[React] SpeechSynthesis API를 활용하여 TTS(Text-To-Speech) 구현하기
작년 말에 기념관의 디지털 전시관람 환경 개선 지원 사업의 일환으로 진행된 웹 프로젝트에 참여했다.
해당 서비스는 기념관 내 키오스크 환경(터치 스크린)에서의 동작이 주된 목적인 웹 서비스로, 장애인과 비장애인 모두 이용할 수 있어야 한다는 뚜렷한 목적성을 가지고 있기 때문에, 소장품 설명글을 읽어주는 음성 재생 기능을 구현해야 했다.
프로젝트 초반 기념관 측에서는 각각의 소장품 및 섹션별 페이지에서 재생할 mp3 파일을 직접 생성해 해당 페이지마다 일일이 적용하는 방법으로 구상하고 있었는데, 이 경우 300여개가 넘는 소장품 설명글 및 이외 페이지의 국문, 영문 mp3 파일을 직접 생성하여 각각 적용해야했기 때문에 별도 백 서버 없이 구현되는 서비스인 만큼 서비스가 무거워질 뿐만 아니라 추후 텍스트 수정 발생 시 해당 mp3 파일도 일일이 함께 수정되어야 해야했다. 1차적으로는 휴먼 리소스가 크게 들고, 서비스가 무거워질 뿐만 아니라 유지보수 측면에서도 좋지 않다고 판단했다.
대안을 찾아보던 중 웹 브라우저의 SpeechSynthesis API를 활용해 텍스트를 음성으로 재생해주는 TTS(Text-To-Speech) 기능에 대해 알게되었고, 해당 기능을 도입해보고자 했다.
TTS(Text-To-Speech)란?
텍스트 음성 변환 기능으로, 입력된 text를 읽어 음성으로 재생해주는 기능이다. 시각 장애를 가지고 있거나 글을 읽지 못하는 사람들이 text를 들을 수 있게 해주는 중요하고 필수적인 기능이다.
SpeechSynthesis API
SpeechSynthesis는 Web Speech API의 하나로 주어진 텍스트를 소리로 바꿔주는 TTS API이며, 사전적 의미로는 ‘음성 합성’이라는 뜻을 가지고 있다. 브라우저에 내장된 API로, 무료로 쉽게 사용할 수 있어 이번 기능 구현에 활용하기로 결정했다.
메서드와 프로퍼티 종류
메서드
getVoices(): speechSynthesis 인터페이스의 메서드로 현재 사용하고 있는 디바이스의 사용 가능한 목소리들을 가지고 올 수 있다.speak(): utterance(speech)를 utterace queue에 쌓아 음성으로 읽을 수 있도록 한다.resume():SpeechSynthesis 객체를 일시 중지되지 않은 상태로 전환한다.pause(): SpeechSynthesis 개체를 일시 중지된 상태로 전환한다.cancel(): utterance queue에서 모든 utterance를 제거한다.
프로퍼티
lang: 사용할 언어. 기본값은 lang 값 또는 user-agent default 값이 된다.pitch: 스피치의 pitch. 기본값 1. 0-2 사이로 설정 가능하다.rate: 스피치의 속도. 기본값 1. 0.1-10 사이로 설정 가능하다.voice: 스피치의 목소리. 설정되지 않으면 utterance 언어의 default 언어 세팅 목소리로 설정된다.
기능 구현하기
조건
기념관에서 요구하는 조건은 다음과 같았다.
✔️ 소장품 설명 및 화면 description을 국문/영문 음성으로 재생해야 한다.
✔️ 텍스트 내 한자어, 또는 괄호 내 텍스트는 제외하고 읽혀야 한다.
✔️ 음성으로 재생할 스크립트에는 5문장 이상의 긴 문단도 포함된다.
✔️ 유료 버전은 사용할 수 없다.
