
Mr.Tydi.
원조 tydi github link
Mr.tydi github link
Mr. TyDi is a multi-lingual benchmark dataset built on TyDi, covering eleven typologically diverse languages. It is designed for mono-lingual retrieval, specifically to evaluate ranking with learned dense representations. Mr. TyDi is licensed under the Apache License 2.0.
민싱식 설명)
Mr.tydi는 기존 retrieval의 성능은 english에서만 측정이 되었지만 다른 언어에서는 retrieval의 성능측정x
선택된 passage 혹은 document에 answer에 대한 내용이 들어있지 않을수도 있다. 질문에 대한 답을 선택한 article의 passage에서 찾을 수도 있고 찾지 못할 수도 있습니다.
monolingual retrieval의 ranking을 evaulate 하기 위함.
tydi dataset에 기반
목적
The goal of this resource is to spur research in dense retrieval techniques in non-English languages, motivated by recent observations that existing techniques for representation learning perform poorly when applied to out-of-distribution data.
This dataset can be viewed as the “openretrieval” condition of the TYDI multi-lingual question answering (QA) dataset (Clark et al., 2020), and “Mr” in Mr. TYDI stands for “multi-lingual retrieval”.
reference
민싱식 정리)
- 다양한 언어의 유형을 cover할수 있는 monolingual retrieval을 위해 design됨. 특히 dense representation들에 ranking을 evaluate하는것.
왜 멀쩡한 tydi를 냅두고 Mr.tydi를 만들었는가?
Mr.tydi는 기존 tydi dataset이 충분하지 않는데에 기반한다. 왜 충분하지 않냐면 아래 설명에서 이어진다.
Mr.tydi는 뭐가 다른가?
논문왈)
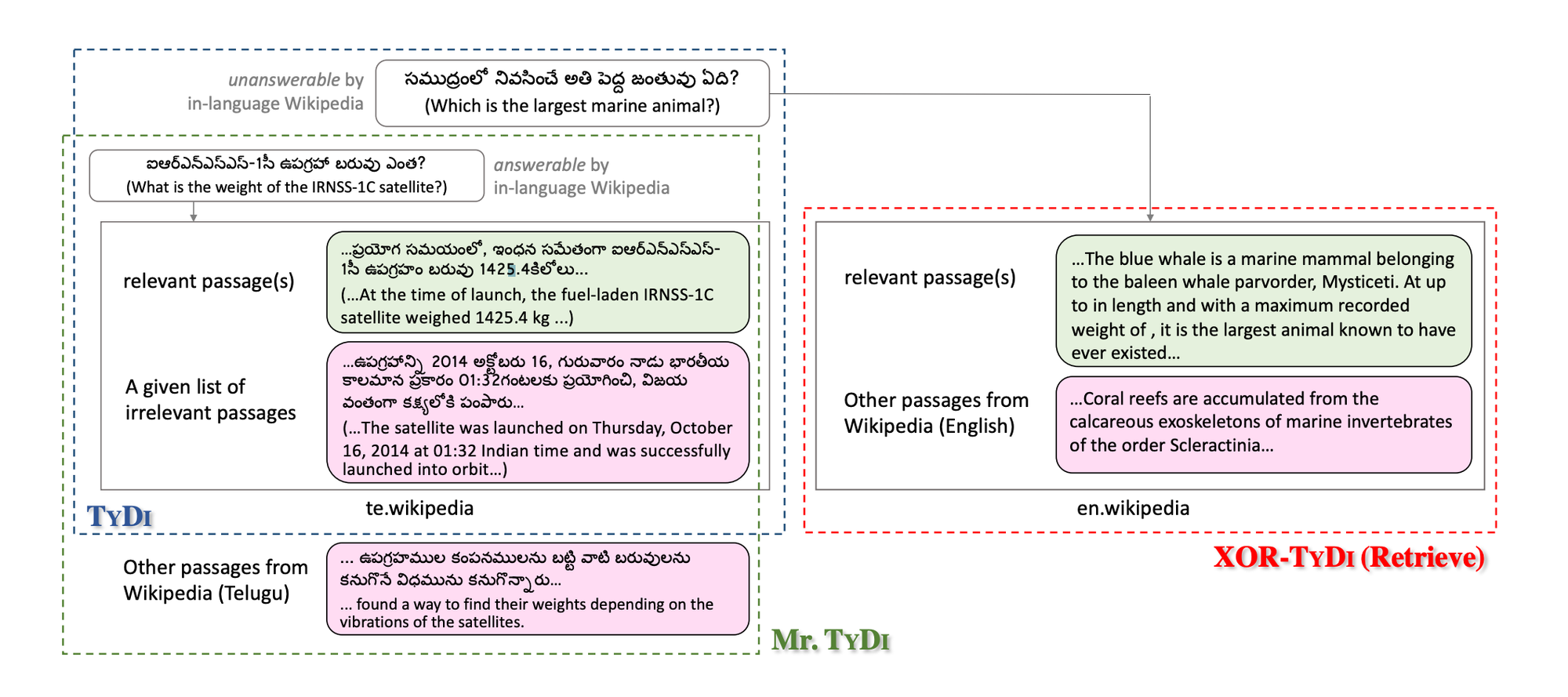
This dataset can be viewed as the “open retrieval” condition of the TYDI multi-lingual question answering (QA) dataset (Clark et al., 2020), and “Mr” in Mr. TYDI stands for “multi-lingual retrieval”.
