DecisionTree(12.12)
🔍DecisionTree(의사결정나무)
분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델이다. 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만든다.
결정 트리에서 질문이나 정답은 노드(Node)라고 부른다. 각 내부 노드는 특정 특징(feature)에 대한 조건을 테스트하고, 이에 따라 두 개 이상의 가지(branch) 중 하나로 나눈다.
- 분기 때마다 변수 영역을 두 개로 구분
- 이진트리의 개념
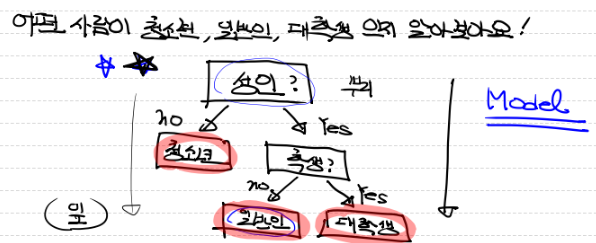
사람들이 일반적으로 의사결정 하는 방식과 유사
💻 의사결정나무 장•단점
장점
- 속도가 빠르고, 간단하다.
- 데이터에 따라 상대적으로 다른 model에 비해 성능이 좋다.
단점
- 독립변수가 이산 데이터인 경우 적합하다.
- class 수가 많은 경우 속도가 느리다.
- 데이터 수가 적으면 좋지 않음.
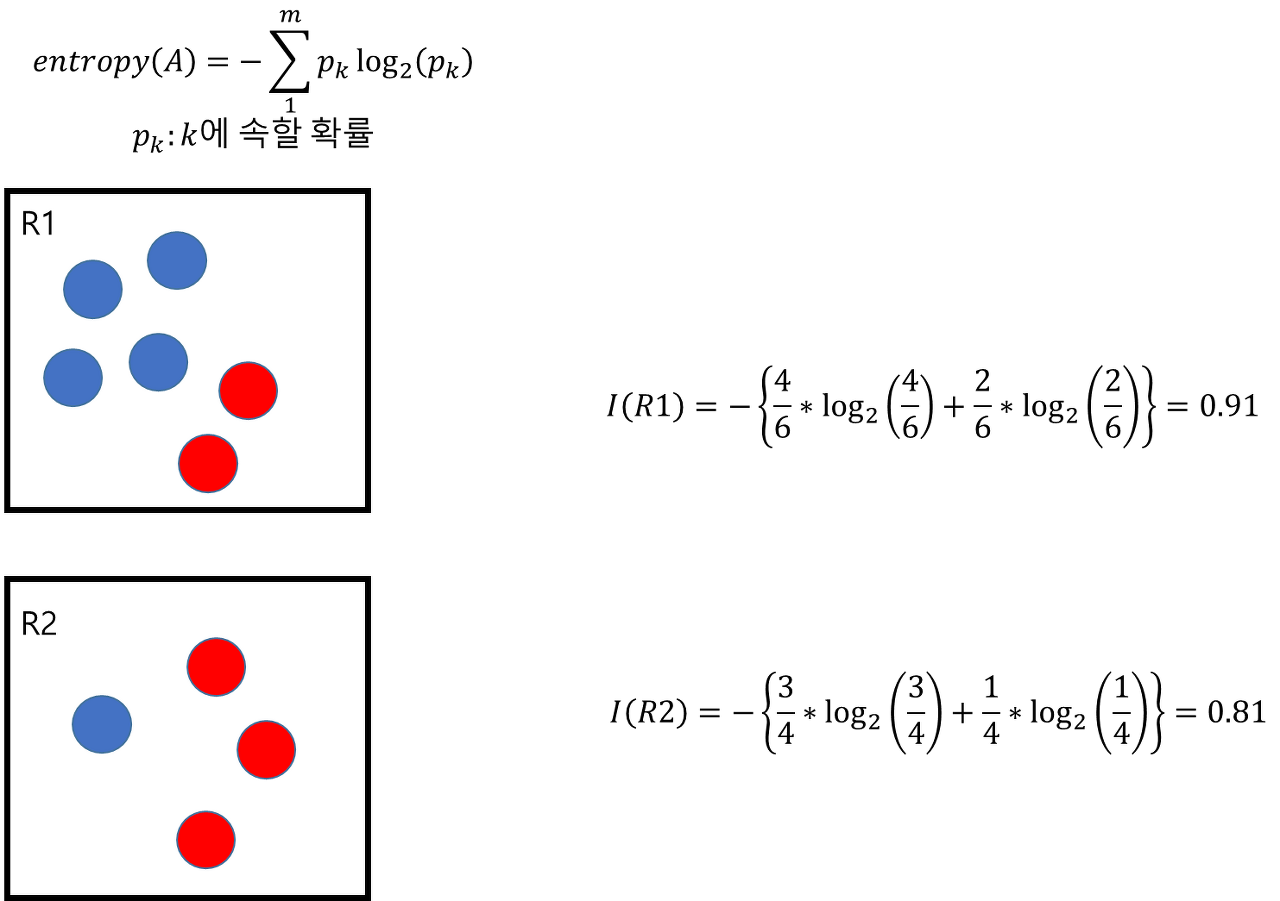
불순도(Impurity)
해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는가
- 다양한 개체가 섞여 있을수록 불순도가 높아짐
- 현재의 불순도에 비해 자식 노드의 불순도를 감소시켜야 함
- 현재 노드의 불순도 - 자식 노드의 불순도 = 정보획득량
정보획득량 (Information gain)
어떤 사건이 얼마만큼의 정보량을 줄 수 있는지 수치화 시킨 것
분기 이전의 불순도와 분기 이후의 불순도 차이
- 초기상태 불순도 1, 분기 후 0.3 ➡ 정복획득량 = 0.6
- 정보획득량 = 전체 entropy - 분기 후 entropy
- 정보획득량이 많은 방향으로 상태를 전이(= 분기)
❗Entropy가 낮은 방향으로, 정보획득량이 높은 방향으로 전개해야 함❗
<진행 방식>
1. Root 노드의 불순도 계산
2. 나머지 속성에 대해 분할 후 자식 노드의 불순도 계산
3. 각 속성에 대한 정보획득량 계산 후 정보획득량(Root노드와 자식 노드의 불순도 차이)이 최대가 되는 분기 조건을 찾아 분기
4.모든 leaf 노드의 불순도가 0이 될 때까지 2, 3을 반복 수행
Entropy(불확실성)
무질서도를 정량화시킨 값
정보획득량 최대화 ➡ 불순도 감소 ➡ 엔트로피 감소
