개요
정렬 컬럼의 인덱스 사용 여부에 따라 다음 세 가지 쿼리의 성능, 실행 계획을 분석하였다.
- offset, limit 기반 페이징 쿼리 (인덱스 o, x)
- offset, limit, 커버링 인덱스 기반 페이징 쿼리 (인덱스 o, x)
- 커서 기반 페이징 쿼리 (인덱스 o, x)
테스트 환경
- 댓글 테이블, 데이터 200만 개
- 가장 오래 전 작성된 댓글 20개를 가져오도록 쿼리
- 댓글의 작성 시각이 랜덤하므로, 댓글 PK(auto increment)와 작성 시각이 비례하지 않음
- 작성 시각 컬럼에 대해 desc 인덱스를 생성함
1. offset, limit 기반 페이징 쿼리
SQL
select *
from comment_my FORCE INDEX (idx_created_at)
order by created_at desc
limit 1999980, 20;
select *
from comment_my IGNORE INDEX (idx_created_at)
order by created_at desc
limit 1999980, 20;결과
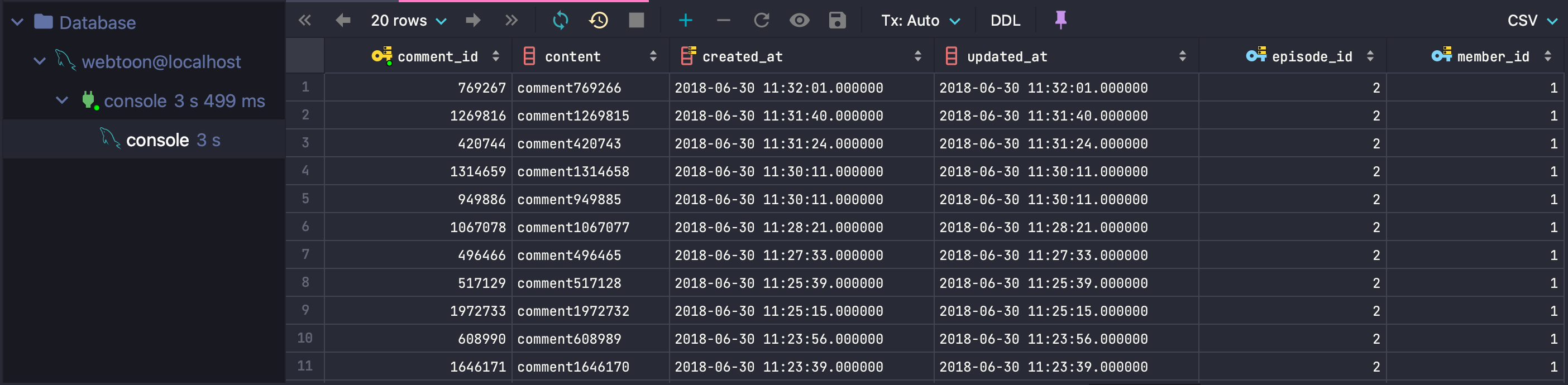
인덱스를 사용하는 경우 : 16.421s
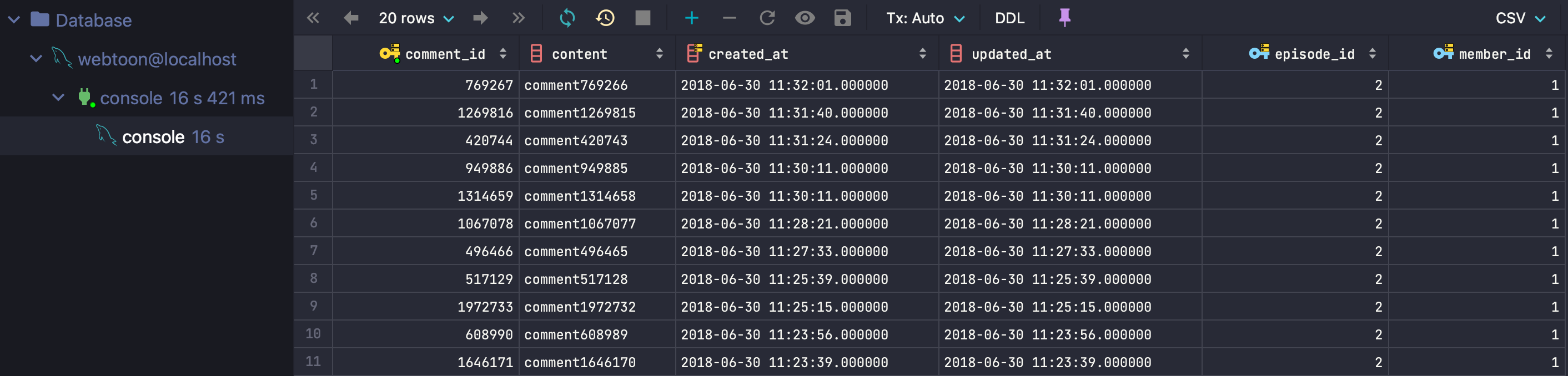