reference
tydi의 한계를 보완하기 위해서 Mr.tydi가 만들어진것이다. Mr은 multi-lingual 즉, 다중언어 retrieval을 의미한다.
약점)
(1) 기존 tydi는 SQuAD dataset과 같이 machine reading comprehension task에 지나치지 않다.
(2) 답이 단답형이다. 딱 단어만 말하는 answer들이 많다.
(3) candidate passage들은 모두 dataset의 일부로 포함되어 있기 때문에(즉, open domain, open retrieval 스러운건 한꺼번에 passage들을 몰아놔야하는데 그전 tydi에서는 한 쿼리당 candidate passage들이 있어 open domain 스럽지 않다.)
-> 논문에서 tydi weakness 설명하는부분의 the dataset은 query - answer - candidate passages
=> mr.tydi는 따라서 open-retrieval의 extension으로 볼수 있으며 단답형이 아닌 줄글로 만든 passages들로 조금더 open-domain, open-retrieval스럽게 재구성했다.
huggingface(mr.tydi)
castorini/mr-tydi · Datasets at Hugging Face
이 데이터 셋을 하는 의의
기존은 영어로만 되어있던 dataset을 train하고, 이를 통해 retrieval하고 evaluate하는것에 끝났다면 mr.tydi는 11개의 language들로 각각의 언어에 특화된 mono-lingual model이다.모든언어에 다 잘 되는 retrieval을 위한 dataset으로써 사용하는데에 의의가 있다.
우리가 진행하는 RAG에서 non-english retrieval에 대한 evaluate를 하는 benchmarck로써 Mr.tydi는 의의가 있다.
어떻게 RAGchain에 benchmark로 적용할것인가?
Passage 특성
-
answer passage와 question은 항상 같은 language로 작성
-
passage들은 google search를 통해서 wikipedia article에서 가져왔으며 snippet으로 답할 수 없는 query에 대해 annotators들이 작성하게끔함.
그리고 annotator들이 직접 주어진 top wikipedia article에 대해서 각각의 article에 대해서 passage들의 relevancy를 최소한의 답변범위를 바탕으로 답변을 만들어낸다.
따라서 wikipedia의 article로부터 가져온 passage들에서 질문에 대한 답변을 찾을 수 없을수도 있다.
cf) snippet은 검색 결과에 대한 웹페이지 내용을 간략하게 요약한것 -
다른 language에 해당하는 data들은 번역본이 아닌 독립적으로 사용된것이므로 비교할 수 없다.
논문왈(reference)
The weakness of TYDI from our perspective is that it is essentially a machine reading comprehension task like SQuAD (Rajpurkar et al., 2016) because candidate passages are all included as part of the dataset (i.e., the passages are from the top Wikipedia article returned by Google search). Instead, we need a resource akin to what QA researchers call the “open-domain” or “open-retrieval” task, where the problem involves retrieval from a much larger corpus (e.g., all of Wikipedia) (Chen et al., 2017). Thus, at a high level, Mr. TYDI can be viewed as an open-retrieval extension to TYDI.
positive passage란?
- query에 대한 answer passages들
negative passage란?
- tuned BM25가 retrieve한 top-30 의 candidate passages result들
- positive passage가 포함되어있을수도 있고 없을수도 있다.
positive passage가 retrieval_gt가 될 수 있는 근거
- data format 을 보니 train ,test 모두 positive passage는 필수적으로 구성되어있었으며 test set에는 positive만 들어있다. 따라서 test에 retrieval gt는 positive passage이므로 train 또한 positive passage이라고 볼 수 있다.
