프로세스와 스레드 part1.
사실, 저희는 자바스크립트로 프로그래밍을 하면서 프로세스와 스레드를 직접적으로 설정하거나 관리하지는 않습니다.
물론, 다들 아시겠지만 자바스크립트는 직접적으로 프로세스와 스레드를 지원해 주는 언어와 달리, 직접적인 지원을 하지 않습니다.
그럼에도 불구하고, 프로세스와 스레드는 컴퓨터안에서 작동하는 모든 프로그램에 적용되는 개념이므로 꼭 알아둘 필요가 있는 중요한 개념입니다.
1. 프로세스
먼저, 프로세스와 스레드에 대한 간단한 정의부터 살펴보겠습니다.
1) 정의.
프로세스는 보통 실행중인 프로그램을 말합니다. 윈도우의 작업 관리자(혹은 맥의 활성 상태)를 열어 프로세스 항목을 보면, 굉장히 많은 프로세스가 현재 실행중인 것을 알 수 있습니다.
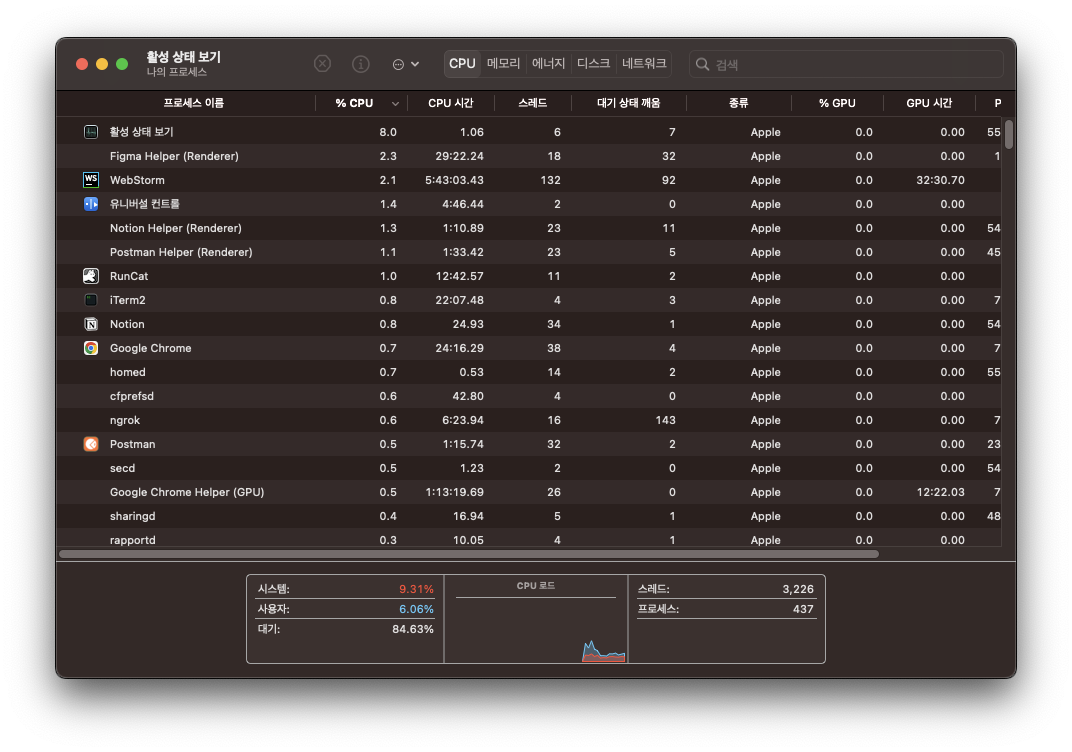
이처럼, 우리가 컴퓨터를 사용하는 동안, 메모리 안에서는 새로운 프로세스들이 계속 생성되고, 사용되지 않는 프로세스는 메모리에서 삭제됩니다.
물론, 이런 프로세스들이 한 번에 다 사용되지는 않습니다. 일반적으로 하나의 cpu는 한 번에 하나의 프로세스만 실행할 수 있습니다. 따라서, cpu는 이 프로세스들을 조금 씩 번갈아 가며 실행합니다.
보다 자세히 보시기 위해서는 터미널에서 다음과 같이 쳐서 직접 확인해 볼 수 있습니다.

top라고 쳐서 확인해 보면, 다음과 같이 터미널에 현재 내 pc에서 운용중인 프로세스를 직접 실시간으로 살펴볼 수 있습니다.