인덱스를 사용하지 않는 경우 : 3.499s


분석
오히려 인덱스를 사용했을 때가 사용하지 않았을 때보다 4.69배 느렸다.
인덱스를 사용하지 않았을 때, 실행 과정은 다음과 같다.
- ~ 약 1.19초: 테이블 스캔
- ~ 약 3.4초: 정렬
- ~ 약 3.5초: limit/offset
인덱스를 사용할 때, 실행 과정은 다음과 같다.
- ~ 약 15.9초: idx_created_at 인덱스 스캔
- ~ 약 16.1초: limit/offset
- idx_created_at이 desc로 걸려있으므로 추가 정렬이 필요하지 않음을 확인할 수 있다.
현재 상황에서 idx_created_at를 스캔하는 것보다 풀 테이블 스캔이 훨씬 더 빠르다는 것을 확인할 수 있었는데,
이는 순차 I/O인 테이블 스캔과 다르게 idx_created_at 기반 레코드 읽기 시 랜덤 I/O가 필요하기 때문이다.
앞서 설명하였듯 인덱스를 통해 데이터를 조회하는 것은 아래의 2가지 작업이 수행되는 것이다.
1. 인덱스를 통해 PK를 찾음
2. PK를 통해 레코드를 찾음이러한 이유로 옵티마이저는 인덱스를 통해 레코드 1건을 읽는 것이 테이블을 통해 직접 읽는 것 보다 4~5배 정도 비용이 더 많이 드는 것으로 예측한다. 하지만 DBMS는 우리가 원하는 레코드가 어디있는지 모르므로, 모든 테이블을 뒤져서 레코드를 찾아야한다. 이는 엄청난 디스크 읽기 작업이 필요하므로 상당히 느리다.하지만 인덱스를 사용한다면 인덱스를 통해 PK를 찾고, PK를 통해 레코드를 저장된 위치에서 바로 가져올 수 있으므로 디스크 읽기가 줄어들게 된다. 그렇기 때문에 레코드를 찾는 속도가 훨씬 빠르며, 이것이 인덱스를 사용하는 이유이다.
반면에 인덱스를 타지 않는 것이 효율적일 수도 있다. 인덱스를 통해 레코드 1건을 읽는 것이 4~5배 정도 비싸기 때문에, 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않는 것이 효율적이다. 이런 경우 옵티마이저는 인덱스를 이용하지 않고 테이블 전체를 읽어서 처리한다.
출처: [https://mangkyu.tistory.com/286](https://mangkyu.tistory.com/286) [MangKyu's Diary:티스토리]
실제로 limit 1999980, 20이 아닌 limit 100000, 20 과 같이 읽어야 하는 레코드 수가 적은 경우,
인덱스 사용한 쿼리 실행 시간이 1.140s, 인덱스를 사용하지 않은 쿼리 실행 시간이 2.686s로
인덱스를 사용하는 것이 성능상 좋다는 것을 확인할 수 있었다.
2. offset, limit, 커버링 인덱스 기반 페이징 쿼리
SQL
select *
from comment_my
join (select comment_id
from comment_my FORCE INDEX (idx_created_at)
order by created_at desc
limit 1999980, 20) as c on c.comment_id = comment_my.comment_id;
select *
from comment_my
join (select comment_id
from comment_my IGNORE INDEX (idx_created_at)
order by created_at desc
limit 1999980, 20) as c on c.comment_id = comment_my.comment_id;결과
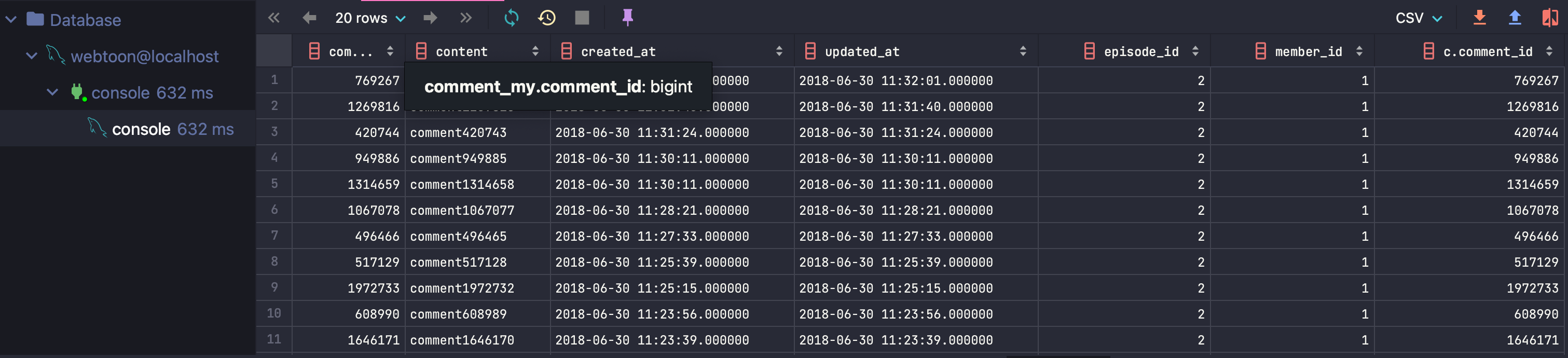
인덱스를 사용하는 경우: 0.632s


