
1. Sync vs Async
먼저 Synchronous와 Asynchronous의 어원을 살펴보자.
Syn 는 together라는 뜻이고 chrono는 time이라는 뜻이다.
즉, Synchronous는 함께 시간을 맞춘다라고 해석할 수 있을 것 같다.
반면에 Asynchronous는 접두사 A가 부정의 의미를 담고 있으므로 함께 시간을 맞추지 않는다 라고 해석할 수 있다.
그렇다면 과연 이들이 함께하는 대상이 무엇인지 그리고 대상들의 시간은 어떻게 다루어지는지 살펴보자.
Synchronous(동기)
동기는 두 가지 이상의 대상(함수, App 등)이 서로 시간을 맞추어 행동하는 것이다.
대상 A와 B가 있을 때 동기적으로 처리하는 방법은 아래와 같은 방법들이 있다.
 왼쪽의 방법은 A와 B의 시작 시간 또는 종료 시간이 일치하면 동기라고 할 수 있다. 예를 들면
왼쪽의 방법은 A와 B의 시작 시간 또는 종료 시간이 일치하면 동기라고 할 수 있다. 예를 들면
- A,B thread를 동시에 작업을 시작하는 경우
- method의 return시간과 해당 return 값을 전달받는 시간이 일치하는 경우가 있다.
오른쪽의 방법은 A가 끝나는 시간과 B가 시작하는 시간이 같으면 동기라고 할 수 있다.
즉, 동기는 어떠한 작업을 요청했을 때 작업의 결과가 나올 때까지 기다린 후 처리하는 방식이다.
Asynchronous(비동기)
비동기는 동기와는 반대로 대상이 서로 시간을 맞추지 않는 것을 의미한다.
예를 들면 호출하는 함수가 호출되는 함수에게 작업을 맡기고 결과에 대한 것은 신경을 쓰지 않는 것이다.
즉, 직전 시스템의 호출의 종료가 발생하면 그에 따른 처리를 진행하는 방식이다.
2. Blocking vs Non-blocking
블록킹/논블록킹은 동기/비동기와 되게 비슷한거 같다라는 생각이들 수 있지만, 사실 서로 관점이 다르다.
블록킹/논블록킹은 직접 제어할 수 없는 대상을 처리하는 방법에 따라 나눈다.
이때 직접 제어할 수 없는 대상이란 대표적으로 I/O처리, 멀티쓰레드 동기화 등이 있다.
Blocking
블록킹은 직접 제어할 수 없는 대상의 작업이 끝날 때까지 제어권을 넘겨주지 않는 것이다.
예를 들어 호출하는 함수가 I/O 처리를 요청했다고 하면, 해당 I/O 처리가 끝날 때까지 아무 일도 하지 못한 채 기다리는 것이다.
즉, 프로세스가 시스템을 호출하고 나서 결과가 반환되기까지 다음 처리로 넘어가지 않는다.
Non-blocking
논블록킹은 블록킹과는 반대되는 개념이다. 직접 제어할 수 없는 대상의 작업처리 여부와는 상관이 없다.
예를 들어 호출하는 함수가 I/O 처리를 요청한 후, I/O 처리의 완료 여부와는 상관없이 바로 자신의 작업을 처리할 수 있다.
즉, 시스템을 호출한 직후에 프로그램으로 제어가 다시 돌아가서 시스템의 호출의 종료를 기다리지 않고 다음 처리로 넘어갈 수 있다. 사실 논블로킹도 return을 받긴 하는데 return이 꼭 반환 값을 의미하는 것이 아닌 "나 아직 작업 다 못 끝냈어!!"라는 의미의 return을 반환하게 되는 것이다.
이부분에 대해서 나중에 예시 부분에서 다시 언급해보도록 하겠다.
3. Sync/Async, Blocking/Non-blocking 차이는?
위에서도 한 번 언급했지만 둘은 서로 관점이 다르다.
sync/async의 경우에는 두 가지 이상의 대상(메서드, 작업 등)과 이를 처리하는 시간으로 구분한다.
- synchronous: 호출된 함수의 리턴하는 시간과 결과를 반환하는 시간이 일치하는 경우
- asynchronous: 호출된 함수의 리턴하는 시간과 결과를 반환하는 시간이 불일치하는 경우
blocking/non-blocking의 경우에는 호출하는 대상이 직접 제어할 수 없는 경우 이를 구분할 수 있다.