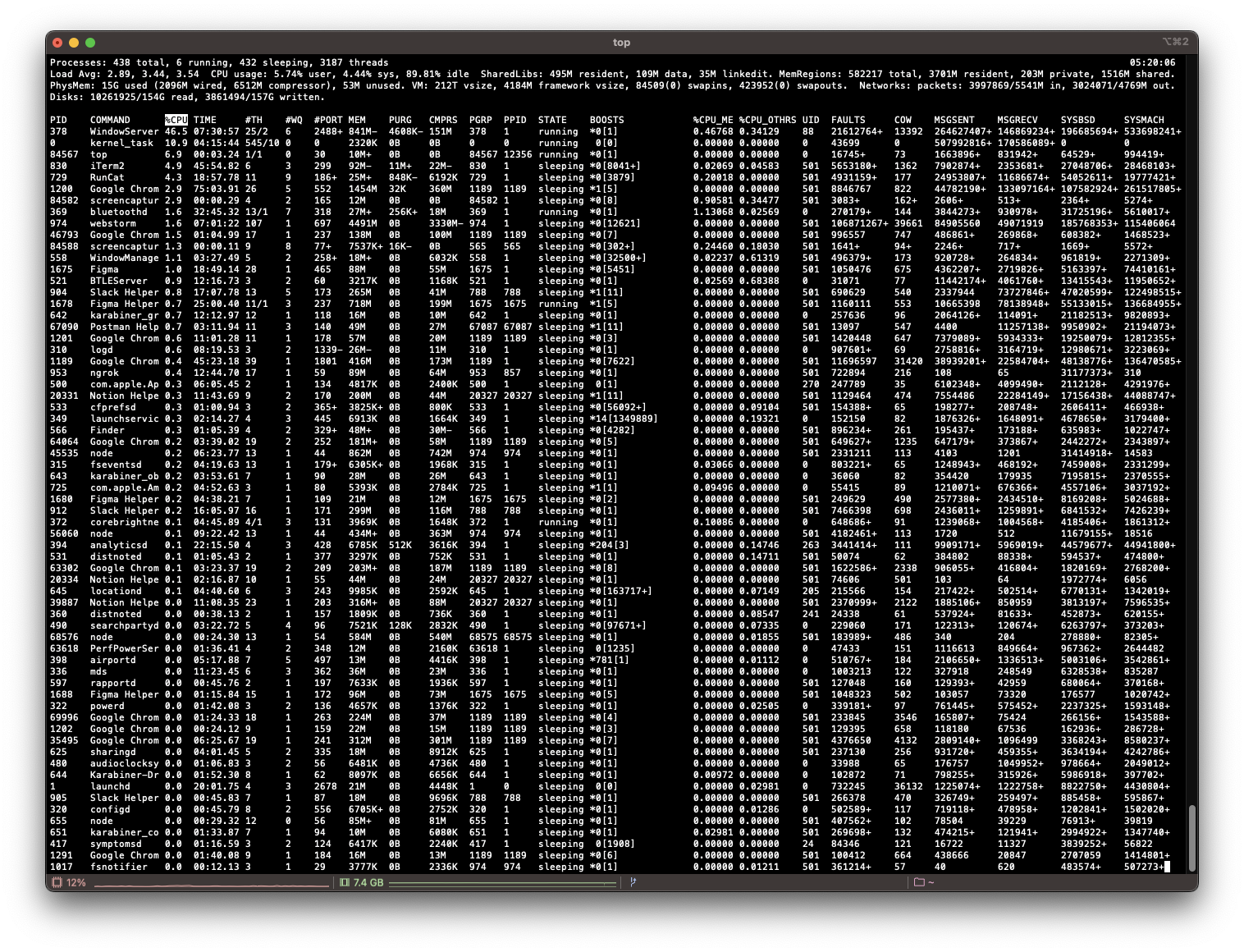
이처럼 cpu는 한 프로세스를 실행하다가 또 다른 프로세스로 실행을 전환하고, 그 프로세스를 실행하다가 또 다른 프로세스의 실행으로 전환하는 것을 반복합니다.
2) 동작 원리.
우리는 앞서 프로세스가 프로그램을 실행하는 하는 것이라고 만 살펴봤습니다.
그렇다면, 이번에는 프로세스가 과연 어떤 동작 원리를 가지고 프로그램을 실행하는 지 살펴 볼 차례입니다.
1) 프로세스 제어 블록(=PCB).
- PCB의 개념.
먼저, 모든 프로세스를 실행하기 위해서는 CPU가 필요 하지만, 앞서 언급한 것처럼 CPU는 자원이 한정되어 있습니다.
즉, 모든 프로세스가 CPU를 동시에 이용할 수는 없습니다. 그렇기에 프로세스들은 차례대로 돌아가며 한정된 시간만큼만 CPU를 이용합니다.
자신의 차례가 되면 정해진 시간만큼 CPU를 이용하고 시간이 끝났음을 알리는 인터럽트(타이머 인터럽트)가 발생하면 자신의 차례를 양보하고 다음 차례가 올 때까지 기다립니다.
운영체제는 이를 위해서, 프로세스 제어 블록(=PCB)이라고 불리는 것을 운용합니다.
프로세스 제어 블록은 특정한 프로세스를 관리할 필요가 있는 정보를 포함하는 운영 체제 커널의 자료 구조입니다.
쉽게 말하면 운영체제가 프로세스를 제어하기 위해 프로세스의 상태 정보를 저장해 놓는 구조체입니다. 따라서 이 PCB마다 각자 각기 다른 값들을 가지고 있습니다. 마치 옷 가게에서 점원이 수많은 옷들 사이에 옷에 붙여진 태그로 옷과 관련된 정보를 판단하는 것처럼 운영체제도 수많은 프로세스들 사이에서 PCB로 특정 프로세스를 식별하고 해당 프로세스를 처리하는 데 필요한 정보를 판단합니다.
