CPU가 하나의 프로세스 작업이 끝나면 다음 프로세스 작업을 수행해야 한다. 이때 다음 프로세스가 어느 프로세스인지를 선택하는 알고리즘을 CPU Scheduling 알고리즘이라고 한다.
1. Preemptive VS Non-preemptive
1.1. Preemptive
Preemptive(선점)은 프로세스가 CPU를 점유하고 있는 동안 I/O나 인터럽트가 발생한 것도 아니고 모든 작업을 끝내지도 않았는데, 다른 프로세스가 해당 CPU를 강제로 점유 할 수 있다. 즉, 프로세스가 정상적으로 수행중인 가운데 다른 프로세스가 CPU를 강제로 점유하여 실행할 수 있는 것이다.
1.2. Non-preemptive
Non-preemptive(비선점)은 말 그대로 Preemptive 반대이다. 한 프로세스가 한 번 CPU를 점유했다면, I/O(프로세스 상태가 실행 -> 대기로 변경되는 경우) 또는 프로세스가 종료될 때까지 다른 프로세스가 CPU를 점유하지 못하는 것이다.
2. Scheduling criteria
Scheduling criteria(척도)는 스케줄링의 효율을 분석하는 기준들이다.
- CPU 이용률(CPU Utilization, %): CPU가 수행되는 비율
- Throughput(처리율, jobs/sec): 단위시간당 처리하는 작업의 수(처리량)
- 반환시간(Turnaround time): 프로세스의 처음 시작 시간부터 모든 작업을 끝내고 종료하는데 걸린 시간이다.(CPU, waiting, I/O 등 모든 시간을 포함한다.) 반환시간은 짧을 수록 좋다.
- 대기시간(Waiting time): CPU를 점유하기 위해서 ready queue에서 기다린 시간을 말한다.(다른 큐에서 대기한 시간은 제외한다.)
- 응답시간(Response time): 일반적으로 대화형 시스템에서 입력에 대한 반응 시간을 말한다.
높을수록 좋은 척도
CPU 이용률, 처리율
낮을수록 좋은 척도
반환시간, 대기시간, 응답시간
3. CPU Scheduling Algorithms
3.1. First-Come, First-Served(FCFS)
FCFS는 레디큐에 먼저 도착한 프로세스 순서대로 CPU를 점유하는 방식이다. 이는 매우 단순하고 많이 사용하는 방법이지만, 모든 부분에서 효율적인 것은 아니다.
Gantt Chart
| Process | Burst Time(msec) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |

첫 번째 표는 3개의 프로세스와 각 프로세스가 CPU를 사용한 시간(burst time)을 나타낸다. 이를 간트 차트로 표현하면 표 아래의 그림과 같다.(도착시간은 모두 0초라고 가정한다.) 평균 대기시간을 계산하면 아래와 같다.
만약, 프로세스가 들어온 순서가 P3, P2, P1면 간트 차트는 아래 그림과 같이 바뀔 것이다.

두 예제에서 모든 프로세스가 끝난 시간은 30msec로 같지만, 평균 대기시간으로 봤을 때는 위의 예제는 17msec이고 아래는 3msec로 차이가 난다. 즉, 들어온 순서로 수행한다고 해도 반드시 효율적인 것은 아니다.
위 예제처럼 P1, P2, P3 순서로 들어온 것을 Convoy Effect 라고 한다. 이는 CPU 시간을 오래 사용하는 프로세스가 먼저 수행하는 동안 나머지 프로세스들은 그 만큼 오래 기다리는 것을 말한다. P1이 수행되는 동안 P2, P3는 오래 기다려야 하는 예제에서 이를 볼 수 있다. 이는 FCFS의 단점 중 하나이다. 그리고 FCFS는 Non-preemptive이다. 하나의 프로세스가 끝나기 전에는 다른 프로세스가 중간에 끼어들 수 없다.
3.2. Shortest-Job-First(SJF)
SJF는 이름에서도 나타나듯이 가장 짧게 수행되는 프로세스가 가장 먼저 수행되는 것을 말한다. FCFS에서 보았듯이 수행 시간이 짧은 프로세스가 먼저 오는 것이 평균 대기시간이 짧은 것을 알 수 있었다. 이를 이용한 것이 SJF이다.
Gantt Chart
| Process | Burst Time(msec) |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |

위 간트 차트는 SJF를 사용하여 나타낸 것이다. 여기서 평균 대기시간을 계산하면 다음과 같다.
위 표를 FCFS를 사용해서 간트 차트를 나타내보자.
SJF와 FCFS의 평균 대기시간을 살펴보면 SJF가 더 짧은 것을 볼 수 있다. SJF가 평균 대기시간 기준으로 어떠한 방법보다 짧은 것은 이미 수학적으로 증명되어 있다. 그러므로 어떠한 예제를 보더라도 SJF가 Average Waiting Time은 가장 짧다.
이를 보면 SJF가 가장 효율적인 CPU 스케줄링 방법으로 이를 쓰면 될 것 같지만, 사실은 이 스케줄링 방법은 매우 비현실적이다. 왜냐하면 현실적인 컴퓨터 환경에서는 프로세스의 CPU 점유 시간(burst time)을 알 수 없다. 왜냐하면 한 프로세스가 실행 중에는 많은 변수가 존재하기 때문에 CPU 점유 시간을 알려면 실제로 수행하여 측정하는 수 밖에 없다. 실제 측정한 시간으로 예측해서 SJF를 사용할 수도 있지만, 이는 오버헤드가 매우 큰 작업으로 잘 사용되지 않는다.
SJF는 preemptive와 non-preemptive 둘 다 사용가능하다. 먼저, 아래의 표를 보자.
| Process | Arrival Time | Burst Time(msec) |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |
기존의 예제와 달리 도착시간(arrival time)이 추가되었다. 첫 번째로 non-preemptive의 간트 차트를 보자.
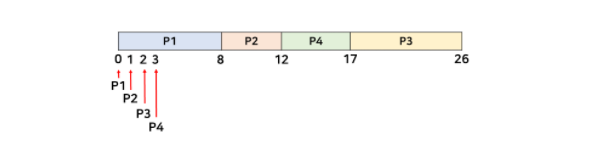
가장 먼저 도착한 P1이 수행되는 동안 P2, P3, P4 모두 도착하지만, non-preemptive이므로 이미 수행중인 프로세스가 끝날 때까지 기다려야 한다.
두 번째는 preemptive SJF를 살펴보자.

이번에는 preemptive이므로 프로세스가 도착할 때마다, 어느 프로세스가 가장 짧은 것인지 선택해야 한다. 주목할 점은 P2 프로세스가 도착했을 때, 현재 남은 burst time 중 가장 짧은 프로세스가 P2이므로 P1을 수행하던 것을 멈추고 P2가 수행을 시작한다.
Preemptive SJF는 예제에서 살펴보았듯이 현재 남아있는 시간 중 가장 짧은 프로세스를 선택하므로 Shortest-Remaining-Time-First(최소잔여시간 우선) 이라 불리기도 한다.
3.3. Priority
Priority 스케줄링은 말그대로 우선순위가 높은 프로세스가 먼저 선택되는 스케줄링 알고리즘이다. 운영체제에서 일반적으로 우선순위는 정수값으로 나타내며, 작은 값이 우선순위가 높다.(Unix/Linux 기준)
Gantt Chart
| Process | Burst Time(msec) | Priority |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |

표에서 우선순위 값이 가장 낮은 순서대로 수행한 모습을 간트 차트로 나타내었다.
우선순위를 정하는 방법은 크게 내부적인 요소와 외부적인 요소 두 가지로 나뉜다.
- Internal: time limit, memory requirement, I/O to CPU burst(I/O작업은 길고, CPU 작업은 짧은 프로세스 우선) 등
- External: amount of funds being paid, political factors 등
Priority 스케줄링 역시 preemprive 와 non-preemptive 두 방식 모두 사용할 수 있다.
Priority 스케줄링의 문제점은 Starvation(기아)이 있다. Starvation은 말 그대로 CPU의 점유를 오랫동안 하지 못하는 현상을 말한다. Priority 스케줄링 방식에서 우선순위가 매우 낮은 프로세스가 ready queue에서 대기하고 있다고 가정해보자. 이 프로세스는 아무리 오래 기다려도 CPU를 점유하지 못할 가능성이 매우 크다. 실제 컴퓨터 환경에서는 새로운 프로세스가 자주 ready queue에 들어온다. 이러한 프로세스가 모두 우선순위가 높은 상태라면 이미 기다리고 있던 우선순위가 낮은 프로세스는 하염없이 기다리고만 있는 상태로 남아있을 수 있다.
이를 해결하는 방법 중 하나는 aging이 있다. 이 방식은 ready queue에서 기다리는 동안 일정 시간이 지나면 우선순위를 일정량 높여주는 것이다. 그러면 우선순위가 매우 낮은 프로세스라 하더라도, 기다리는 시간이 길어질수록 우선순위도 계속 높아지므로 수행될 가능성이 커진다.
3.4. Round-Robin(RR)
Round-Robin은 원 모양으로 모든 프로세스가 돌아가며 스케줄링하는 것을 말한다. 이는 시분할 시스템에서 주로 사용하는 방식이다. 일정 시간을 정하여 하나의 프로세스가 이 시간동안 수행하고 다시 대기 상태로 돌아간다. 그리고 다음 프로세스가 역시 같은 시간동안 수행한 후 대기한다. 이러한 작업을 모든 프로세스가 돌아가면서 하며, 마지막 프로세스가 끝나면 다시 처음 프로세스로 돌아와서 반복한다.
위에서 말한 일정 시간을 Time Quantum(Time Slice)이라 부른다. Time Quantum은 일반적으로 10 ~ 100msec 사이의 범위를 갖는다. Round-Robin은 기본적으로 preemptive 이다. 한 프로세스가 종료되기 전에 time quantum이 끝나면 다른 프로세스로 CPU를 넘겨주기 때문이다.
Gantt Chart
| Process | Burst Time(msec) |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
- Time Quantum = 4msec