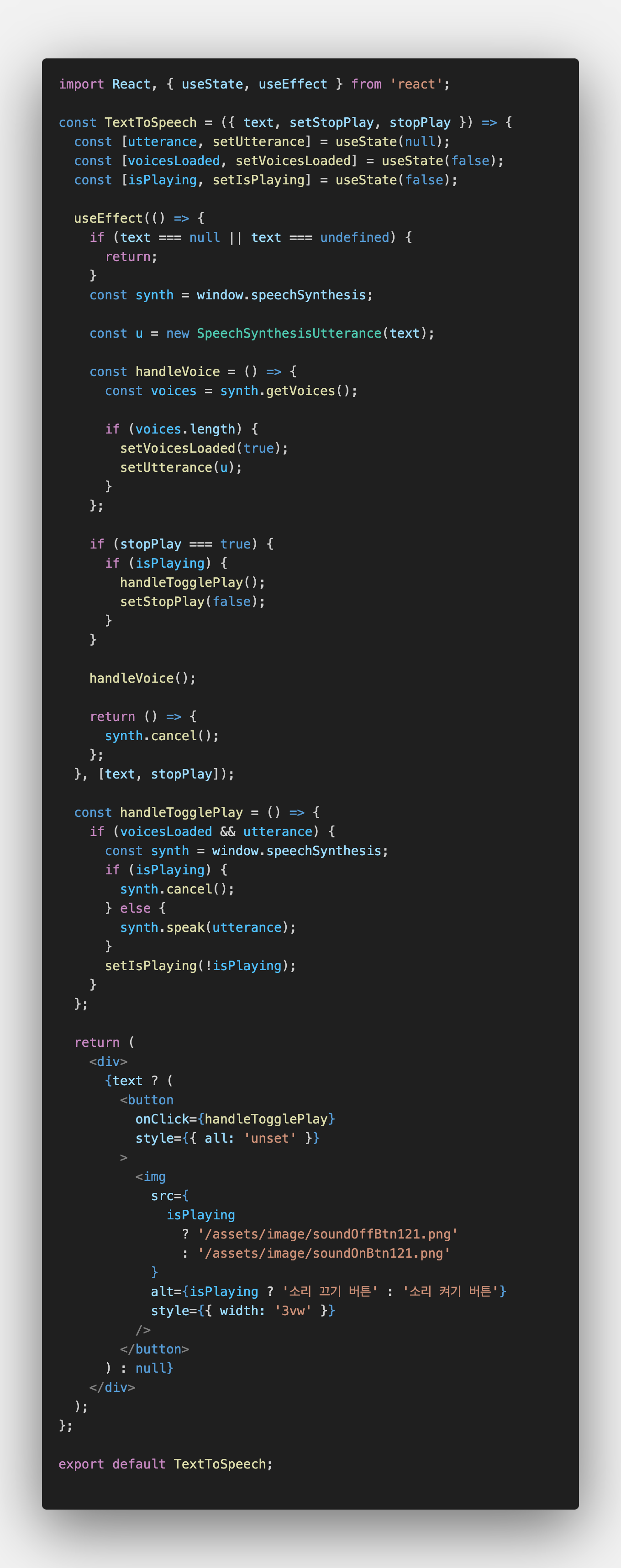
01. SpeechSynthesis 함수로 기능 구현하기
SpeechSynthesis의 함수를 이용하여 토글 버튼으로 TTS를 재생하는 기능을 구현했다.
02. 알맞은 voice 찾기
기능은 구현했는데, 목소리가 부자연스럽다...!
먼저, voice 종류와 인덱스를 알아보기 위해 getVoices() 후 콘솔에 찍어보았다.