- PCB의 항목
PCB는 운영체제마다 약간의 차이는 있지만, 다음 그림과 같은 항목들을 저장하고 있습니다.
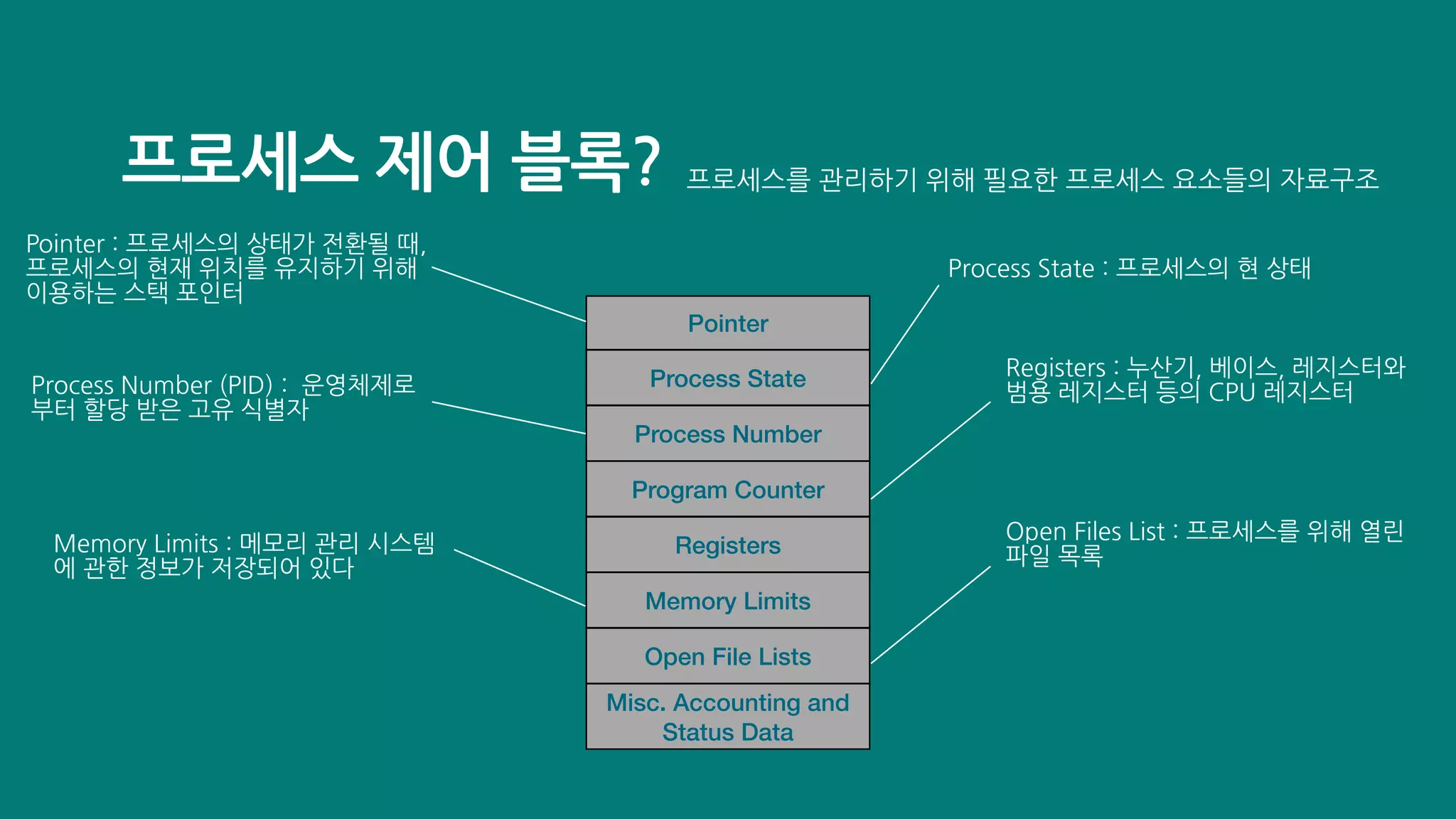
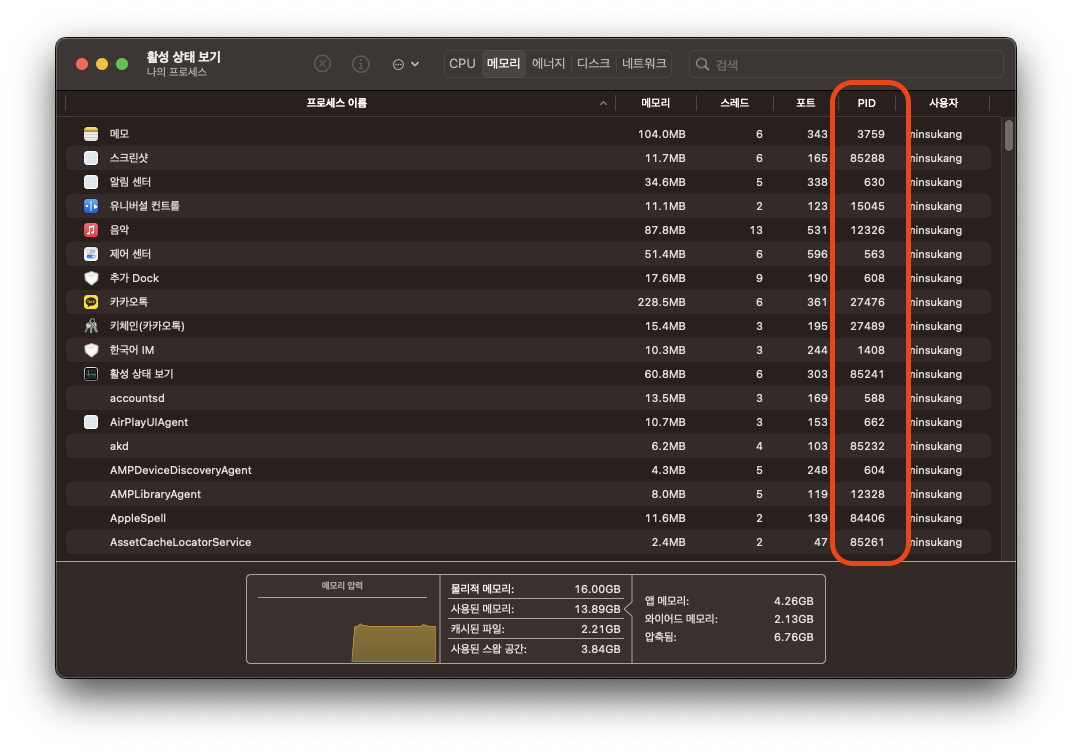
- Process Id : PID는 특정 프로세스를 식별하기 위해 부여하는 고유한 번호입니다. 마치 학교의 학번, 회사의 사번과도 같은 존재입니다. 같은 일을 수행하는 프로그램이라 할 지라도 두 번 실행하면 PID가 다른 두 개의 프로세스가 생성됩니다. 활성상태에서 역시 PID를 확인하실 수 있습니다.
- 레지스터 값 : 프로세스는 자신의 실행 차례가 들어오면, 이전까지 사용했던 레지스터의 중간 값들을 모두 복원합니다. 그래야만 이전까지 진행했던 작업들을 그대로 이어 실행할 수 있습니다. 그래서 PCB 안에는 해당 프로세스가 실행하며 사용했던 프로그램 카운터를 비롯한 레지스터 값들이 담깁니다.
- 프로세스 상태: 현재 프로세스가 어떤 상태인지도 PCB에 기록되어야 합니다. 현재 프로세스가 입출력 장치를 사용하기 위해 기다리고 있는 지, CPU를 사용하기 위해 대기하고 있는 지, 아니면 CPU를 이용하고 있는 지 등의 프로세스 상태가 PCB에 저장됩니다.
- CPU 스케줄링 정보: 프로세스가 언제, 어떤 순서로 CPU를 할당받을 지에 대한 정보도 PCB에 기록됩니다.