- blocking: 직접 제어할 수 없는 대상의 작업이 끝날 때까지 기다려야하는 경우
- non-blocking: 직접 제어할 수 없는 대상의 작업이 완료되기 전에 제어권을 넘겨주는 경우
4. Sync/Async, Blocking/Non-blocking 예제
sync/async, blocking/non-blocking에 관련해서 구글링을 해보면 아래와 같은 그림을 많이 볼 수 있을 것이다.
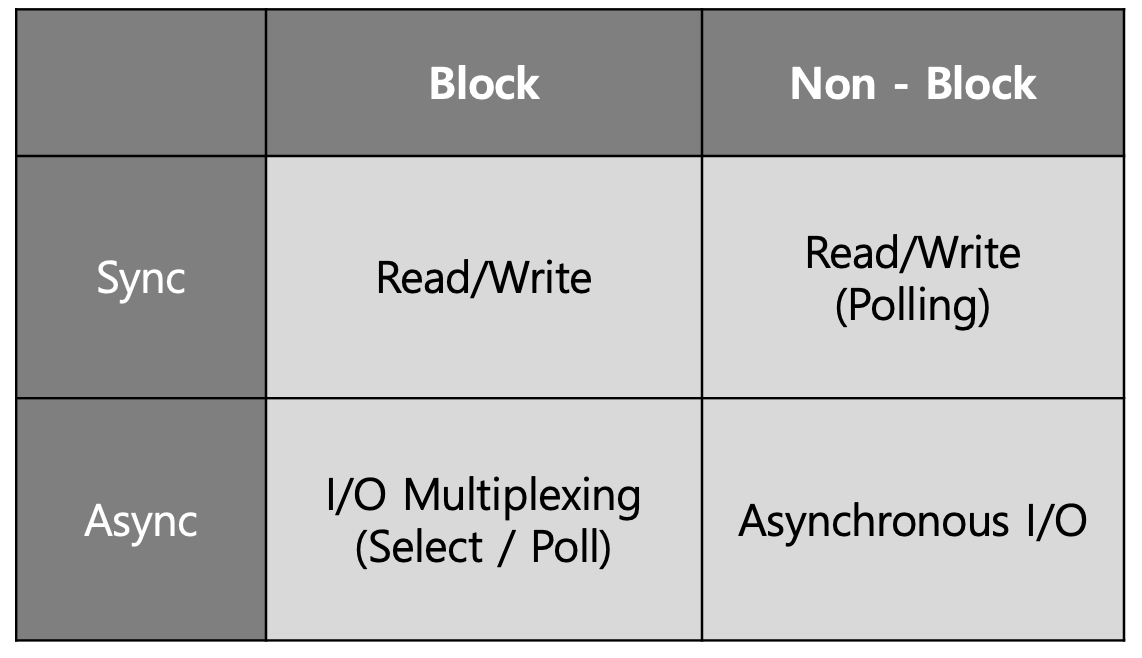 이 그림에서 4가지 경우들에 대해서 예시를 통해서 알아보도록 하자.
이 그림에서 4가지 경우들에 대해서 예시를 통해서 알아보도록 하자.