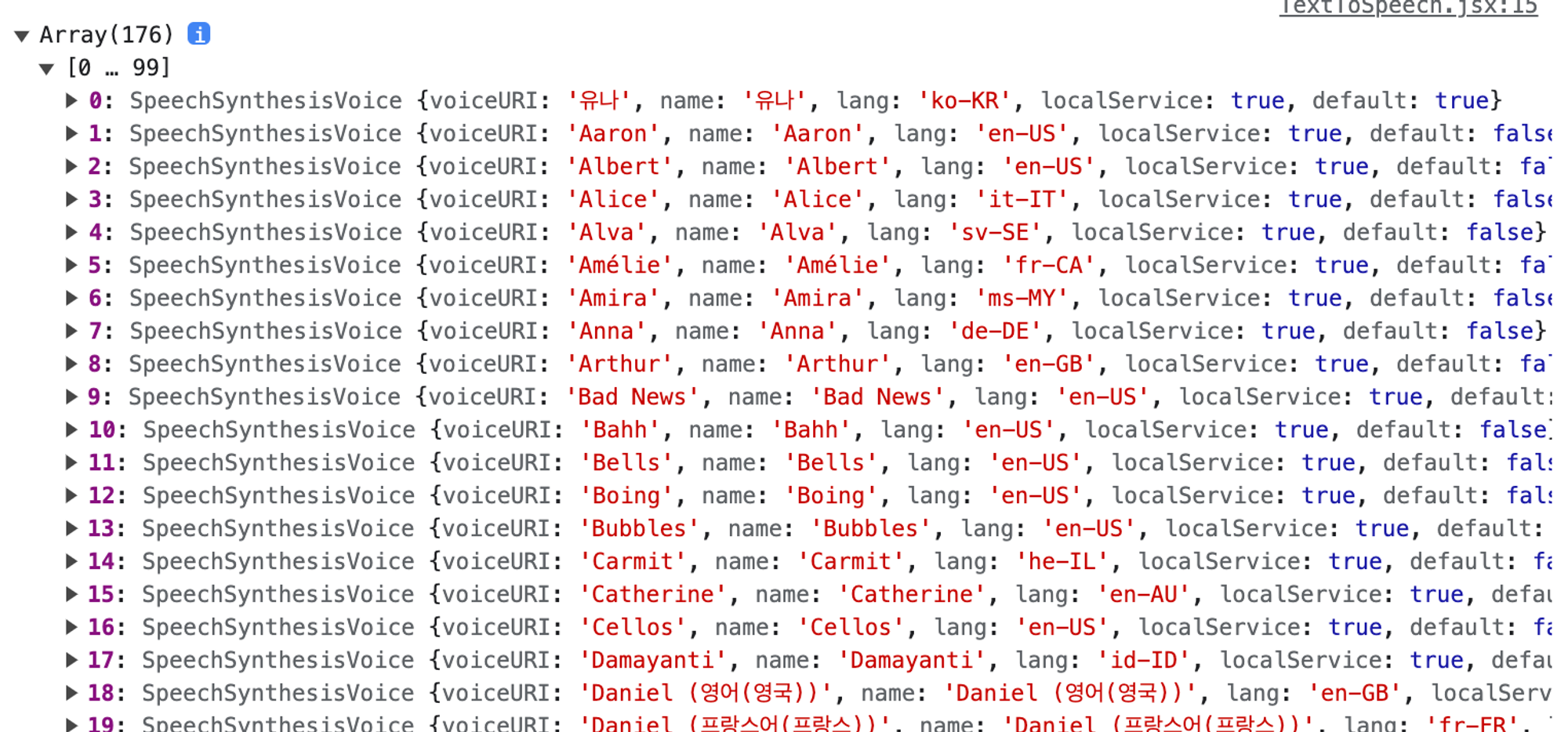
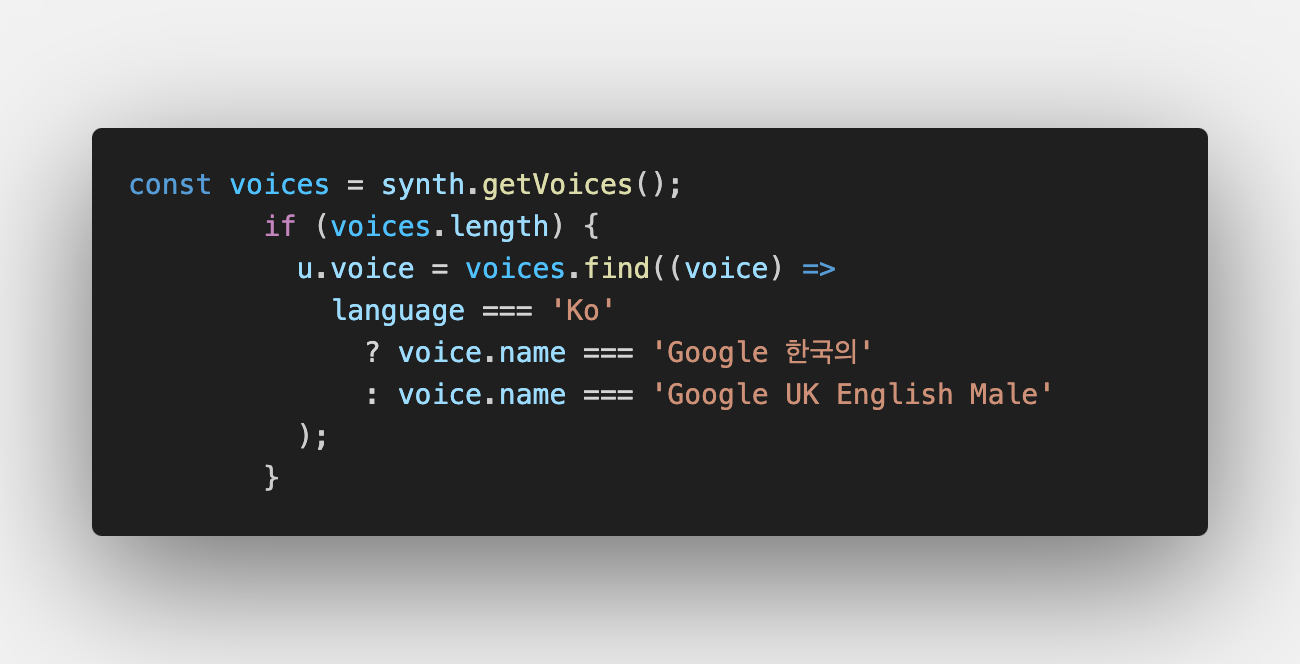
국문 전용 voice(lang이 'ko-KR'인 음성)에는 '유나'와 'Google 한국의'라는 name을 가진 2개의 voice가 있었다.
기본 세팅은 '유나'로 되어 있었는데, 두 개를 비교해보고 보다 자연스러운 음성으로 발화되는 'Google 한국의' 음성을 채택했다. (추천!)
영문 음성의 경우 'Google UK English Male'을 선택했다.
03. 텍스트 다듬기
박물관에 전시된 소장품에 관련된 설명글이 포함되어 있다보니, 괄호 및 한자어가 쓰이는 부분이 제법 있었다. 자연스럽게 읽히기 위해 정규 표현식을 활용해 음성 재생 시 괄호 내에 기재된 텍스트나, 한자어를 제외하고 재생하도록 했다.

04. 재생 도중 멈춤 이슈 해결하기
위 3번까지 진행 후 기능 구현이 완료되었다고 생각했는데,기능 테스트 중 문장의 길이가 긴 텍스트는 끝까지 읽히지 않고 중간에 멈춰버리는 현상이 발견되었다.
조사한 결과 해당 현상은 SpeechSynthesis API가 가지고 있는 자체적인 문제로 판단되었다.(참고 Link)
찾아본 글에서 utterance 를 전역 변수에 저장하면 해결할 수 있다고 되어있어 시도해 보았는데 잘 되지 않아 급한대로 다른 대안을 생각해보았고, 그 대안은 텍스트를 마침표 기준으로 여러개의 chunk로 분리해 이어 재생하는 것이었다.
4-1.
먼저 넘겨받은 텍스트를 마침표, 느낌표, 물음표를 기점으로 분리했다.