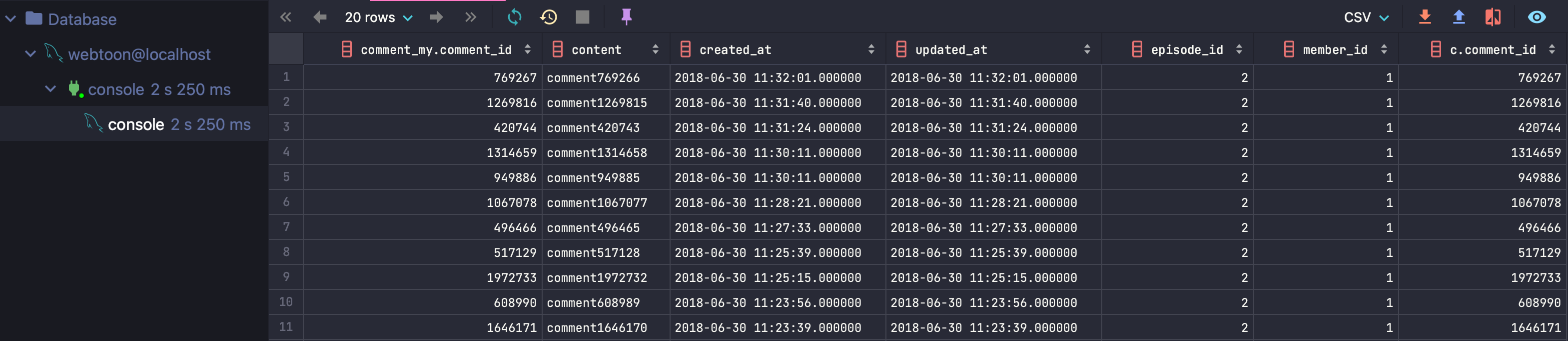
인덱스를 사용하지 않는 경우: 2.250s


분석
인덱스 사용 시 3.56배 빠름을 확인할 수 있었다.
인덱스를 사용하지 않았을 때, 실행 과정은 다음과 같다.
- ~ 약 0.9초: 테이블 스캔
- ~ 약 2.6초: 정렬
- ~ 약 2.7초: limit/offset, materialize, materialize로 만들어진 임시 테이블 스캔, pk 기반 eq_ref 조인
materialize: 서브 쿼리 내용을 임시 테이블로 구체화하는 것
서브 쿼리 사용 시 레코드마다 서브쿼리를 일일이 실행하는 대신, 임시 테이블 생성 후 조인하여 최적화하기 위해 고안됨인덱스를 사용할 때, 실행 과정은 다음과 같다.
- ~ 약 0.7초: idx_created_at 커버링 인덱스 스캔
- ~ 약 0.9초: limit/offset, materialize, materialize로 만들어진 임시 테이블 스캔, pk 기반 eq_ref 조인
idx_created_at 덕에 테이블 스캔 대신 인덱스 스캔을 진행하였고, 정렬이 필요하지 않아 약 2.6초가 걸리는 테이블 스캔과 정렬 처리 시간을 약 0.7초만에 처리함을 확인하였다.
3. 커서 기반 페이징 쿼리
SQL
select *
from comment_my FORCE INDEX (idx_created_at)
where (comment_id > 696659 and created_at = '2018-06-30 11:32:02.000000')
or created_at < '2018-06-30 11:32:02.000000'
order by created_at desc, comment_id;
select *
from comment_my IGNORE INDEX (idx_created_at)
where (comment_id > 696659 and created_at = '2018-06-30 11:32:02.000000')
or created_at < '2018-06-30 11:32:02.000000'
order by created_at desc, comment_id;결과
인덱스를 사용한 경우: 0.089s