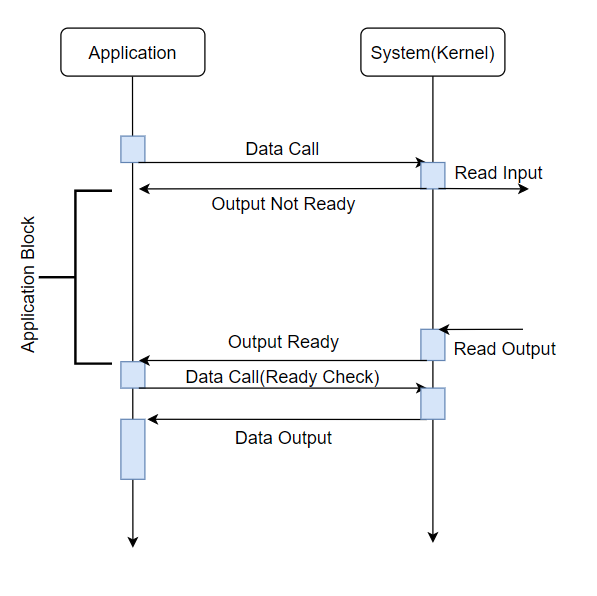
Synchronous blocking I/O
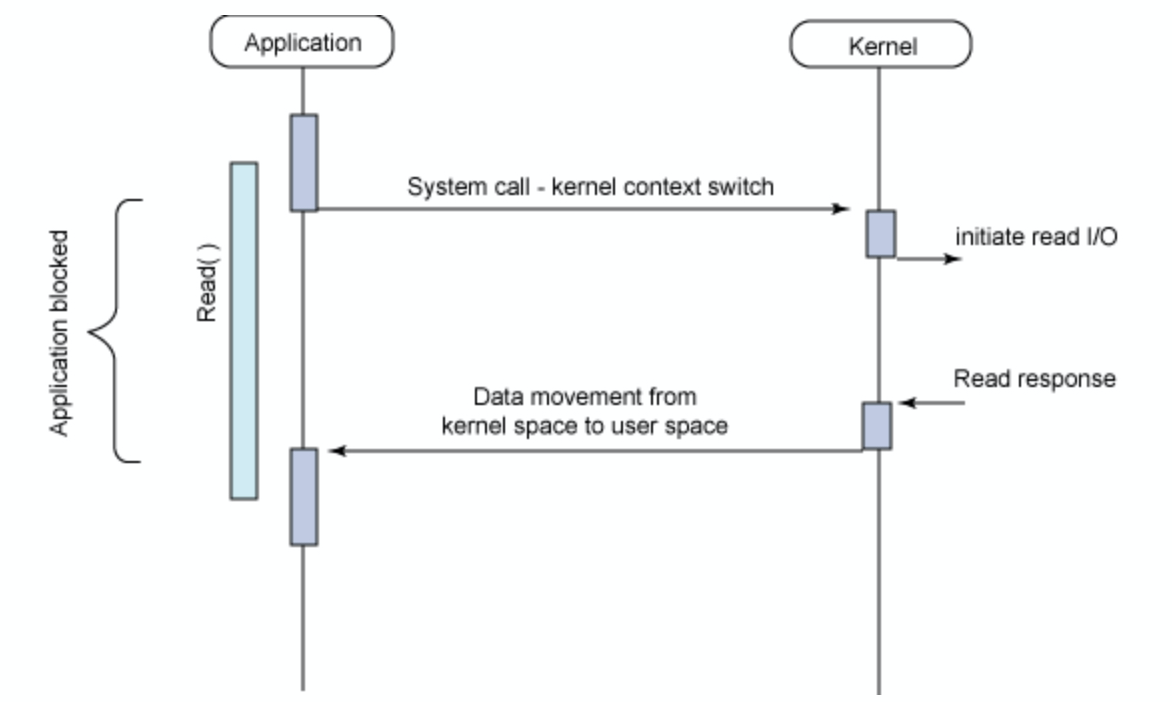
- synchronous: read()가 return하는 시간과 kernel에서 결과를 가져오는 시간이 일치한다.
- blocking: kernel에서의 작업이 완료될 때까지 대기한다.
즉, 그림에서 보면 Application Block이라고 나와있는데 해당 시간동안 다른 일을 하지 못하고 그냥 대기한다는 의미이다.