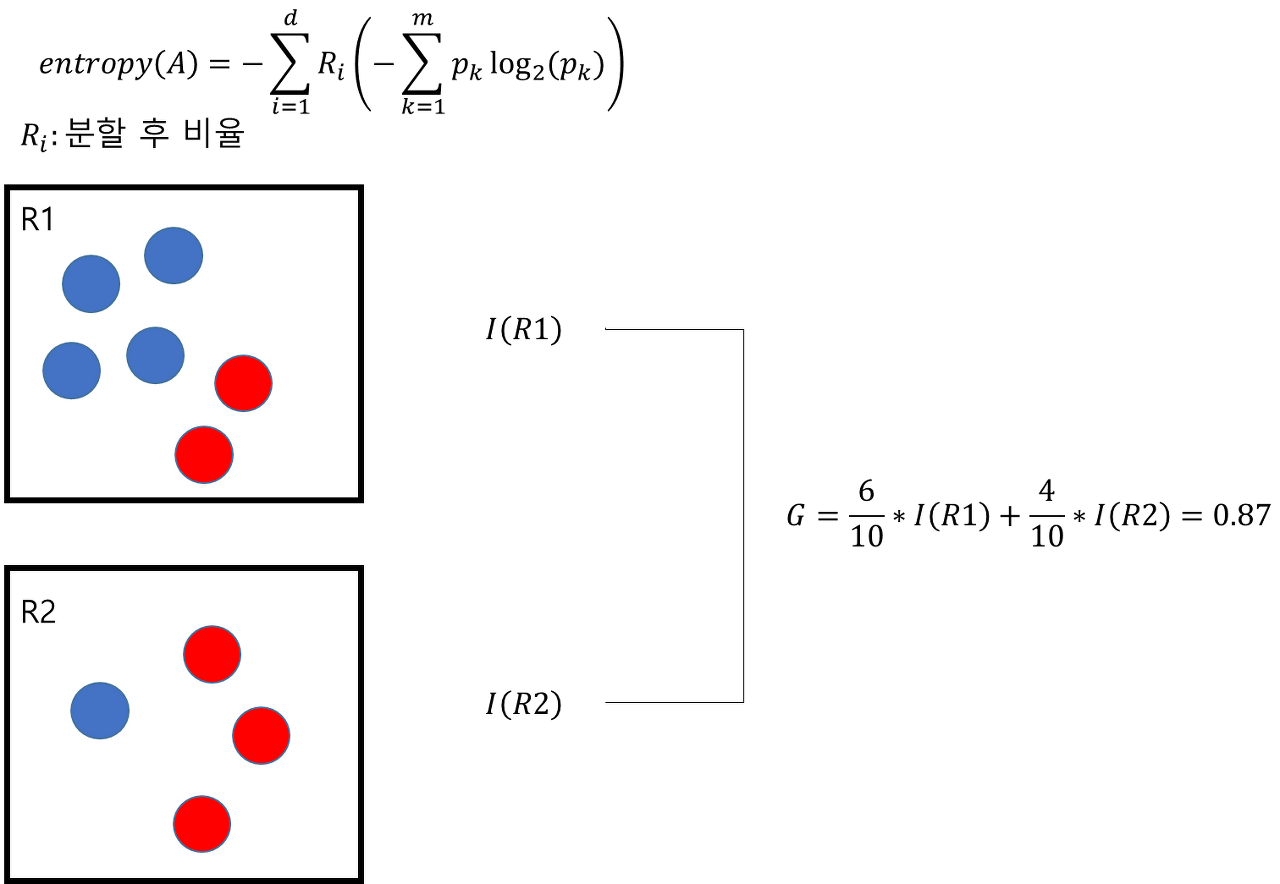
- entropy = 0 : 하나의 영역에 동일한 범주의 data만 존재 ➡ 불확실성 낮음
- entropy = 1 : 하나의 영역에 데이터가 반반씩 존재 ➡ 불확실성 높음 (특징을 찾기 어려움)
<A상태에서 B상태로 전이할 때>
(A) 불확실한 상황(=entropy가 높다) ➡ 정보량이 많음
(B) 불확실하지 않은 상황(=entropy가 낮음) ➡ 정보량이 적음
💡 전이되면서 정보량이 많아짐

🌳 최대의 정보획득량을 갖는 feature 구하기
🔍 구상
💻 코드 구현
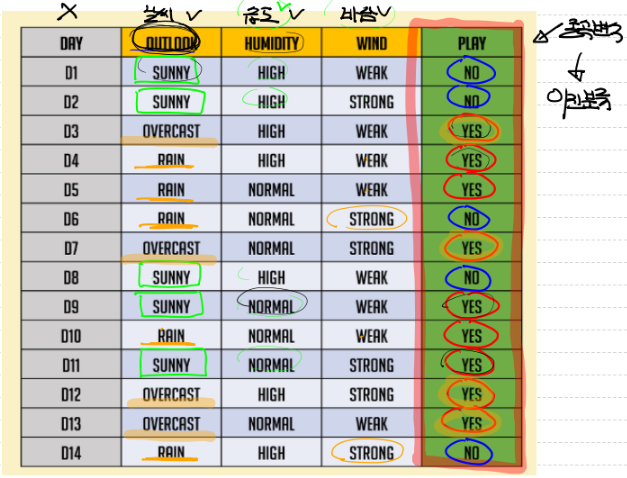
root node의 entropy 구하기
# 맨 처음 상태의 (root node)의 entropy 구하기
# 전체 데이터에 대한 entropy
import numpy as np
result = -((9/14) * np.log2(9/14) + (5/14) * np.log2(5/14)) # 종속변수 총 14개 (yes(9개), no(5개))
print(result)
# 0.9402859586706311전체 데이터를 Wind로 분류했을 때 entropy
# 전체 데이터를 Wind로 분류했을 때 entropy
# weak일 때 play(종속변수)가 yes인 경우, no인경우
# strong일 때 play(종속변수)가 yes인 경우, no인경우
result_wind_weak = 8/14 * (-6/8 * np.log2(6/8) - 2/8 * np.log2(2/8))
result_wind_strong = 6/14 * (-3/6 * np.log2(3/6) - 3/6 * np.log2(3/6))
result_wind = result_wind_weak + result_wind_strong
print(result_wind)
# 0.8921589282623617전체데이터를 습도(humidity)으로 분류했을 때 entropy
# 전체데이터를 humidity으로 분류했을 때 entropy
result_humid_high = 7/14 * (-3/7 * np.log2(3/7) - 4/7 * np.log2(4/7))
result_humid_normal = 7/14 * (-6/7 * np.log2(6/7) - 1/7 * np.log2(1/7))
result_humid = (result_humid_high + result_humid_normal)