- 메모리 관리 정보: 프로세스마다 메모리에 저장된 위치가 다릅니다. 그래서 PCB에는 프로세스가 언제 어느 주소에 저장되어 있는 지에 대한 정보가 있어야 합니다. PCB에는 베이스 레지스터, 한계 레지스터 값과 같은 정보들이 담깁니다. 또한 프로세스의 주소를 알기 위한 또 다른 중요 정보 중 하나인 페이지 테이블 정보도 PCB에 담깁니다. 이와 관련된 내용은 추후 보다 자세히 다루겠습니다. 지금은 PCB에는 프로세의 메모리 주소를 알 수 있는 정보들이 담기는구나 정도로만 이해하시면 좋겠습니다.
- 사용한 파일과 입출력 장치 목록: 프로세스가 실행 과정에서 특정 입출력장치나 파일을 사용하면 PCB에 해당 내용이 명시됩니다. 즉, 어떤 입출력장치가 이 프로세스에 할당되었는 지, 어떤 파일들을 열었는 지에 대한 정보들이 PCB에 기록됩니다.
2) 문맥 교환.
계속 말씀 드렸던 것처럼, 프로세스는 계속 전환되면서 실행됩니다. 그러다 보면 각자 프로세스는 중간 정보의 값을 저장해 두어야만 합니다. 안 그러면 다시 돌아왔을 때, 정보를 잃어버리기 때문입니다.
이러한 중간 정보, 즉 하나의 프로세스 수행을 재게하기 위해 기억해야 할 정보를 문맥이라고 합니다. 하나의 프로세스 문맥은 해당 프로세스의 PCB에 표현되어 있습니다. 따라서 PCB에 기록되는 정보를 문맥이라고 봐도 무방합니다.
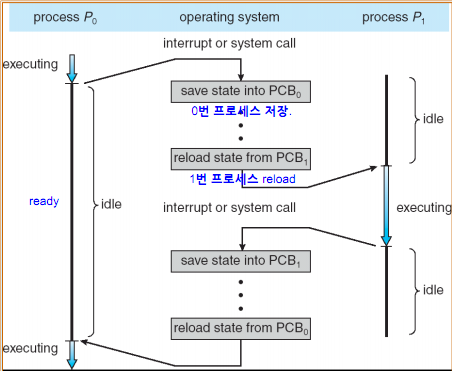
이처럼 기존 프로세스를 PCB에 백업하고, 새로운 프로세스를 실행하기 위해 문맥을 PCB로부터 복구하여 새로운 프로세스를 실행하는 것을 문맥교환이라고 합니다.
