논리 부정 연산자
(ch < 'a' || ch > 'z') === !('a' <= ch && ch <= 'z')
위와 같이 논리부정연산자'!'를 적절히 사용해서 보다 이해하기 쉬운 식이 되도록 노력하자.
정수형의 선택기준
JVM의 피연산자 스택(operand stack)이 피연산자를 4 byte단위로 저장하기 때문에 크기가 4 byte보다 작은 자료형(byte, short)의 값을 계산할 때는 4 byte로 변환하여 연산이 수행된다. 그래서 오히려 int를 사용하는 것이 더 효율적이다.
결론적으로 정수형 변수를 선언할 때는 int타입으로 하고, int의 범위(약 20억)를 넘어서는 수를 다뤄야 할 때는 long을 사용한다.
byte나 short은 성능보다 저장공간을 절약하는 것이 더 중요할 때 사용하자.
명시적 형변환
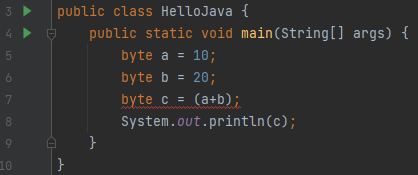
위의 코드는 컴파일 에러가 발생한다.
자료형이 byte, short와 같이 4 byte보다 작은 자료형은 int형으로 연산이 되기 때문에 위의 (a+b)는 (int)(a+b)와 같은 형태다. 그래서 1 byte에 4 byte(int)를 집어 넣으려고 했기 때문에 에러가 발생한다.
오류를 해결하기 위해서는 아래와 같이 명시적으로 타입을 지정해줘야 한다.
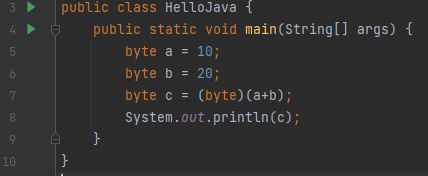
크기가 작은 자료형의 변수를 큰 자료형의 변수에 저장할 때는 자동으로 형변환(type conversion, casting)되지만, 반대로 큰 자료형의 값을 작은 자료형의 변수에 저장하려면 명시적으로 형변환 연산자를 사용해서 변환해주어야 한다.
정수형의 오버플로우
만일 4 bit 2진수의 최대값인 '1111'에 1을 더하면 어떤 결과를 얻을까? 4 bit의 범위를 넘어서는 값이 되기 때문에 에러가 발생할까?
원래 2진수에 '1111'에 1을 더하면 '10000'이 되지만, 4 bit로는 4자리의 2진수만 저장할 수 있기 때문에 '0000'이 된다. 즉, 5자리의 2진수 '10000'중에서 하위 4 bit만 저장하게 되는것이다. 이처럼 연산과정에서 해당 타입이 표현할 수 있는 값의 범위를 넘어서는 것을 오버플로우(overflow)라고 한다. 오버플로우가 발생했다고 해서 에러가 발생하는 것은 아니다. 다만 예상했던 결과를 얻지 못할 뿐이다. 애초부터 오버플로우가 발생하지 않게 충분한 크기의 타입을 선택해서 사용하자.
연산과정에서 해당 타입이 표현할 수 있는 값의 범위를 넘어서는 것을 오버플로우(overflow)라고 한다.
JVM의 메모리 구조
응용프로그램이 실행되면, JVM은 시스템으로부터 프로그램을 수행하는데 필요한 메모리를 할당받고 JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다. 그 중 3가지 주요 영역(method area, call stack, heap)에 대해서 알아보자.

1. 메소드 영역(method area) 또는 데이터 영역(data area)
프로그램 실행 중 어떤 클래스가 사용되면, JVM은 해당 클래스의 클래스파일(*.class)을 읽어서 분석하여 클래스에 대한 정보(클래스 데이터)를 이곳에 저장한다. 이 때, 그 클래스의 어떤 클래스변수(class variable)도 이 영역에 함께 생성된다.