Synchronous non-blocking I/O
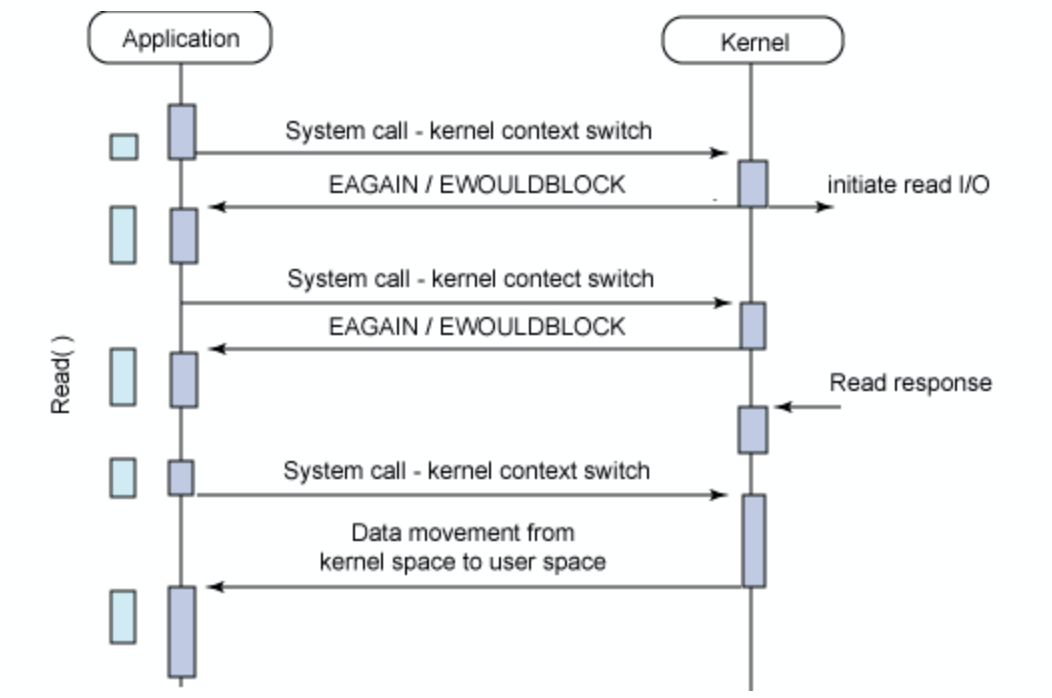 App에서 최초 데이터 요청 후 시스템에서 작업은 이어지고 시스템에서 Output이 준비되지 않은 상태를 App에 즉시 반환하기 때문에 blocking은 발생하지 않는다. 위의 non-blocking에서 잠시 언급했었던 return이 있긴 하지만 "나 아직 준비 안 됐어"라는 부분이 바로 이러한 경우이다.
App에서 최초 데이터 요청 후 시스템에서 작업은 이어지고 시스템에서 Output이 준비되지 않은 상태를 App에 즉시 반환하기 때문에 blocking은 발생하지 않는다. 위의 non-blocking에서 잠시 언급했었던 return이 있긴 하지만 "나 아직 준비 안 됐어"라는 부분이 바로 이러한 경우이다.
그러나 해당작업 이후 App에서는 시스템으로 지속적인 데이터 상태 체크를 하게된다. 시스템 버퍼에 데이터가 저장될 때까지 해당 작업을 지속한 후 시스템에서 데이터가 적재되면 그때 App 버퍼에 저장된 후 종료된다.
이렇게 지속적으로 상태를 체크하여 데이터를 받는 방식을 Polling 이라 한다.
Blocking에 대한 낭비는 없지만 반복적인 시스템 호출이 일어나게 되므로 context switch로 인한 CPU 자원이 낭비된다.
- synchronous: read()가 리턴하는 시간과 커널에서 결과를 가져오는 시간이 일치한다.
- non-blocking: 애플리케이션으로부터 요청을 받은 커널은 작업 완료 여부와 상관없이 바로 반환하여 제어권을 애플리케이션에게 넘겨준다. 커널의 작업이 완료되면 작업 결과를 애플리케이션에게 반환한다.
즉, 그림에서처럼 App의 blocking은 발생하지 않지만 중간 중간 계속 시스템으로 완료되었는지 확인을 하기 때문에 context switch로 인한 CPU 자원의 낭비가 발생한다.