3) 프로세스의 메모리 영역.
프로세스가 생성되면 커널영역에 PCB가 생성된다고 말씀드렸습니다. 그렇다면 사용자 영역에는 프로세스는 어떻게 배치될까요?
-
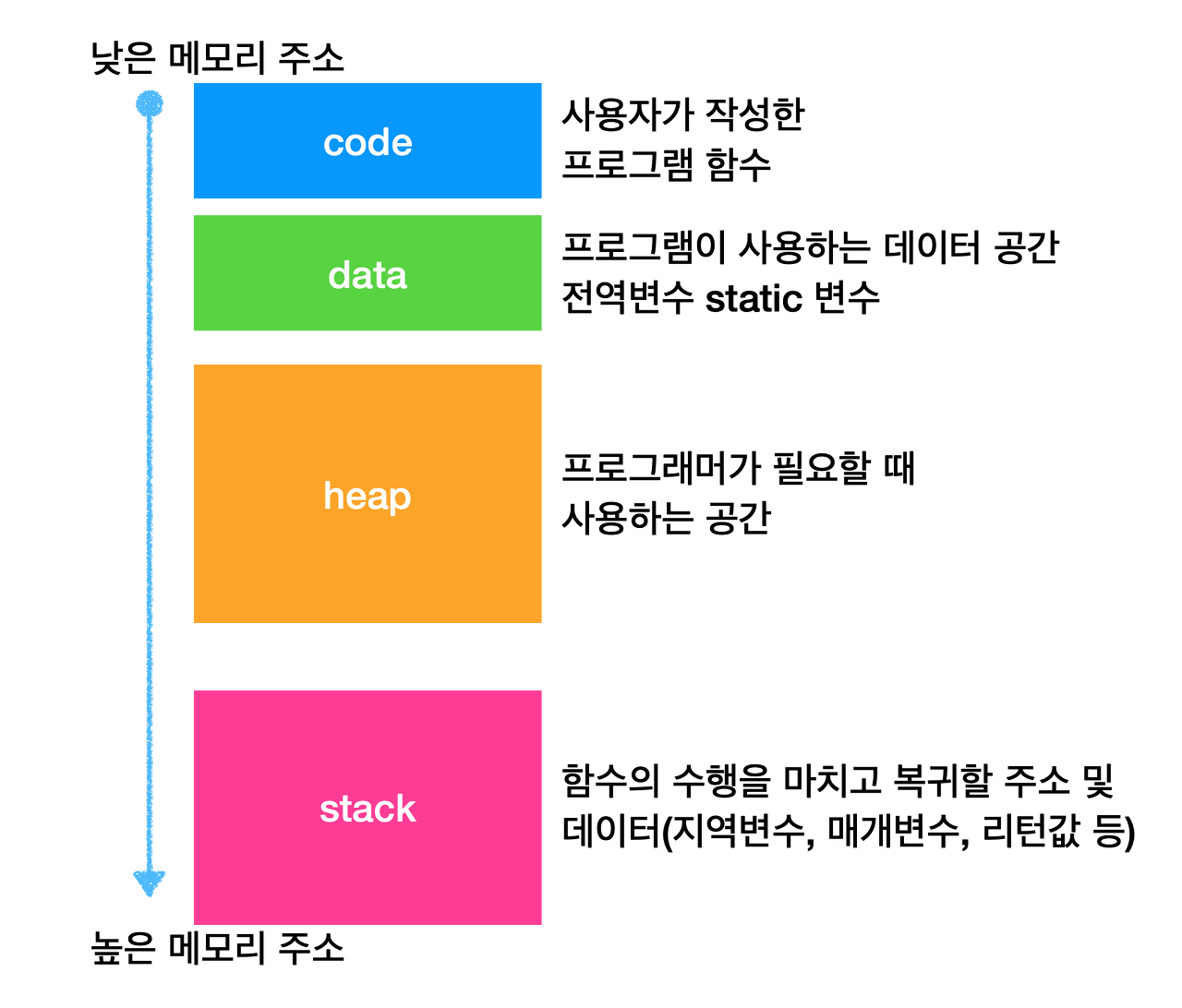
코드 영역
코드 영역은 텍스트 영역이라고도 부릅니다. 이곳에는 말 그대로 실행할 수 있는 코드, 즉 기계어로 이루어진 명령어가 저장됩니다. 코드 영역에는 데이터가 아닌 CPU가 실행할 명령어가 담겨있기 때문에 쓰기가 금지되어 있습니다. 다시 말해 코드 영역은 읽기 전용 공간입니다.
-
데이터 영역
데이터 영역은 잠깐 썼다가 없앨 데이터가 아닌 프로그램이 실행되는 동안 유지할 데이터가 저장되는 공간입니다. 이런 데이터로는 전역 변수가 대표적입니다.