2. 힙(heap)
인스턴스가 생성되는 공간, 프로그램 실행 중 생성되는 인스턴스는 모두 이곳에 생성된다. 즉, 인스턴스변수(instance variable)들이 생성되는 공간이다.
3. 호출스택(call stack 또는 execution stack)
호출스택은 메서드의 작업에 필요한 메모리 공간을 제공한다. 메서드가 호출되면, 호출스택에 호출된 메서드를 위한 메모리가 할당되며, 이 메모리는 메서드가 작업을 수행하는 동안 지역변수(매개변수 포함)들과 연산의 중간결과 등을 저장하는데 사용된다. 그리고 메서드가 작업을 마치면 할당되었던 메모리공간은 반환되어 비워진다.
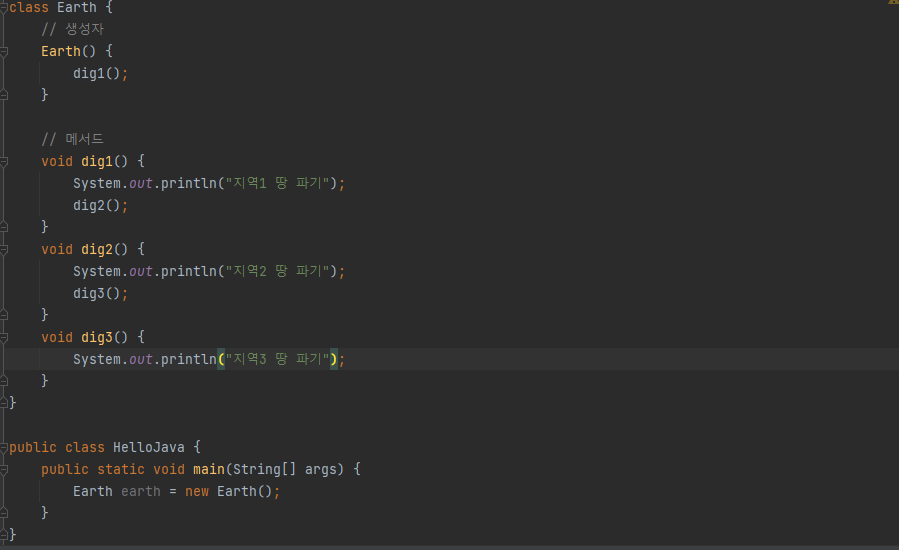

이 코드가 실행되면 먼저 메서드 영역에 class Earth, class HelloJava에 대한 정보를 저장하고, 힙에는 Earth 클래스의 객체인 earth가 생성된다. earth 객체가 생성과 동시에 호출스택에는 dig1메서드가 호출되고 dig2, dig3가 순차적으로 진행된다. 아래는 각각의 메소드가 호출 될 때의 호출스택 구조이다.
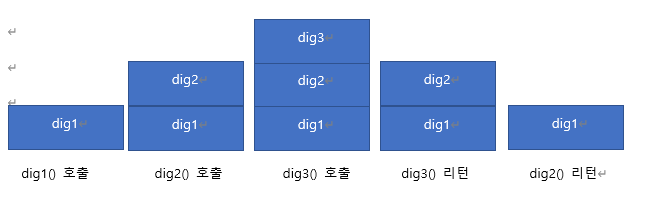
각각의 dig3(), dig2(), dig1() 메소드들이 호출되고 리턴이 될 때 호출스택에서의 각각의 메모리공간은 반환되고 마지막에 dig1()까지 종료되면 호출스택의 모든 공간은 비워지고 프로그램은 종료된다.(dig1(높은주소)에서 dig3(낮은주소)순 <-> 힙은 낮은주소에서 높은주소)
- 메소드 호출되면 수행에 필요한 만큼의 메모리를 스택에 할당받는다.
- 메소드가 수행을 마치고나면 사용했던 메모리 반환하고 스택에서 제거된다.
- 호출스택의 제일 위에 있는 메서드가 현재 실행 중인 메소드다.
- 아래에 있는 메소드가 바로 위의 메소드를 호출한 메소드이다..
...업데이트 예정
