Pandas: How to Drop Rows that Contain a Specific Value without drop() method and for loop?
고오급 스킬들 공략집
목록 보기
5/20

특정 value가 있는 row를 for문 없이 어떻게 하면 빠르게 없앨까?
drop() 매서드를 사용하면 dataframe이 커질때 느려질수도 있다고 해서 찾아본 다른 방법이다.
이 방법의 이름은 boolean mask기법이다.
import pandas as pd
# 랜덤 데이터프레임 생성
df = pd.DataFrame({
'무': [1, 2, 3, 4, 5],
'야': [5, 15, 10, 20, 15],
'호': [10, 15, 10, 20, 15],
'테': [10, 15, 10, 20, 15],
'스': [10, 15, 10, 20, 15]
})
# 삭제하려는 값들을 포함하는 리스트
values = [2, 4, 6, 8, 10]
# 리스트의 값들이 데이터프레임의 어떤 열에 있는지 확인
mask = df.isin(values)
# 리스트의 값들이 있는 행을 삭제
df = df[~mask.any(axis=1)]
print(df)코드 간단설명
- 삭제하려는 값이 들어있는 values 리스트를 생성한다.
- df.isin() 매서드로 리스트에 해당하는 값이 df 데이터프레임의 각 요소가 리스트 값들중 하나와 일치하는지 확인한다. 일치하면
True를 반환하고 없으면False를 반환하는 daframe으로 바꿔 mask 변수에 저장한다.
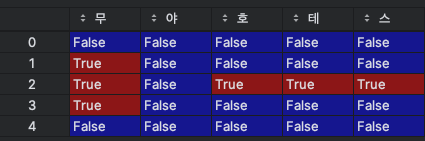
-
그런 다음, 이 마스크를 부정하여 리스트의 값들이 있는 행을 삭제한다. 이를 위해
~연산자를 사용하여 마스크의 값을 반전시킨다. 이렇게 하면 리스트의 값들이 있는 행은False를 가지게 되고, 그 외의 행은True를 가지게 됩니다. -
마지막으로
any(axis=1)함수를 사용하여 각 행에 대해 적어도 하나의 요소가True인지 확인합니다. 이렇게 하면 리스트의 값들이 있는 행이 삭제됩니다.

존나 재밌는것을 맨듭니다.