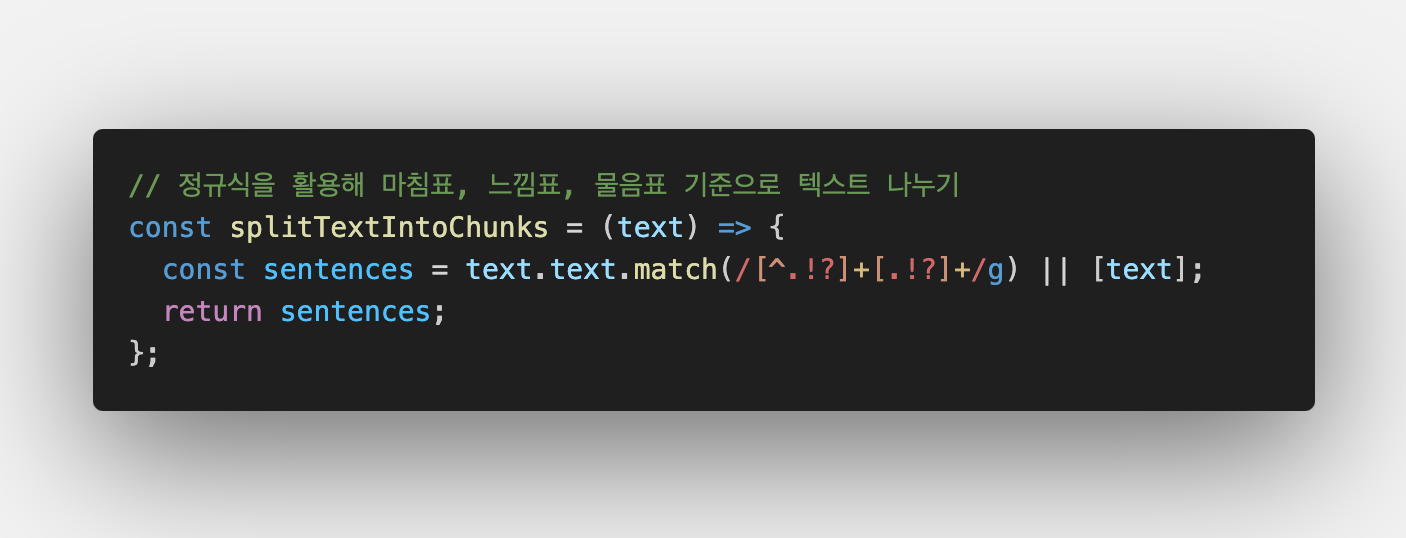
예를 들어 "안녕. 오늘 좀 어때? 날씨 정말 좋다!" 라는 텍스트가 주어진다면, 해당 텍스트는 아래 배열로 반환된다.
["안녕.", "오늘 좀 어때?", "날씨 정말 좋다!]
4-2.
위 배열을 매개변수로 받는 speakChunks 함수를 만들었다.
그리고 해당 함수 안에는 배열 내의 문장들을 차례대로 재생하는 재귀 함수 speakChunk 를 만들어 여러 문장으로 나눈 텍스트가 하나씩 재생되도록 구현했다.
