기존에 진행하던 프로젝트의 성능을 조금 높힐만한게 뭐가 있을까 하다가 가장 많이 접했던 인덱스를 검색에 적용해 보기로 결심하게 되었습니다. 그런데 인덱스를 기본적인 내용만 알고 적용해본적이 없어서 이번 기회에 공부해보고 학습한 내용을 정리해 보자는 생각으로 포스팅 하게 되었습니다.
공부를 위한 게시물로 잘못된 내용이 있을수 있습니다. 태클은 언제나 감사합니다!
인덱스란?
인덱스는 결국 정렬이라고 할수 있습니다. 인덱스 == 정렬
우리는 책에서 특정 단어나 내용을 찾기 위해 색인(인덱스)를 찾아보곤 합니다. 데이터베이스의 인덱스도 비슷한 맥락의 기능입니다. 테이블에서 특정한 내용을 빠르게 찾기 위한 기능으로 일종의 색인을 생성하는 것입니다.
인덱스의 동작
- '인덱스'를 특정 컬럼에 추가해 주면 해당 컬럼을 기준으로 정렬된 정렬 테이블이 생성되는 원리라고 합니다.
- 그래서 인덱스는 주로 select 쿼리의 성능을 향상시킬 때 사용한다고 합니다.
- 다만 insert, update, delete 쿼리의 성능은 저하 되는데 만약 1~30까지의 인덱스중 25번 데이터를 테이블에서 delete 하게 된다면 인덱스 역시 25번 데이터가 지워지게 됩니다. 그렇게 되면 26~30은 비워진 25번을 채우기 위해 -1 씩 적용되게 되어 성능상 저하를 가져오게 되고 insert, update역시 같은 맥락이라고 합니다. => 결론은 인덱스 정렬에 변화를 주는 동작 자체가 성능저하와 연관되있습니다.
- 여기서 주의할 부분은 update, delete 행위가 느린거지 update,delete 하기 위해 해당 데이터를 조회 하는 것은 인덱스가 있으면 빠르게 조회가 됩니다.
- 인덱스의 기본 구조는 여러가지 전략이 있는데 디폴트는 B-Tree 구조를 가진다고 합니다. (이부분은 추가적인 db공부가 더 필요하다고 판단됩니다.)
인덱스 컬럼 설정에 대한 기준
- 인덱스는 흔히 '카디널리티가 높은 컬럼'을 기준으로 잡는다고 합니다.
- 카디널리티는 쉽게 말해 유니크율? 같은 뜻이고 카디널리티가 높다는건 해당 컬럼내의 중복되는 내용이 그만큼 적다라는 의미입니다. 예를들어 주민번호와 성함의 경우 성함 역시 많은 종류가 있겠지만 동명이인이 있어 중복되는 내용이 있기마련 입니다. 이에반해 주민번호는 모두 고유한 번호가 있기에 서로 달라 중복되는 내용이 거의 없고 결과적으로 주민번호가 성함보다 카디널리티가 더 높다고 할 수 있습니다.
- 카디널리티가 낮은 컬럼을 인덱스로 잡게 되면 검색시 인덱스를 읽고 나서 다시 많은 데이터를 조회해야 하기 때문에 성능저하가 발생한다고 합니다.
- 만약 여러 컬럼을 하나의 인덱스로 하는 복합인덱스를 만든다면 컬럼 순서를 카디널리티가 높은 순서로 구성하는게 효율적이라고 합니다. => 아마도 조회하는 데이터를 좁히는 과정에서 속도의 차이가 난다고 생각합니다. => 추후 공부해보니 추측이 맞았습니다.학생 100명이 있고 남50 여50의 상황에서 1) 성별과 이름 순으로 복합인덱스가 구성된경우 => 100명중 성별로 검사해 50건을 걸러내고 50건중에서 이름으로 걸러내 총 100 + 50 건 검색
2) 이름과 성별 순으로 복합인덱스가 구성된경우 => 100명중 이름으로 검사해 98건을 걸러내고 2건중 성별로 걸러내 총 100 + 2 건 검색
인덱스 적용
mysql 실습용 데이터를 통해 간단하게 인덱스의 효율에 대해 먼저 보고 진행하겠습니다.
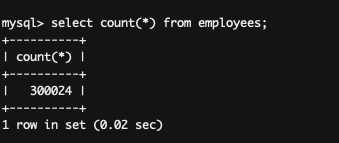
- 많은 수는 아니지만.. employees의 데이터는 30만건 정도 됩니다.
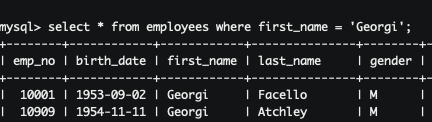
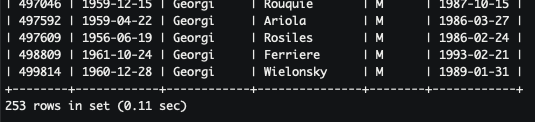
- 인덱스 없이 이름이 'Georgi'라는 직원을 검색해 0.11초가 걸렸는데 실무에선 데이터가 3,4배 많으면 10배도 넘기 때문에 조금 오래걸렸다고 할수 있을것 같습니다.
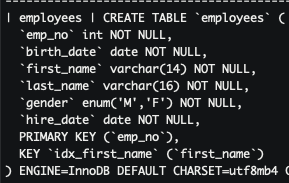
- first_name(이름) 컬럼에 인덱스를 추가하고 다시 조회 해보겠습니다.

- 이번에는 인덱스를 적용후의 결과입니다. 속도가 훨씬 빨라졌습니다. 데이터가 많으면 많을수록 둘의 차이는 더 커질것 같습니다.
마치며
- 원래 프로젝트에 적용한 부분도 추가하려고 했는데 데이터가 많이 없어 인덱스 추가후의 차이가 너무 미미했다.. 이부분은 데이터 추가후 확인할 예정.
- 역시 하나의 기능은 여려 부분과 연관되어있다고 느끼고 db 공부를 조금더 딥하게 하고 싶은 생각이 들었다.
- 부족한 부분이 많지만 조급해하지 말고 꾸준히 할 생각이다