또한 그게 아니면 retrieval gt가 될만한 마땅한 passage가 없다. - 논문에서
annotator들이 직접 주어진 top wikipedia article에 대해서 각각의 article에 대해서 passage들의 relevancy를 최소한의 답변범위를 바탕으로 답변을 만들어낸다.
따라서 wikipedia의 article로부터 가져온 passage들에서 질문에 대한 답변을 찾을 수 없을수도 있다.
라고 나옴.
hugging face 왈(castorini/mr-tydi)
”The negative examples from training set are sampled from the top-30 BM25 runfiles on each language.”
data format
train set
{
'query_id': '1',
'query': 'When was quantum field theory developed?',
'positive_passages': [
{
'docid': '25267#12',
'title': 'Quantum field theory',
'text': 'Quantum field theory naturally began with the study of electromagnetic interactions, as the electromagnetic field was the only known classical field as of the 1920s.'
},
...
]
'negative_passages': [
{
'docid': '346489#8',
'title': 'Local quantum field theory',
'text': 'More recently, the approach has been further implemented to include an algebraic version of quantum field ...'
},
...
],
}test set
{
'query_id': '0',
'query': 'Is Creole a pidgin of French?',
'positive_passages': [
{
'docid': '3716905#1',
'title': '',
'text': ''
},
...
]
}Corpus(only train for retrieval)
This dataset stores documents of Mr. TyDi. To access the queries and judgments, please refer to castorini/mr-tydi.****
data format
{
'docid': '25#0',
'title': 'Autism',
'text': 'Autism is a developmental disorder characterized by difficulties with social interaction and communication, ...'
}떠오른 evaluation 방식(mr.tydi 사용한 예제 코드들 확인해보기)
방법1.[기각]
negative passage의 활용방안은 qasper처럼 한 쿼리당 negative passage들과 positive passage를 합친 것에서 retrieval이 retrieve하게 끔 시키고 evaluate하는 방식
question ⇒ query들 입력
retrieval_gt ⇒ positive passage(id에 해당하는 리스트를 input)
passages ⇒ negative passage + positive passage →
결론)
똑같이 bm25 retrieval이 query에 대해서 retrieve한 negative passage들인데 다시 negative passage와 positive passage를 합쳐서 인제스트 한 passages들중 bm25 retrieval로 한 passage를 evaluate하는게 의의가 있는가?하는 의문
⇒ 결과적으로는 bm25 retrieval이 수많은 corpus중에서 retrieve한 top-k passage중에서 다시 bm25 retrieval이 그중에서 retrieve하는것은 의미가 없다고 생각.
단, mr.tydi가 직접 tune한 bm25 retrieval로 retrieve한 top-k negative passage들로 사용자가 직접 만든 retrieval의 성능을 비교할 수는 있을듯
⇒ 그렇게 하기 위해서는 corpus로 ingest해서
이를 바탕으로 사용자가 직접 만든 retrieval이 한 쿼리당 retrieve한 passage들의 개수를 그 쿼리에 대응되는 mr.tydi의 negative passage들의 개수만큼 retrieve해서 evaluation하여 각각 비교해야한다.
방법2.(채택)
strategyQA 처럼 corpus로 한꺼번에 ingest 한다음 retrieve 시키기
⇒ corpus는 MSMARCO처럼 query에 대한 passage들의 id가 ingest할 데이터와 순서대로 되어있지 않기 때문에 매번 ingest할때 corpus를 모두 ingest 해야함.
어디에 retrieval gt가 corpus안에 들어있는지 모르기 때문
- retrieval_gt ⇒ positive passage
- question ⇒ query
- ingest할 passage ⇒ corpus
⇒ 현재로서는 가장 채택하기 좋은 정공법이며 mr.tydi example과 논문들 또한 그러한 방식으로 한것으로 보임.
Evaluate metric
1. F1 (Tydi)
2. MRR@100(mean reciprocal rank) → rank aware한 녀석
- 뭐에 대한 rank인가?
=>
→ bm25 retrieval이 100 hit를 가지고 top-k중 retrieve한 녀석의 rank를 역수로 취해서 rank가 점점 작은 수일수록 큰 수가 되고,
다른 순위로 retrieve한 passages들의 rank의 역수를 다 더해서 mean 값을 구한것임.