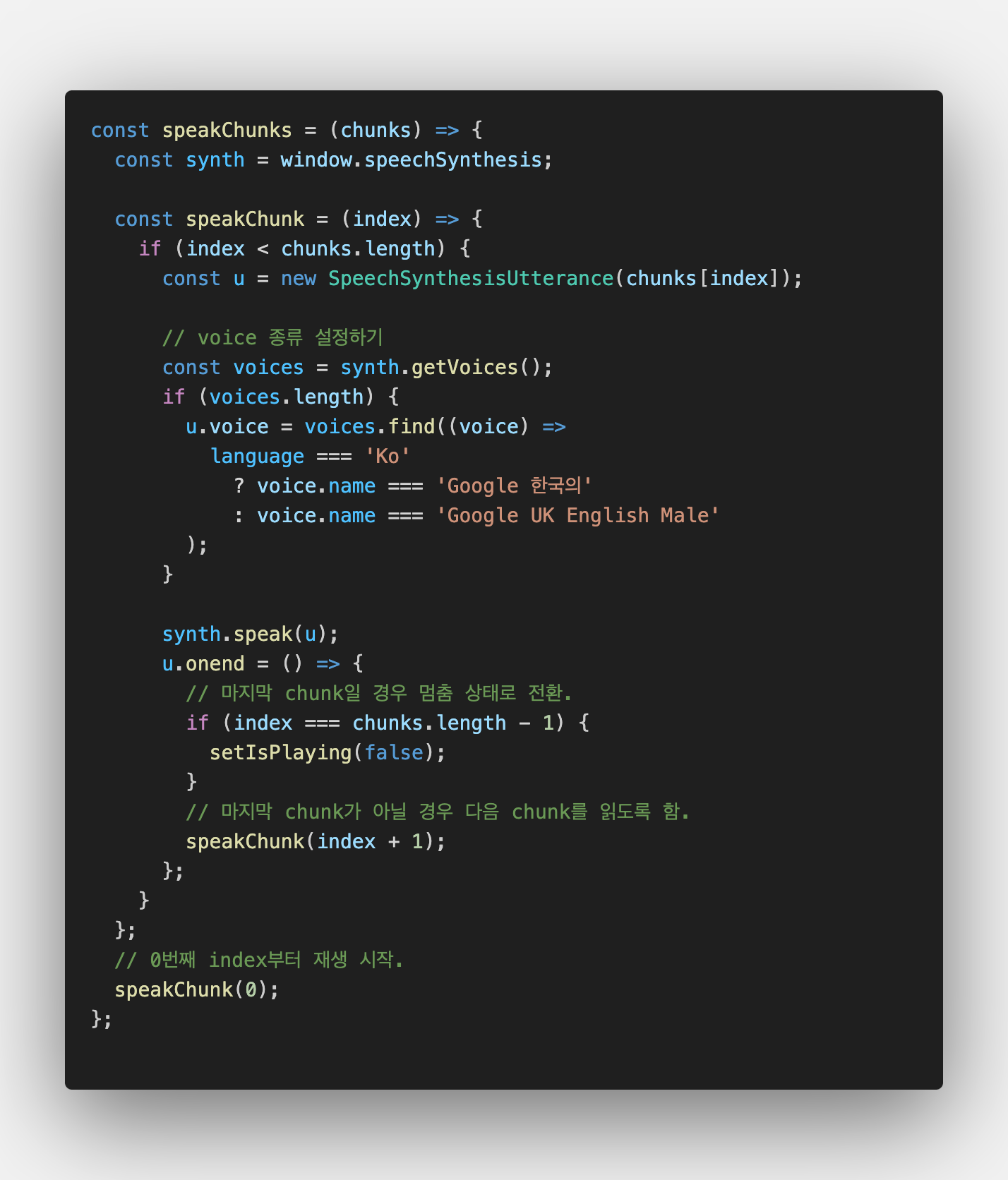
그러나 하나의 문장 자체가 너무 긴 경우엔 문장 자체를 다듬어야 했기에 완전하게 해결했다고 보기는 어려웠다.
이 부분은 추후 새롭게 보완해야 할듯하다.
결과물
의도한 대로 구현이 완료되었다.
아쉬운 점은 아래와 같이 정리해 볼 수 있겠다.
-
최대한 매끄러운 보이스를 적용했으나 유료 음성 api만큼의 자연스러운 발화가 되지 않는 점.
-
텍스트를 문장 기준으로 나누어 재생했으나 문장 자체가 길 경우 재생이 멈추는 이슈는 여전히 발생한다는 점.(전역 변수에 저장하여 사용하는 방법을 고민해봐겠다.)
여건이 된다면 네이버에서 제공하는 CLOVA Speech Synthesis (CSS) 등 성능이 좋은 유료 api를 사용하는 것이 좋을 수 있으나, 그렇지 않다면 브라우저에서 자체 제공하는 해당 api를 잘 활용해 보는 것도 방법인 것 같다.
오페라, 웹뷰 안드로이드 등 호환되지 않는 브라우저도 있으니 브라우저 호환성도 꼭 체크하면 좋겠다.
참고 자료