-> Limit: 20 row(s)
(cost=2.78 rows=2) (actual time=0.0458..0.116 rows=20 loops=1)
-> Index range scan on comment_my using idx_created_at
over (created_at = '2018-06-30 11:32:02.000000'
AND 696659 < comment_id)
OR ('2018-06-30 11:32:02.000000' < created_at < NULL),
with index condition:
(((comment_my.created_at = TIMESTAMP'2018-06-30 11:32:02')
and (comment_my.comment_id > 696659))
or (comment_my.created_at < TIMESTAMP'2018-06-30 11:32:02'))
(cost=2.78 rows=2) (actual time=0.0451..0.113 rows=20 loops=1)인덱스를 사용하지 않는 경우: 1.313s

-> Limit: 20 row(s)
(cost=193494 rows=20) (actual time=1579..1579 rows=20 loops=1)
-> Sort: comment_my.created_at DESC, comment_my.comment_id,
limit input to 20 row(s) per chunk
(cost=193494 rows=1.88e+6) (actual time=1579..1579 rows=20 loops=1)
-> Filter:
(((comment_my.created_at = TIMESTAMP'2018-06-30 11:32:02')
and (comment_my.comment_id > 696659))
or (comment_my.created_at < TIMESTAMP'2018-06-30 11:32:02'))
(cost=193494 rows=1.88e+6) (actual time=138..1579 rows=20 loops=1)
-> Table scan on comment_my
(cost=193494 rows=1.88e+6) (actual time=0.064..1202 rows=2e+6 loops=1)분석
인덱스 사용 시 14.75배 빠름을 확인할 수 있었다.
인덱스를 사용하지 않았을 때, 실행 과정은 다음과 같다.
- ~ 약 1.2초: 테이블 스캔
- ~ 약 1.5초: where 조건 필터링, 정렬, limit
인덱스를 사용할 때, 실행 과정은 다음과 같다.
- ~ 약 0.0001초: where 조건 기반 idx_created_at 인덱스 레인지 스캔
- ~ 약 0.00012초: limit/offset
idx_created_at 덕에 테이블 스캔과 추가 정렬 대신 인덱스 레인지 스캔을 사용하여 약 1.5초가 걸리는 테이블 스캔과 정렬 처리 시간을 큰 폭으로 줄였음을 확인하였다.
결론
offset, limit 기반 페이징 쿼리
- 인덱스를 사용한 경우: 16.421초
- 인덱스를 사용하지 않은 경우: 3.499초
- 인덱스를 사용하지 않은 경우보다 사용한 경우가 4.69배 느림
인덱스를 사용하지 않는 경우, 테이블 스캔과 filesort 정렬이 발생하여 비효율적.
테이블 레코드 개수 중 10~20% 이상의 레코드를 읽어야 하는 경우, 인덱스 사용보다 풀 테이블 스캔이 더 빠르다는 것을 확인.
offset, limit 기반 페이징 쿼리를 사용하는 경우, 인덱스 풀 스캔이나 풀 테이블 스캔이 일어나므로 대용량 데이터 페이징에 적합하지 않음.
offset, limit, 커버링 인덱스 기반 페이징 쿼리
- 인덱스를 사용한 경우: 0.632초
- 인덱스를 사용하지 않은 경우: 2.250초
- 인덱스를 사용 시, 약 3.56배 속도 향상
인덱스를 사용하지 않는 경우, 테이블 스캔과 filesort 정렬이 발생하여 비효율적.
인덱스를 사용하는 경우, 커버링 인덱스 스캔 및 임시 테이블 조인을 사용하여 실행 속도가 향상되는 것을 확인.
인덱스 및 offset, limit, 커버링 인덱스 기반 페이징 쿼리를 사용하는 경우, 대용량 데이터 페이징 속도를 향상시킬 수 있음.
커서 기반 페이징 쿼리
- 인덱스를 사용한 경우: 0.089초
- 인덱스를 사용하지 않은 경우: 1.313초
- 인덱스 사용 시, 약 14.75배 속도 향상
인덱스를 사용하지 않는 경우, 테이블 스캔과 filesort 정렬이 발생하여 비효율적.
인덱스를 사용하는 경우, 인덱스 레인지 스캔을 사용하여 실행 속도가 향상되는 것을 확인.
인덱스 및 커서 기반 페이징 쿼리를 사용하는 경우, 대용량 데이터 페이징 속도를 크게 향상시킬 수 있음.


흠 .... 잘쓰셨네요