
🍳 동기
나만의 second brain을 구축하여 놓치는 지식이 없애고, 지식을 체계화시키는것이 주 관심사이다.
나만의 맞춤형 지식 체계를 구축하는데에 있어서 보안문제와 비용문제를 해결할 수 있으면서 맞춤형으로 모델을 커스터마이징하고, 오프라인 사용할 수 있는 local LLM에 관심이 많았다. 이번 기회에 linux에서 local LLM을 설치하고 fine tuning후 간단한 봇을 만들어보고 싶어 Ollama를 설치하게 되었다.
🍳 튜토리얼
ollama 설치
Ollama는 로컬환경에 LLM을 실행할 수 있게 하는 프레임 워크이다.
아래 명령어를 통해서 ollama를 설치해보자.
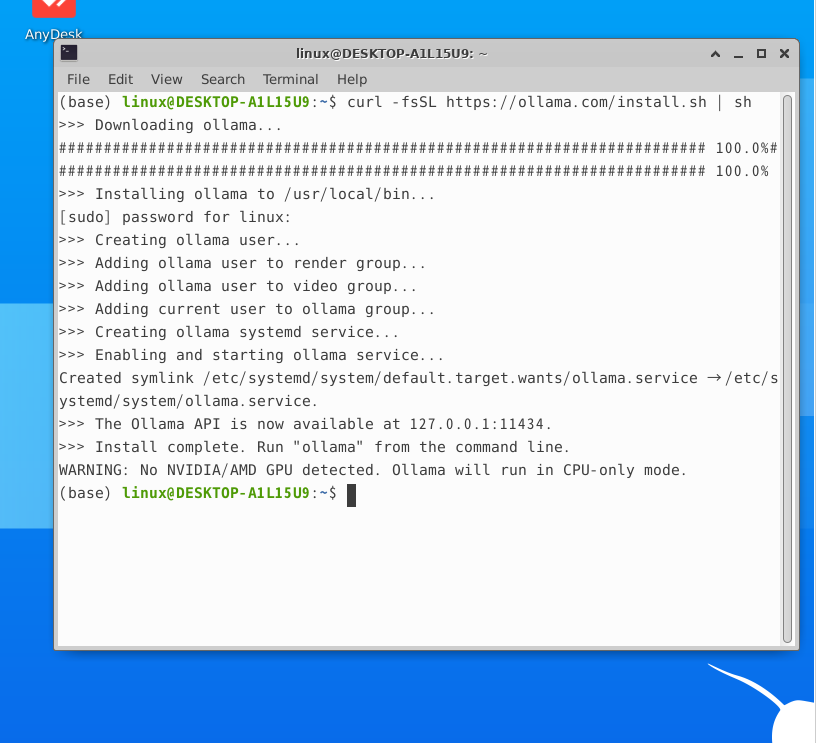
curl -fsSL https://ollama.com/install.sh | sh설치가 완료되면 아래와 같이 뜬다. 내 사무용 노트북에는 NVIDIA/AMD GPU는 절대 존재할리가 없으니 detected되지 않았다고 뜨고, Ollama가 CPU only mode로 실행될거라고 나온다,
사용해보기
Mistral 사용해보기
ollama run mistral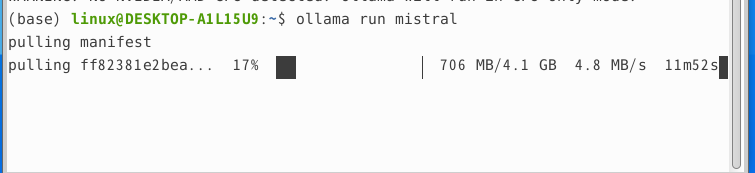
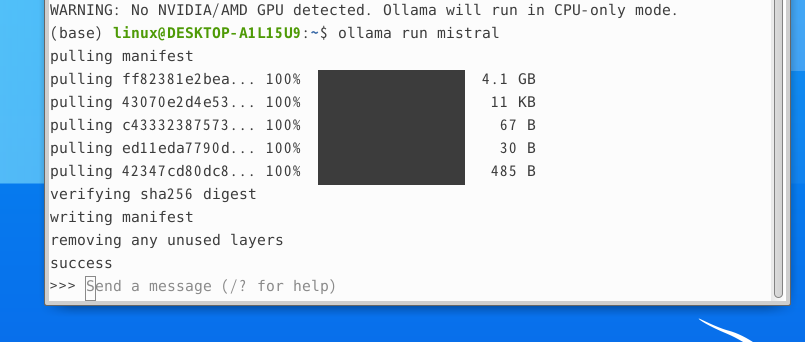
pull이 완료되면 Send a message 라는 메세지 창이 생긴다.