Round-Robin 방식에서는 time quantum이 끝나면 CPU는 현재 프로세스를 대기상태로 보내고 다음 프로세스를 수행한다. 예제에서 P1이 0msec에 수행을 시작하여 종료되기 전에 time quantum 시간이 끝나여 P2가 수행되는 모습을 볼 수 있다. 그리고 P2, P3는 time quantum이 끝나기전에 수행이 끝났고, 마지막 남은 P1은 다른 프로세스가 없으므로 time quantum이 끝나더라도 종료될 때까지 계속해서 수행하는 모습이다.
RR방식은 time quantum 크기에 따라 Average Waiting Time과 같은 스케줄링 척도가 바뀐다. 그러므로 RR 방식은 time quantum에 매우 의존적인 것을 알 수 있다.
만약 time quantum 크기가 무한에 가깝게 설정한다면 FCFS와 동일하게 동작한다. 반대로 time quantum 크기를 0에 가깝게 설정하면 switching overhead가 매우 증가하여 비효율적이다. 결과적으로 time quantum 은 적당한 크기로 설정해주어야 하는데, 일반적으로 위에서 말했듯이 10 ~ 100msec 으로 정한다.
3.5. Multilevel Queue
Multilevel Queue를 살펴보기 전에 프로세스 그룹에 대해 살펴보자. 프로세스는 기준에 따라 여러 그룹으로 나눌 수 있다.
- System processes: 운영체제 커널 수준의 프로세스
- Interactive processes: 유저 수준의 대화형 프로세스
- Interactive editing processes
- Batch processes: 대화형 프로세스의 반대인 것으로 일정량을 한 번에 처리하는 프로세스(Ex, 컴파일러)
- Student processes
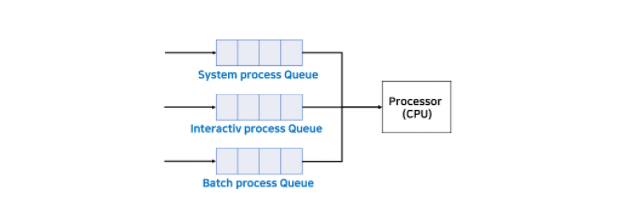
위와 같이 여러 성격에 따라 프로세스 그룹을 나눌 수 있는데 이를 하나의 큐에 사용하는 것은 비효율적이라고 판단하였다. 그래서 각 그룹에 따라 큐를 두어 여러 개의 큐를 사용하는 것이 Muitilevel Queue 방식이다.
위 그림은 각 그룹에 따라 큐를 나눈 것이다. 그리고 각 큐마다 다른 규칙을 지정할 수도 있다.
먼저, 큐마다 우선순위를 지정해줄 수 있다. 프로세스 그룹을 보면 System process는 커널 수준에서 중요한 작업이므로 우선순위가 높은 그룹이라 볼 수 있다. 위 그림에서 System process, Interactive process, Batch process 순으로 우선순위가 높은 순서이다. Batch 프로세스는 운영체제의 개입이 매우 적으므로 우선순위가 가장 낮다고 볼 수 있다.
위의 방식 이외에도 큐에 따라 여러 기준을 둘 수 있다. 큐마다 CPU 시간을 다르게 줄 수도 있고, 큐마다 다른 스케줄링 방식을 사용할 수도 있다.
3.6. Multilevel Feedback Queue
Multilevel Feedback Queue도 Multilevel Queue와 같이 여러 개의 큐를 사용한다는 점에서 유사하다. 먼저, 그림을 통해 살펴보자.
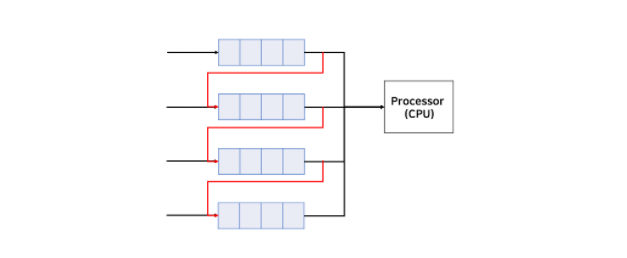
위 그림을 보면 먼저 모든 프로세스는 가장 위의 큐에서 CPU의 점유를 대기한다. 이 상태로 진행하다가 이 큐에서 기다리는 시간이 너무 오래 걸린다면 아래의 큐로 프로세스를 옮긴다. 이와 같은 방식으로 대기 시간을 조정할 수 있다. 그리고 Multilevel Feedback Queue에서도 각 큐마다 다른 스케줄링, 다른 우선순위 등을 사용할 수 있다.
만약 우선순위순으로 큐를 사용하는 상황에서 우선순위가 낮은 아래의 큐에 있는 프로세스에서 starvation 상태가 발생하면 이를 우선순위가 높은 위의 큐로 옮길 수도 있다.
대부분의 상용 운영체제는 여러 개의 큐를 사용하고 각 큐마다 다른 스케줄링 방식을 사용한다. 프로세스의 성격에 맞는 스케줄링 방식을 사용하여 최대한 효율을 높일 수 있는 방법을 선택한다.