print(result_humid)
# 0.7884504573082896전체 데이터를 outlook으로 분류했을 때 entropy
# 전체 데이터를 outlook으로 분류했을 때 entropy
result_outlook_sunny = 5/14 * (-2/5 * np.log2(2/5) - 3/5 * np.log2(3/5))
result_outlook_overcast = 4/14 * (-4/4 * np.log2(4/4))
result_outlook_rain = 5/14 * (-3/5 * np.log2(3/5) - 2/5 * np.log2(2/5))
result_outlook = (result_outlook_sunny + result_outlook_overcast + result_outlook_rain)
print(result_outlook)
# 0.6935361388961918전체 데이터를 outlook으로 분류했을 때 entropy
# 전체 데이터를 Wind로 분류했을 때 얻을 수 있는 정보획득량
print(result - result_wind) # 0.048
# 전체 데이터를 outlook으로 분류했을 때 얻을 수 있는 정보획득량
print(result - result_outlook) # 0.246
# 전체데이터를 습도(humidity)으로 분류했을 때 얻을 수 있는 정보획득량
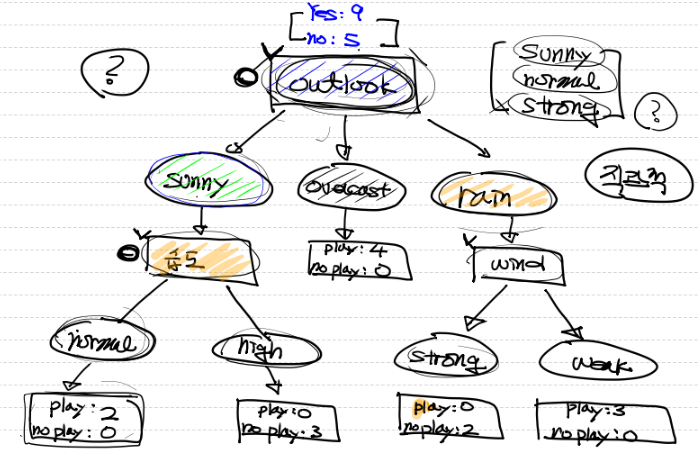
print(result - result_humid) # 0.151outlook으로 분류했을 때 얻을 수 있는 정보획득량이 가장 크다.
따라서 정보획득량이 가장 큰 outlook으로 분류하는게 좋음!!
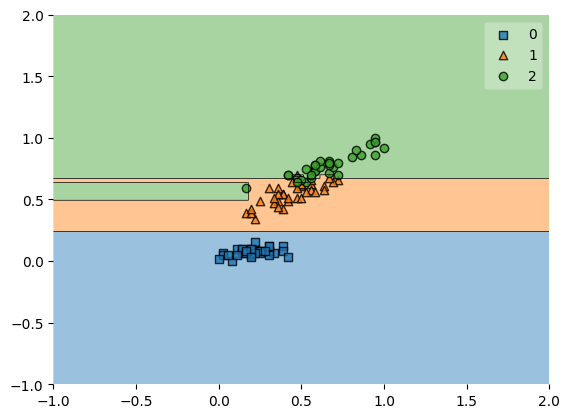
🌳 DecisionTree 모델 구현
데이터 처리
iris data 사용
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris # iris 데이터셋
from sklearn.preprocessing import MinMaxScaler # 정규화 모듈
from sklearn.model_selection import train_test_split # 데이터 분할
from sklearn.metrics import accuracy_score # 모델 정확도 평가용
from mlxtend.plotting import plot_decision_regions # 결정경계 그리기
