.
-
대표적인 손실 함수의 종류: 평균제곱오차(Mean Squared Error, MSE)
- 각 데이터의 오차들의 제곱 합의 평균을 나타냄.
- 또 다른 손실 함수 종류로는 평균절대오차(Mean Absolute Erro, MAE), 교차 엔트로피 함수 (Cross-Entropy Function)가 있다.
-
왜 주로 제곱(평균제곱오차)을 쓰는가?
- 음수를 없애기 위해
- 큰 오차를 더 강조하여 학습에 용이
- 연속적이고 미분 가능하여 경사하강법에 적합
2.1 손실 함수의 의미와 시각화
- 손실 함수는 신경망 모델의 예측값과 실제값 간의 차이를 측정하는 함수
오차의 시각화
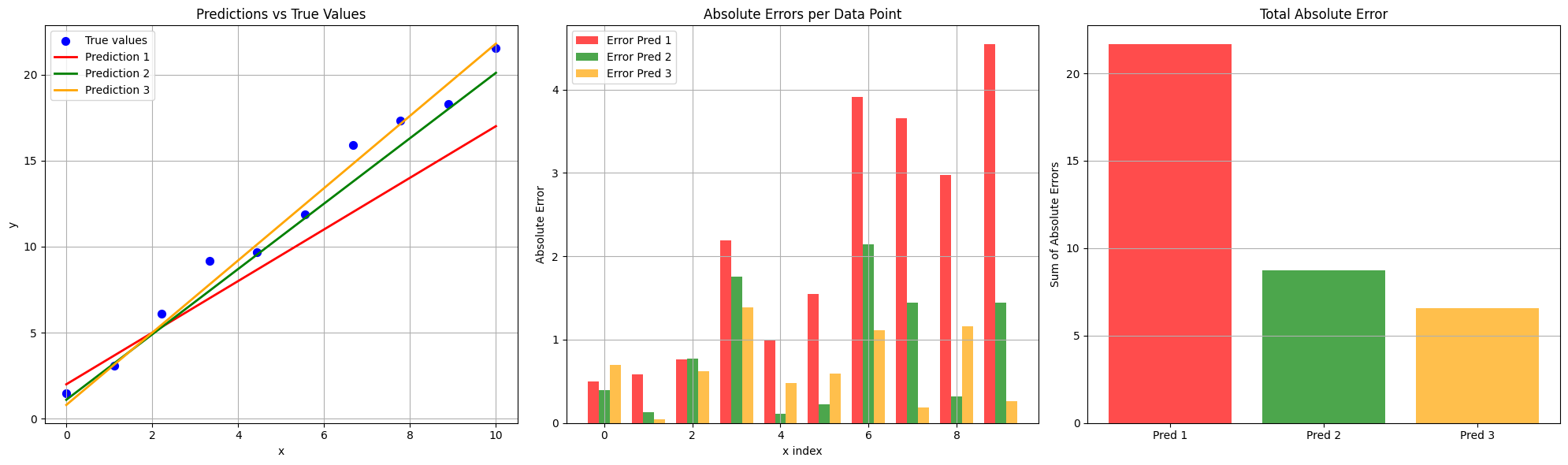
- 모델의 예측값과 실제값이 다를 때, 이 차이를 면적으로 표현 가능
- 예측값을 업데이트할수록 오차의 합(면적)이 줄어드는 것을 확인할 수 있음
신경망 학습의 목표
- 모든 파라미터()를 반복적으로 조금씩 튜닝(Tuning)
- 손실 함수의 값이 최소가 되도록 만드는 것이 학습의 핵심 목표
- 즉, 신경망 학습 = 손실 최소화 과정
2.2 손실 함수와 경사하강법
- 경사하강법은 손실 함수 를 미분하여 기울기를 계산하고, 이 기울기를 이용해 를 업데이트하는 최적화 방법임
- 따라서 경사하강법을 이해하려면 손실 함수의 정의와 변화를 정확히 아는 것이 필수임
3. 경사하강법(Gradient Descent)
주어진 손실함수에서 모델의 파라미터의 최적의 값을 찾는 머신러닝과 딥러닝의 최적화 알고리즘 중 하나
*경사하강법은 손실 함수의 값을 최소화하도록 파라미터 를 업데이트하는 방법임.