-
힙 영역
힙영역은 프로그램을 만드는 사용자 즉, 프로그래머가 직접 할당할 수 있는 공간입니다. 프로그래밍 과정에서 힙 영역에 메모리 공간을 할당했다면 언젠가는 해당 공간을 반환해야 합니다. 만약 이 공간을 반환하지 않을 경우, 메모리 내에 계속 남아있어 메모리 누수(낭비)를 초래합니다.
-
스택 영역
스택영역은 데이터를 일시적으로 저장하는 공간입니다. 따라서 데이터를 일시적으로 저장하는 공간입니다. 일시적으로 저장할 데이터는 스택 영역에 PUSH되고 더 이상 필요없다면, POP됨으로써 스택 영역에서 사라집니다.
ex) 지역 변수, 매개 변수, 함수 리턴 값 등.
4) 프로세스의 5개 운용 상태.
이번에는 앞서 설명드린 프로세스의 상태에 대해 조금 더 자세히 살펴보겠습니다.
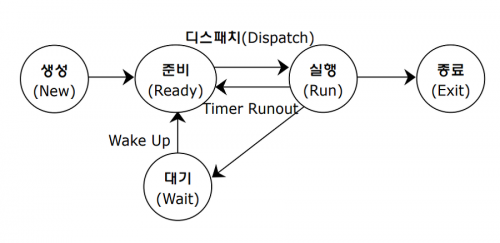
아래 그림과 같이 프로세스는 총 5개의 상태를 가집니다.
- 생성 상태.
먼저, 생성 상태에서는 말 그대로 프로세스를 생성합니다. 이제 막 메모리에 적재되어 PCB를 할당 받은 상태입니다. 생성 상태를 거쳐 실행할 준비가 완료된 프로세스는 곧 바로 실행되지 않고 준비 상태가 되어 cpu의 할당을 기다립니다.
- 준비상태
준비상태는 당장이라도 cpu를 할당 받아 실행할 수 있지만, 아직 자신의 차례가 아니기에 기다리고 있는 상태입니다. 준비 상태 프로세스는 차례가 되면 cpu를 할당 받아 실행 상태가 됩니다.
이때 준비 상태인 프로세스가 실행상태로 전환되는 것을 디스패치라고 합니다.
- 실행 상태.
실행상태는 cpu를 할당 받아 실행 중인 상태를 의미합니다. 실행 상태인 프로세스는 할당된 일정 시간 동안만 cpu를 사용할 수 있습니다. 이때 프로세스가 할당된 시간을 모두 사용하면 다시 준비상태가 되고, 실행 도중 입출력 장치를 사용하여 입출력 장치의 작업이 끝날 때까지 기다려야 한다면 대기 상태가 됩니다.
- 대기 상태.
프로세스는 실행 도중 입출력 장치를 사용하는 경우가 있습니다. 입출력 작업은 cpu에 비해 처리 속도가 느리기에, 입출력 작업을 요청한 프로세스가 입출력 장치가 입출력을 끝날때까지 기다려야 합니다. 이렇게 입출력 장치의 작업을 기다리는 상태를 흔히 대기 상태라고 합니다.
- 종료 상태
종료 상태는 말 그대로 종료가 된 상태입니다. 프로세스가 종료되면 운영체제는 PCB와 프로세스가 사용한 메모리를 정리합니다.
5) 프로세스의 계층 구조.
사실 프로세스의 계층 구조를 통해 다양한 현상들이 나옵니다만, 이번시간에는 간단하게 개념 정도만 짚고 넘어가겠습니다.
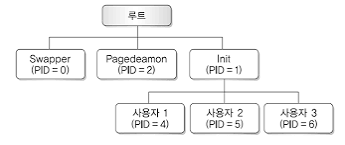
앞서 말씀 드린 프로세스에도 계층이 있습니다.
-
부모 프로세스와 자식 프로세스.
프로세스는 실행 도중 시스템 호출을 통해 다른 프로세스를 생성할 수 있습니다. 이때 새 프로세스를 생성한 프로세스를 부모 프로세스, 부모 프로세스에 의해 생성된 프로세스를 자식 프로세스라고 합니다.
2. 스레드.
다음은 프로세스와 항상 붙어다니는 용어인 스레드입니다.
- 정의.
스레드는 실행의 단위입니다. 조금 더 정확하게 말하면 스레드는 프로세스를 구성하는 실행의 흐름 단위입니다.
💡 즉, 스레드란, 프로세스 내에서 실제로 작업을 수행하는 주체입니다.또, 하나의 프로세스는 여러 개의 스레드를 가질 수 있습니다. 따라서 스레드를 이용하면, 하나의 프로세스에서 여러 부분을 동시에 실행할 수 있습니다.
이런 스레드는 크게 두 가지 동작 원리로 다시 나뉩니다.