from sklearn.tree import DecisionTreeClassifier # 사용할 모델: DecisionTreeClassifier
# Raw Data Loading
iris = load_iris()
# DataFrame으로 변환해서 처리하는게 쉽고 편함
df = pd.DataFrame(iris.data,
columns=iris.feature_names)
df.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
df['target'] = iris.target
# display(df)
# 결측치, 이상치, 중복데이터, 정규화 등등의 feature engineering과
# 데이터 전처리 진행
# 결측치와 이상치는 없다고 가정하고 진행!
# 중복데이터 처리
df = df.drop_duplicates()
# x_data와 t_data 추출
# x_data로 petal_length, sepal_length만 사용
x_data = df.drop(['target', 'sepal_width', 'petal_width'],
axis=1,
inplace=False).values
t_data = df['target'].values
# 정규화 진행
# 데이터 분할보다 정규화를 먼저 진행하는게 더 편함
scaler = MinMaxScaler()
scaler.fit(x_data)
x_data_norm = scaler.transform(x_data)
# train, test 데이터 분할
x_data_train_norm, x_data_test_norm, t_data_train, t_data_test = \
train_test_split(x_data_norm,
t_data,
test_size=0.3,
stratify=t_data,
random_state=0)모델 생성 및 평가
# 모델 생성
model = DecisionTreeClassifier()
model.fit(x_data_train_norm,
t_data_train)
# 평가
print(accuracy_score(t_data_test,
model.predict(x_data_test_norm)))
# 0.9333333333333333
# 시각화
plot_decision_regions(X=x_data_train_norm,
y=t_data_train,
clf=model)