단계
-
손실 함수의 기울기 계산:
-
파라미터 업데이트:
(): 학습률(learning rate)
- 기울기가 양수면 를 줄이고, 음수면 를 늘려 손실을 감소
- 반복 수행하여 손실 최소화
3.1 손실과 의 관계
- 손실 함수 는 의 함수임.
- 를 조금씩 바꾸면 예측값 도 변하고, 따라서 손실 도 변함.
- 경사하강법은 이 관계를 활용하여 손실이 가장 낮은 지점을 찾는 방법임.
기계와 사람의 차이
- 사람의 눈은 오차가 최소인 지점을 직관적으로 알아볼 수 있음
- 하지만 기계는 손실 함수 값을 계산하고 기울기 정보를 이용해 최소점으로 이동해야 함
3.2 핵심 원리: 접선 기울기와 최소점
- 오차가 최소화되는 지점은 접선의 기울기(gradient)가 0이 됨)
- 즉, 이 되는 가 손실 최소점
- 경사하강법의 원리는 접선의 기울기가 0이 되는 지점(0에 수렴하는 지점)을 찾을 때까지, 기울기를 따라 점진적으로 이동하는 것임
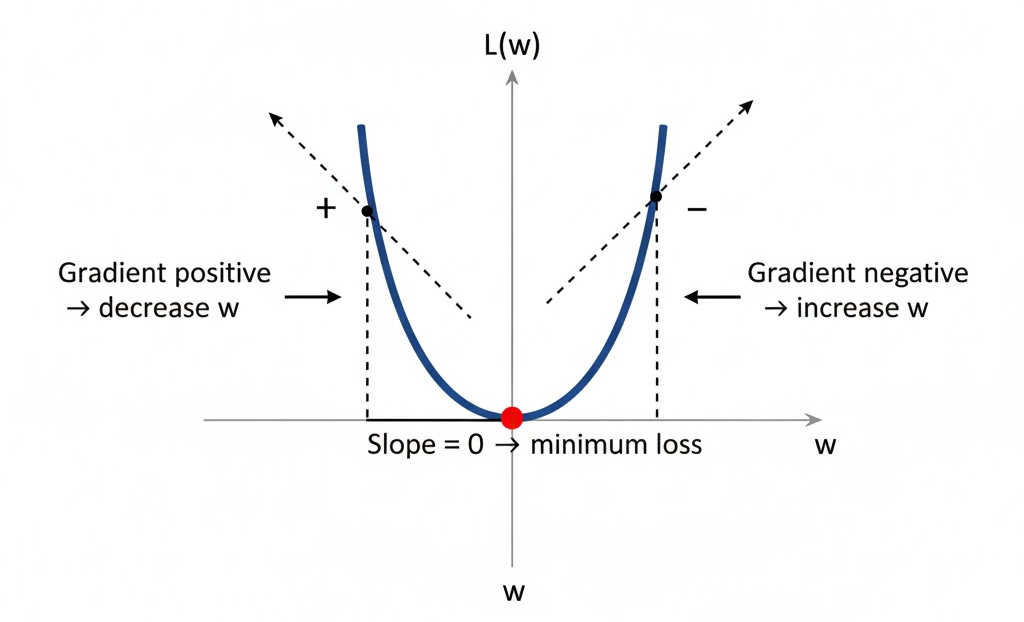
3.3 기울기와 파라미터 업데이트 원리
-
손실 함수가 직선이 아니더라도, 작은 변화량 와 를 이용해 기울기를 구할 수 있음:
-
기울기에 따라 값을 조정:
- 기울기(slope) > 0 → 를 감소시킴
- 기울기(slope) < 0 → 를 증가시킴
-
변화량은 기울기에 비례:
- 기울기가 크면 큰 변화량
- 기울기가 작으면 작은 변화량
- 점진적으로 기울기가 0에 수렴하는 를 찾아 손실 최소 지점으로 이동
4. 관련 기호 정리
| 기호 | 의미 | 설명 |
|---|---|---|
| 입력 데이터 (features) | 보통 행렬, 은 샘플 수, 는 특성 수 | |
| 실제값 (target) | 모델이 예측해야 하는 값 | |
| 예측값 | 모델이 현재 파라미터로 예측한 값 | |
| 또는 | 가중치(파라미터) | 모델이 학습하면서 조정하는 값, 손실 최소화 목적 |
| 편향(bias) | 선형 모델에서 y절편 역할 | |
| 손실 함수(loss function) | 모델 성능을 수치화, 에 따라 값이 달라짐 | |
| 손실 함수의 기울기 | 현재 에서 손실이 얼마나 증가/감소하는지 방향과 크기 | |
| 학습률(learning rate) | 한 스텝에 얼마나 이동할지 결정 |
5. 편미분과 기울기 (Gradient)
머신러닝에서 모델을 학습한다는 것은 손실 함수(loss function)를 최소화하는 과정을 의미함.