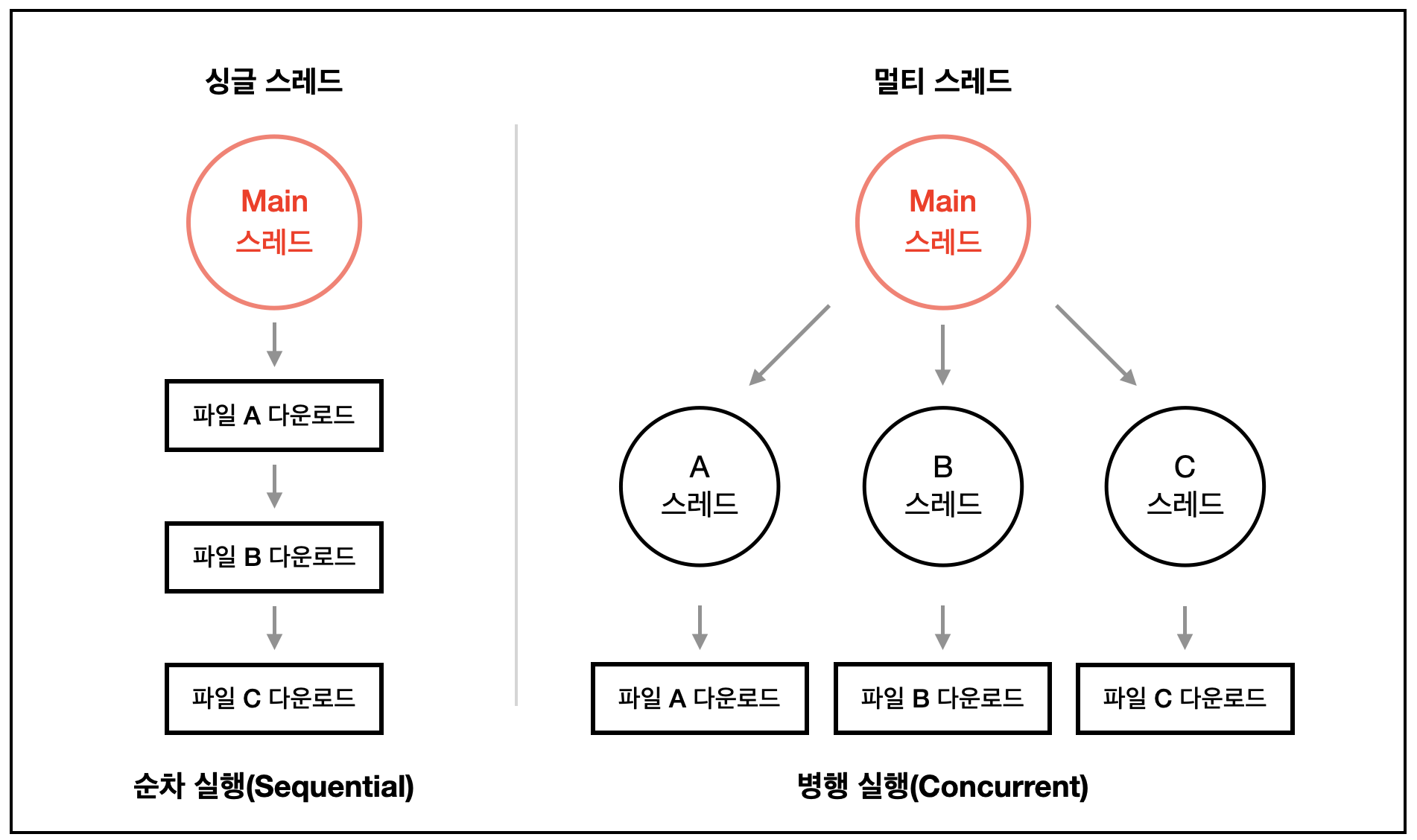
1) 싱글 스레드
싱글 스레드란 하나의 프로그램에서 동시에 하나의 코드만 실행할 수 있다는 뜻입니다.
즉, 싱글 스레드란 코드가 실행되서 끝난 지점과 다음 코드의 시작 지점이 연결된 형태입니다. 각 스레드는 한 번에 하나의 작업만 수행할 수 있습니다. 예를 들어, Task A, B, C가 있다고 치면, 이는 다음처럼 Task A —> Task B —> Task C 순으로 순차적으로 실행됩니다. (이때, 다음 작업을 시작하기 전에 이전 작업을 완료해야합니다.)
이러한, 작동원리로 인해 싱글 스레드는 각기 장 단점이 존재합니다.
싱글 스레드의 장점
1) 자원 접근에 대한 동기화를 신경쓰지 않아도 된다.
여러 개의 스레드가 공유된 자원을 사용할 경우 각 스레드가 원하는 결과를 얻게 하려면 공용 자원에 대한 접근이 통제되어야 하며 이 작업은 프로그래머에게 많은 노력을 요구하고 비용을 발생시킵니다. 하지만, 싱글 스레드 모델에서는 이러한 작업이 필요하지 않습니다.
2) 문맥 교환(context switch) 작업을 요구하지 않는다.
앞서 설명드린 문맥 교환 작업은 프로세스의 하위 실행체인 스레드에도 당연하게 적용됩니다. 만약 멀티 스레드로 처리한다면 문맥교환에 대한 작업을 직접 처리해 줘야만 합니다.
3) 단순히 CPU만을 사용하는 계산작업이라면, 오히려 멀티스레드보다 싱글스레드로 프로그래밍하는 것이 더 효율적이다.