Asynchronous non-blocking I/O (AIO)
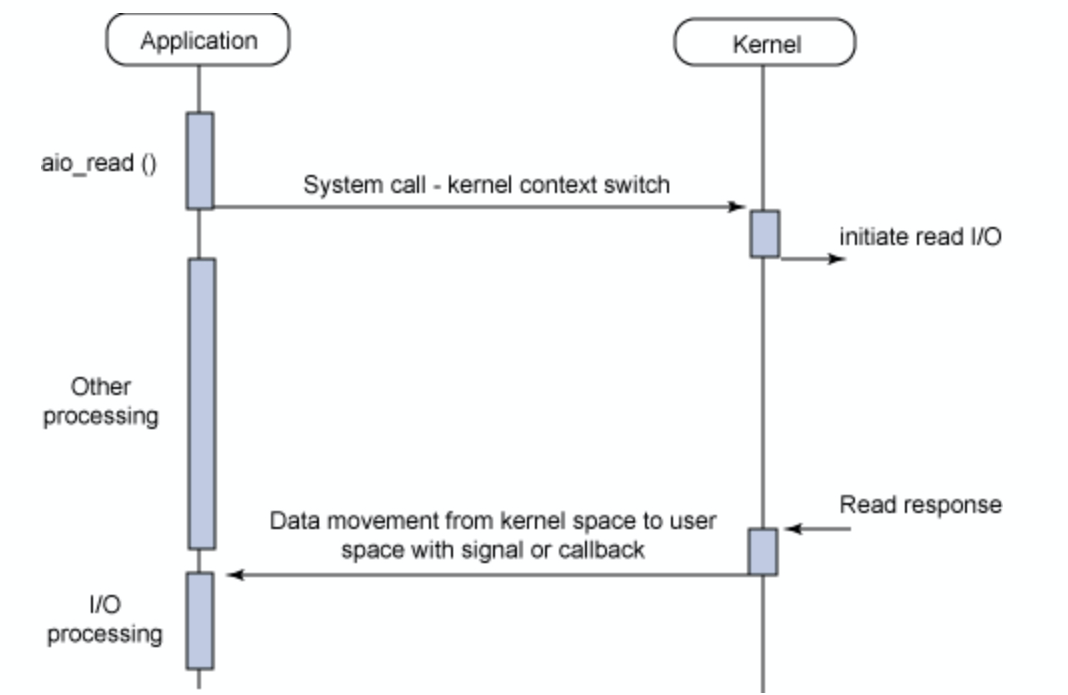 AIO (Asynchoronous I/O) 시스템 호출을 하면 버퍼의 포인터, 크기 및 완료 시 통지 방법 등을 시스템에 전달하고 즉시 리턴한다.
AIO (Asynchoronous I/O) 시스템 호출을 하면 버퍼의 포인터, 크기 및 완료 시 통지 방법 등을 시스템에 전달하고 즉시 리턴한다.
이 후 데이터가 버퍼에 복사되어 준비가 완료되면 App으로 신호를 발생하여 알려준다.
입력과 출력 사이의 Blocking이나 상태 체크가 없기 때문에 그 사이에 다른 프로세스를 진행할 수 있는 장점이 있다.
- asynchronous: read()가 return하는 시간과 kernel 에서 결과를 가져오는 시간이 불일치한다.
- non-blocking: App에서 요청을 받은 kernel에서의 작업의 완료 여부와는 관계없이 바로 App으로 제어권을 넘겨준다. 이후에 작업이 완료되면 시그널이나 callback을 통해 App에게 완료가 되었음을 알린다.
즉, 그림에서 read()작업을 요청하고 나서 other processing을 진행하다가 Read response가 오면 이후에 해당 I/O processing을 처리해주게 된다.
Asynchronous blocking I/O
 App에서 최초 데이터 요청 후 시스템에서 작업은 이어지고 시스템에서 Output이 준비되지 않은 상태를 App에 즉시 반환하며 App은 blocking 상태로 대기한다.
App에서 최초 데이터 요청 후 시스템에서 작업은 이어지고 시스템에서 Output이 준비되지 않은 상태를 App에 즉시 반환하며 App은 blocking 상태로 대기한다.
대기 상태에서 시스템에서 Output이 준비되었다는 신호를 주게되고 App에서 데이터 상태 체크 후 Output을 받아오게된다.
위의 조합은 비효율적이라 직접적으로 사용하는 모델은 없다고 한다.
하지만 Asynchronous Non-blocking 모델 중에서 blocking으로 동작하는 작업이 있는 경우 의도와는 다르게 Asynchronous blocking으로 작동하게 된다.
대표적인 예로는 Node.js와 MySQL을 사용하는 경우라고 한다. Node.js는 비동기로 작업하려하지만, MySQL 드라이버가 blocking 방식으로 동작하므로 Asynchronous blocking 방식으로 동작하게 된다.
참고
