Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
SMPLX 논문 [링크](https://smpl-x.is.tue.mpg.de/)
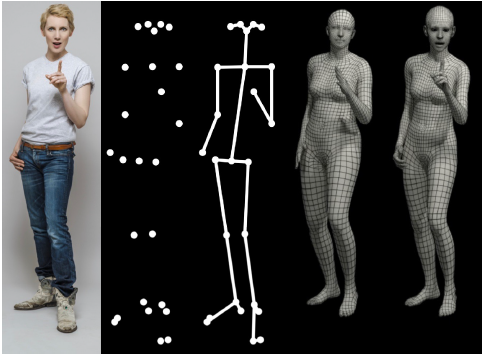
1. Introduction
사람의 행동을 더 잘 이해하기 위해선, 사람의 major keypoint들을 estimation 하는 것으로는 충분하지 않고, 몸, 손, 얼굴의 3D surface 정보들까지 포함해야 할 필요가 있다. 그런데 적절한 3D model과 3D training data가 충분하지 않아서, 이렇다 할 모델들이 없었다.
사람을 전체적으로 표현할 수 있는 방법은 부족한 2D 정보나 손이나 얼굴에 대한 detail이 없는 3D representation을 사용해서는 부족하다고 지적하며, 필요한 2가지를 소개한다.
- 사람의 얼굴, 손, 자세의 복잡함을 나타낼 수 있는 3D model이 필요하다.
- single image에서 이런 모델을 extract하는 방법이 필요하다.
이 논문에서는 대량의 3D scan data로부터 얼굴과 손까지 포함한 새로운 body model을 학습했다. 전에 있었던 SMPL model(손이나 얼굴에 대한 detail이 떨어지는), FLAME(head model), 그리고 MANO(hand model) 이렇게 3가지를 혼합하여 모델을 구성하고, 데이터로부터 이 모델을 학습시켰다. 학습시킨 결과 체형, 얼굴, 손의 체형 사이 상관관계를 capture 할 수 있었다고 한다.
구체적으로는 Technical Approach section에서 서술하고 있다. 아래서부터는 논문 section 3 이후의 내용이다.
2. Unified model: SMPL-X
SMPL-X는 vertex-based linear blend skinning을 사용한 모델로, 10475개의 vertice(3D point)와 54개의 관절들로 구성되어 있다. linear blend skinning에 관한 내용은 여기를 참고하면 될 것 같다. 간단하게 사람의 mesh를 모델링하는 방법으로 이해했다.
SMPL-X는 위에서 설명했듯이 파라미터를 이용하여 human avatar를 모델링했는데, 이에 대해선 다음과 같이 나타낸다.
학습을 통해서 얻어진 기본적인 template mesh를 기반으로, 이 3개의 파라미터들을 조절함으로써 avatar의 pose를 바꾸거나 체형을 조절할 수 있다.
여기서
는 pose에 관한 파라미터로, 좀 더 자세하게는 jaw joint, finger joint, body joint로 구성된다. 는 body shape에 관한 파라미터고, 는 facial expression에 관한 파라미터다. 여기서 구체적으로는, linear blend skinning function W 안에 있는 blend weight도 들어간다. pose vector 를 part-relative matrix로 mapping 하는 function, 등 더 복잡한 식으로 풀어진다.
결과적으로, SMPL-X에서 사용하는 파라미터는 총 119개로, 75개는 global body rotation과 body, eyes, jaw에 관한 것이고, 24개는 손, 10개는 shape에 관한 것이고, 나머지 10개는 facial expression에 관한 것이다.
optimization function
수식 상에서, 는 body에 대한 pose vector, 는 face에 대한 pose vector, 는 두 손에 대한 파라미터로, 최적화가 가능한 변수들의 집합이다.
다음의 loss term을 최소화하는 것이 목표인데, 각 term들에 대해서 알아보겠다.
3. SMPL-X from a single image
는 re-projection loss인데, image의 2D joint와 3D avatar의 joint를 2D로 projection해서 획득한 2D joint 사이의 거리에 대한 term이다. 3D -> 2D projection을 위해선 intrinsic camera parameter를 알아야 한다. 2D joint의 경우 Openpose를 사용했다.
