Goal
- Feature Engineering 의 목적을 이해 할 수 있다.
- pandas를 통해 문자열(string)을 다룰 수 있다.
- 데이터프레임에
.apply()를 사용하여 행을 수정하거나 새로 작업 할 수 있다.
Feature Engineering
is a process of extracting useful features from raw data using math, statistics and domain knowledge.
purpose
통계 분석 혹은 머신러닝, 더 나아가 딥러닝까지 대부분의 분석은
데이터에 있는 패턴을 인식하고, 해당 패턴들을 바탕으로 예측을 하기 때문에,
더 좋은 퍼포먼스를 위하여 더 새롭고, 더 의미있는 패턴을 제공하는 것
- one-hot encoding
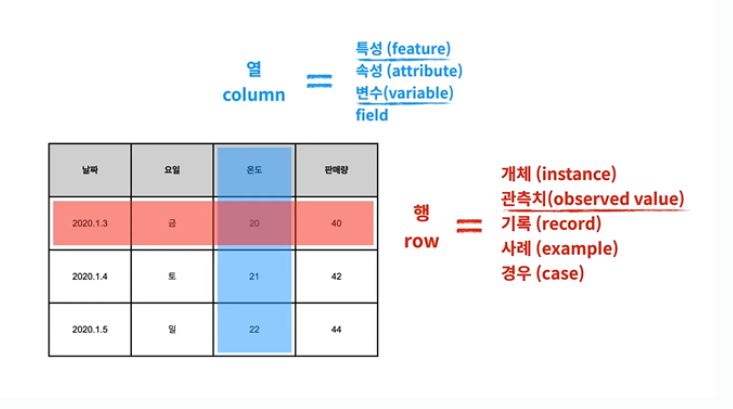
Data Frame(tidy 형태)
None
- reference
https://daje0601.tistory.com/53
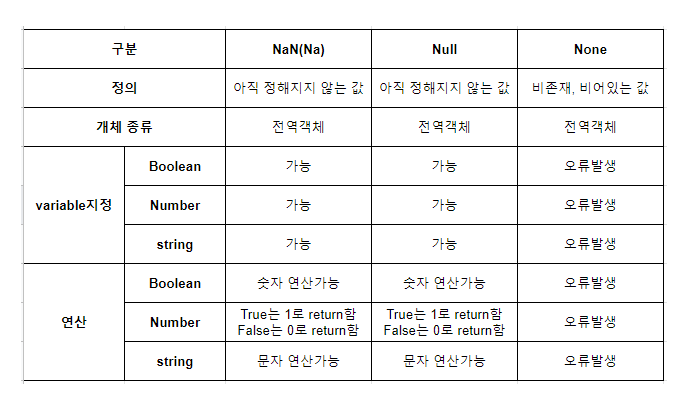
Na : Not availabe
Null : 아무것도 존재하지 않음이 할당되어 있는 상태
NaN : Not a Number _ pandas에서 결측치를 표현하는 방법
0 : Null, NaN, Na 등의 대체 수치로도 많이 사용되고, False의 역할도 하는 필요한 존재ㅎㅎ,,
undefined : 변수가 선언되었으나 아무것도 할당 되지 않은 상태
python에서는 Na, Null, NaN이 비슷한 의미로 결측치를 표현할때 사용
String
Replace
- 숫자가 아닌 부분을 제거
- 문자를 숫자로 형변환
string variable.replace('character want to change','replace character')
s = 25,970
s = s.repalce(',','') #25970 , method이므로 할당 다시 해줄것!Type Casting(형변환)
int() # to inteager
float() # to float
str() # to string
# 함수로도 작성 가능Apply
column 단위로 대체하고 싶을때 사용
- apply 안에 적용시킬 함수 선언
- column에 apply 적용
dataFrame['column name'].apply(func), 제거하기
- list comprehenshion
- reference
https://www.notion.so/Note-2-Feature-Engineering-e794e210d8894b29861a6635147c14c7#1bf6fd8ba8824cf5817851d26ef0b5c4
int("".join([x for x in 변수.split(',')]))- 자리수 구분 없이 csv 불러오기
pd.read_csv(thousands=',')- split을 이용한 다른 방법
#QUiz
tmp = "12,578"
a,b = tmp.split(",")
revenue_19_2 = int(a+b)pd.read_csv()
- reference
pandas.read_csv - pandas 1.3.2 documentation
[Pandas] pd.read_csv & pd.to_csv :: csv파일 불러오기 & 내보내기, 저장하기
pd.read_csv('파일명.csv', names = [], header=0, index_col = '인덱스로 지정할 column명')
names = [] #열 이름 지정, header의 역할 까지 함
header # column명으로 지정할 index
index_col = '인덱스로 지정할 column명'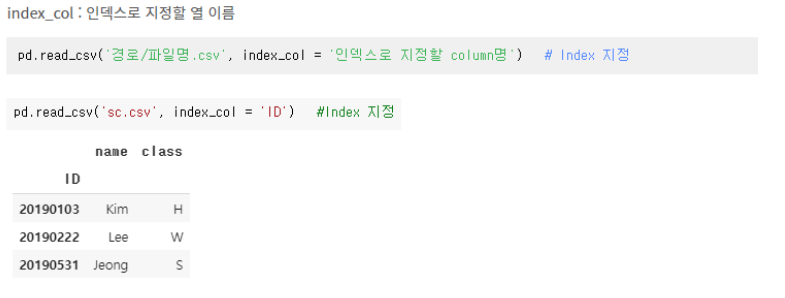
lambda
- reference
https://wikidocs.net/64
Have to study

Always, Better than.