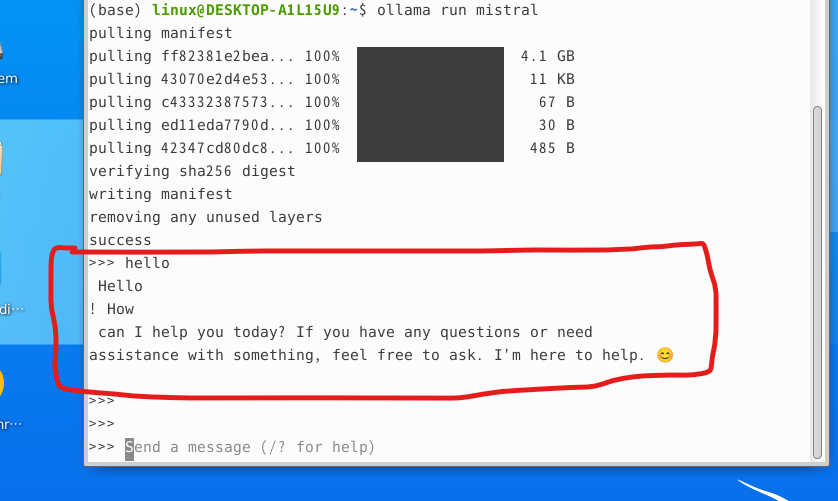
test로 hello라고 입력해보면 답변이 잘 나오는것을 확인할 수 있다.
mistral의 답변에서 나온 줄바꿈은 내가 성격이 급해서 여러번 엔터를 눌러서 저렇게 결과가 나온것이지 실제로는 한줄로 잘 출력이 된다.
fine tuning 하는방법 물어보기
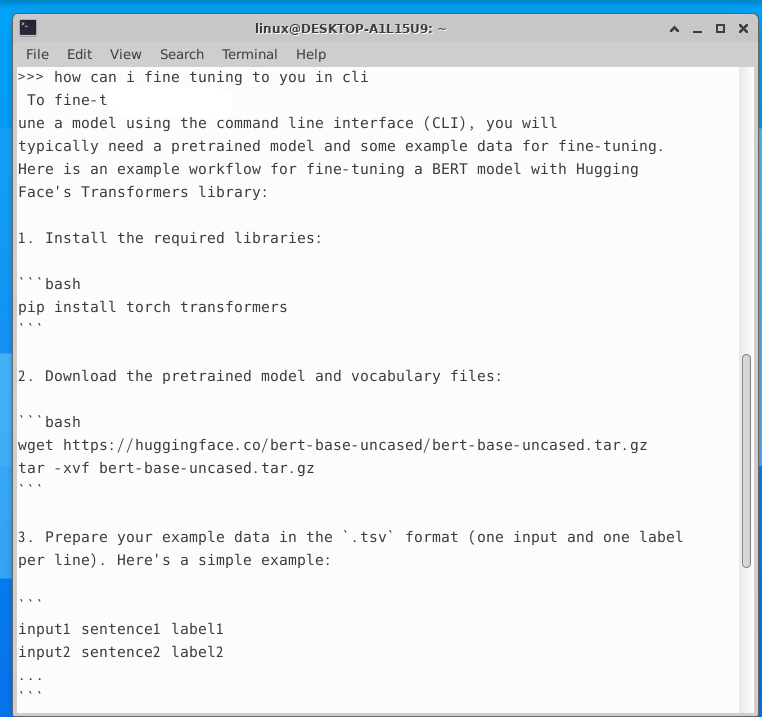
🍳 느낀점
local llm의 매력은 데이터 privacy와 비용, 모델을 커스터마이징할 수 있다는 장점이 있다. 이는 특정 도메인, 즉 내가 향후 second brain을 구축하는데에 있어서 '나'에 대한 도메인에 특화된 llm을 적용할수 있다는 큰 이점이 있다. 나의 second brain 구축에 있어서 local llm은 내 지식체계를 기반한 질의 응답과 내가 기록하고 느낀것에 대한 지식들의 자동 구조화라는 두가지 기능에 활용될것 같다.
참고문헌
1. 튜토리얼: https://brunch.co.kr/@b2439ea8fc654b8/28