R은 값에 따라 joint를 바꾸는 함수고, 는 3D를 2D로 projection하는 것을 의미한다. 는 noise를 줄이기 위한 function에 해당하고, 그 외 변수들은 가중치에 해당하는 값들이라 이해하면 되겠다.
4. Variational Human Body Pose Prior
사람 신체 구조상 불가능한 자세들이 있다. 팔이 뒤로 심하게 꺾인다거나, 목이 심하게 꺾이는 경우, 등이 있겠다. 이런 경우들에 대해 penalty를 주고, 가능한 자세들이 나오게끔 최적화할 때 학습된 prior를 제공한다.
이 논문에서는 Variational Encoder를 사용한 VPoser라는 모델을 학습시켰다. 이 모델은 사람 pose에 대한 latent representation을 학습하고, latent code의 distribution을 normal distribution으로 regularize 하는 모델이다. (설명이 어려워 보이지만, VAE가 하는 일을 서술한 것뿐이다. 적용 대상이 사람 pose가 됐을 뿐!)
Introduction에서 이 pose prior에 대해서 서술하는데, 2D 에서 3D로 mapping 하는 것은 ambiguous 하기 때문에, 중요한 term이라고 한다.
- ambigous한 이유는 2D에서 3D로 single image 하나로 mapping 할 때 얼마큼 멀리 있는지 depth, 또는 scale에 대한 정보가 부족하기 때문이다. 이를 해결하려면 stereo view나 multi view가 필요하다.
5. Collision penalizer
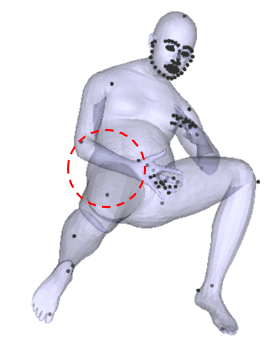
최적화를 하다보면 body part들끼리 겹치는 문제점들이 생긴다. 실제로는 사람 신체들이 겹치는 것이 불가능하므로, 이에 대한 penalty를 주기 위한 loss term이다. avatar는 vertex로 이루어져 있고 vertex 3개로 triangle을 만든다. 이때 서로 겹치는 triangle을 찾고, (Bounding Volume Hierarchies를 이용했다고는 하는데, 이건 좀 더 공부를 해봐야겠다) 이들의 거리가 멀어질 수 있도록 최적화를 한다.
6. Optimization
optimization function을 multi-stage로 최적화한다. 최적화는 pytorch optimizer를 이용해서 진행했다.
먼저 unknown camera translation과 global body orientation을 맞춘다. Template avatar의 위치와 기울어진 정도를 조절해서, projected된 3D joint들에 더 잘 맞게 하는 과정이다. 이후에 이 두 가지를 고정시키고, body shape과 pose에 관한 파라미터를 최적화한다. face와 hand의 경우 part 자체는 작으나 joint수가 많아서, 전체적인 pose를 잡는 동안에는 가중치를 둬서 그 영향을 더 작게 했다. 각 term들마다 pose에 주는 영향이 다를 텐데 이들을 조절하는 가중치가 optimization function 앞에 있는 값이다.
7. Result
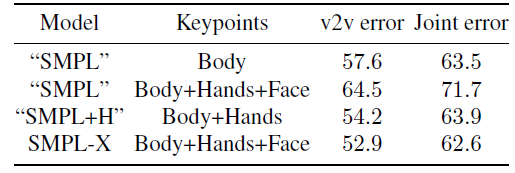
결과는 위와 같다. v2v error란 vertex to vertex error를 말하는 것인데 SMPLX에서 가장 작았다. joint error 또한 가장 작았다.

논문에 쓰인 결과 사진 중 일부를 가져온 것이다. 상당히 잘 맞는 것을 볼 수 있다. 아무래도 3D를 다루는 것이 복잡하다보니 SMPLX에서도 이것저것 다양한 모델들과 방법들이 사용된 것 같다.
8. Reference