이때 손실을 줄이는 방향을 찾기 위해 사용하는 핵심 도구가 경사하강법(Gradient Descent)이며,
이 과정에서 필수적으로 사용되는 것이 바로 편미분(Partial Derivative)임.
5.1 다변수 함수와 편미분
다변수 함수는 여러 변수의 영향을 동시에 받는 함수임.
예를 들어,
는 두 변수 , 에 의해 값이 달라짐.
이때 한 변수만 변화시켜 변화율을 구하는 것이 편미분(Partial Derivative)임.
- 만 변화시키고 는 고정 →
- 만 변화시키고 는 고정 →
예시:
-
에 대한 편미분
-
에 대한 편미분
5.2 기울기 벡터 (Gradient Vector)
모든 변수에 대한 편미분을 모은 벡터를 기울기 벡터(Gradient Vector)라 함.
- 기울기는 함수가 가장 빠르게 증가하는 방향을 가리킴
- 반대로 는 가장 빠르게 감소하는 방향을 가리키므로, 경사하강법에서 이동 방향이 됨
5.3 경사하강법과 역전파 알고리즘
신경망(Neural Network)에는 수천~수만 개의 파라미터()가 존재함.
모델 학습 시 각 파라미터에 대해 손실 함수 을 편미분해야 함.
이 모든 편미분을 동시에 계산하는 과정이 역전파(Backpropagation) 알고리즘임.
즉, 딥러닝 학습은 손실 함수에 대한 모든 파라미터의 편미분을 계산하고, 이를 통해 손실을 줄이는 방향으로 이동하는 과정임.
*딥러닝 관련 학습 이후 추가로 정리가 필요함.
5.4 예제 문제
문제 1. 편미분 기본
함수
에 대하여,
를 구하시오.
풀이:
-
에 대해 미분할 때 는 상수로 취급
-
에 대해 미분할 때 는 상수로 취급
✅ 정답:
,
문제 2. 기울기 벡터 구하기
함수
에서 점 에서의 기울기 벡터 를 구하시오.
풀이:
-
각 변수에 대한 편미분 계산
-
대입
✅ 정답:
문제 3. 다변수 함수의 해석
함수
에 대하여,
를 구하시오.
풀이:
- 에 대한 편미분
- 에 대한 편미분
- 에 대한 편미분
✅ 정답:
핵심 정리
| 개념 | 수식 | 설명 |
|---|---|---|
| 편미분(Partial Derivative) | 한 변수만 변화시켜 변화율을 구함 | |
| 기울기(Gradient) | 함수의 모든 편미분을 모은 벡터 | |
| 경사하강법 방향 | 손실을 줄이는 방향 (함수의 감소 방향) | |
| 역전파(Backpropagation) | 모든 가중치 에 대해 계산 | 신경망 학습의 핵심 알고리즘 |