찾고자 하는 retrieval gt로 bm25가 retrieve한 녀석의 순위를 체크후 그 순위를 역수로 취한것이 → reciprocal rank
ex) 10개의 추천리스트 중 사용자가 선호하는 아이템이 7번째에 있다면 reciprocal rank는 1/7이 되는 것이다.
mrr은 각각의 다른 추천 아이템의 역수 RR을 구한후 mean값을 취한것
그렇다면 retrieval gt를 알아야하며 retrieval gt는 논문에서 어떻게 구했는가?
그리고 retrieval gt가 될 postive passage가 여러개 있을때는 positive passages들의 랭킹이 있는가? 랭킹이 없다면 어떻게 mrr을 매길때 retreival gt를 매겼는가?
→ 서로 동등한 관계, 즉 찾고자 하는 녀석이라면 그 positive passage들의 순위의 역수를 더해서 mean값을 하면 어차피 mrr이 나오므로 positive passage들간의 rank가 없더라도 MRR계산은 쌉가능이다.
→ 때문에 논문에서는 positive passage의 우선순위에 관한 내용이 없던 것이다.
- Recall@100

생길수 있는 궁금증:
(1) negative passage안에 positive passage가 포함되어있는가(모두?)?
⇒ 있는것도 있고 없는것도 있다. / 없는것이 더 많다.
(2) 지금확인하려는것은 corpus docid가 passage에 맞는가
⇒ 맞다. train, dev, test data의 passages들의 docid는 모두 corpus로부터 나온 녀석들이다.
(3) 그렇다면 negative passages들도 다 corpus에 해당? 그리고 query에 대한 negetive passage가 bm25 retrieval로 top 30 passages들을 뽑아낸거라면 positive passagese들은 query와 가장 관련성이 있는 passage고 이것은 어떤 기준으로 알아낸것인가?
⇒ msmarco처럼 human editor인가?
⇒ 논문에서 유추 가능
annotator들이 직접 주어진 top wikipedia article에 대해서 각각의 article에 대해서 passage들의 relevancy를 최소한의 답변범위를 바탕으로 답변을 만들어낸다.
따라서 wikipedia의 article로부터 가져온 passage들에서 질문에 대한 답변을 찾을 수 없을수도 있다.
(4) 똑같이 bm25 retrieval이 query에 대해서 retrieve한 negative passage들인데 다시 negative passage와 positive passage를 합쳐서 인제스트 한 passages들중 bm25 retrieval로 한 passage를 evaluate하는게 의의가 있는가?하는 의문
⇒ 결과적으로는 bm25 retrieval이 수많은 corpus중에서 retrieve한 top-k passage중에서 다시 bm25 retrieval이 그중에서 retrieve하는것은 의미가 없다고 생각.
(5) 논문에서는 어떻게 evalute했는지 예제코드 참고하기(- 결과적으로 논문에서는 수많은 corpus중 하나를 찾는건지를 한번 체크해볼 필요가 있음)
⇒ 대부분의 pyserini를 활용한 예제라서 예제 코드를 참고하기 어려움.
⇒ negative passage와 positive passage 모두 corpus에서 나온것이고, Mr.tydi가 직접 tuned된 bm25 retrieval이 retrieve한 negative passage들의 성능과 사용자가 직접 만든 retrieval의 성능을 비교하고 싶다면
negative passage를 활용하면 될듯.
(6) 빈 passage가 있는가 검증
⇒ negative passage에 하나 있음. 하지만 채택된 evalutation 방식에서 negative passages는 활용하지 않기 때문이고, negative passages는 비어있지만 써야할 positive passages는 있기 때문에 영향은 없다.
(annotator가 snippet으로 만들 수 없는 답변들에 해당하는 질문들에 대하여 직접 positive passage를 작성한것으로 보임)
(7) positive passage는 여러개 있는가? 그 사이에는 rank가 있는가? → 근데 MRR이라는 rank aware metric으로 evaluate한다면 rank가 있다고 추정
⇒ positive passage는 한 쿼리당 2개 이상으로 있는것으로 확인된다.
⇒ MRR자체가 내가 찾고자하는 아이템의 순위를 바탕으로 RR(역수)를 취해 ∑로 모두 더한다음 mean값을 매기는 것이기 때문에 내가 찾고자 하는 아이템의 rank는 상관 없다.
⇒ 때문에 논문에서도 positive passage가 한 쿼리당 여러개 있을때 이것이 rank가 있는지에 대한 설명은 없었던것임!
결국 MRR metric을 이해하고 있었어야하는 문제