=> a) 두 개의 작업을 하나의 스레드로 처리하는 경우 VS b) 두 개의 스레드로 처리하는 경우
b의 경우는 짧은 시간 동안 2개의 스레드가 번갈아가면서 작업을 수행합니다. 그래서 동시에 두 작업이 처리되는 것과 같이 느끼게 됩니다.하지만, 오히여 두 개의 스레드로 작업한 시간이 싱글스레드로 작업한 시간보다 더 걸릴 수도 있는데, 그 이유는 스레드 간의 작업전환(context switching)에 시간이 걸리기 때문입니다.
다시 말해서, 단순히 CPU만을 사용하는 작업은 싱글 스레드가 멀티 스레드보다 빠릅니다.
따라서 다시 정리해 보면,
프로그래밍 난이도가 쉽고, CPU, 메모리를 적게 사용한다. (코스트가 적게든다) 반면에, 멀티 스레드 모델은 프로그래밍 난이도가 높다. 또한, 스레드 수만큼 자원을 많이 사용한다.
싱글 스레드의 단점
1) 여러 개의 CPU를 활용하지 못한다.
싱글 스레드는, CPU의 성능을 최대한 끌어내지 않는다고 합니다. 즉, 동시 다발적으로 작업을 하지 않으므로, 여러 개의 CPU가 있어도 그 일부의 작업만 수행하게 됩니다.
2)연산량이 많은 작업을 하는 경우, 그 작업이 완료되어야 다른 작업을 수행할 수 있다.
예를 들어, 웹 게임에서 좌표를 계산하는데 3초가 걸리고 계산된 좌표를 받아 DOM에 반영한다고 생각해봅시다. 좌표를 계산하느라 3초간 DOM 업데이트 등의 다른 작업들을 수행할 수가 없습니다. 사용자 입장에서는 3초간 멍하니 기다릴 뿐입니다. 좌표를 동시에 여러 번 계산해야 하는 경우 더 심각해집니다. 좌표를 20번 계산하면 3 * 20 = 60초를 기다려야 하는 셈입니다.3초의 시간은 어쩔 수 없다 치더라도, 계산하는 동안 UI 클릭같은 다른 작업은 진행할 수 있어야 원활한 서비스를 제공할 수 있습니다. 이럴 때는 멀티 스레드가 필요해지는 순간입니다.
3) 싱글 스레드 모델은 에러 처리를 못하는 경우 멈춘다.
싱글 스레드 모델은 에러 처리를 못 하는 경우, 해당 프로그램의 실행이 곧바로 멈춰버리게 됩니다. 이에 반해 멀티 스레드는 다른 스레드에 해당 부분을 이양할 수 있기 때문에 실행이 멈추지 않습니다.
2) 멀티 스레드
다음, 멀티 스레드는 말 그대로 하나의 프로세스를 다수의 실행 단위로 구분하여 하나의 프로그램 안에서도 동시에 여러 개의 일을 수행할 수 있도록 하는 것을 의미 합니다.
멀티 스레드의 장점
- 응답성 : 프로그램의 일부분(스레드)이 중단되거나 긴 작업을 수행하더라도 프로그램의 수행이 계속 되어 사용자에 대한 응답속도가 굉장히 빠릅니다 .
ex) 멀티 스레드가 적용된 웹 브라우저 프로그램에서 하나의 스레드가 이미지 파일을 로드하고 있는 동안, 다른 스레드에서 사용자와 상호작용 가능
- 경제성 : 프로세스 내 자원들과 메모리를 공유하기 때문에 메모리 공간과 시스템 자원 소모가 줄어듭니다. 스레드 간 통신이 필요한 경우에도 쉽게 데이터를 주고 받을 수 있으며, 프로세스의 context switching과 달리 스레드 간의 context switching은 캐시 메모리를 비울 필요가 없기 때문에 더 빠릅니다.
- 멀티프로세서 활용 : 다중 CPU 구조에서는 각각의 스레드가 다른 프로세서에서 병렬로 수행될 수 있으므로 병렬성이 증가합니다.
멀티 스레드의 단점
- 임계 영역(Critical Section)? 둘 이상의 스레드가 동시에 실행하면 문제를 일으키는 코드 블록.
- 공유하는 자원에 동시에 접근하는 경우, 프로세스와는 달리 스레드는 데이터와 힙 영역을 공유하기 때문에 어떤 스레드가 다른 스레드에서 사용 중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽어오거나 수정할 수 있습니다. 따라서 동기화가 필요!
- 물론, 동기화를 통해 스레드의 작업 처리 순서와 공유 자원에 대한 접근을 컨트롤할 수 있습니다. (Java에서
synchronized키워드) 그러나 불필요한 부분까지 동기화를 하는 경우, 과도한 lock으로 인해 병목 현상을 발생시켜 성능이 저하될 가능성이 높기 때문에 주의해야 합니다.
- context switching, 동기화 등의 이유 때문에 싱글 코어 멀티 스레딩은 스레드 생성 시간이 오히려 오버헤드로 작용해 싱글 스레드보다 느립니다.
참고 자료.
https://www.slideshare.net/ssuserd5354e/process-232295835
https://zangzangs.tistory.com/107
https://jhnyang.tistory.com/33
