Proxy
Forward Proxy
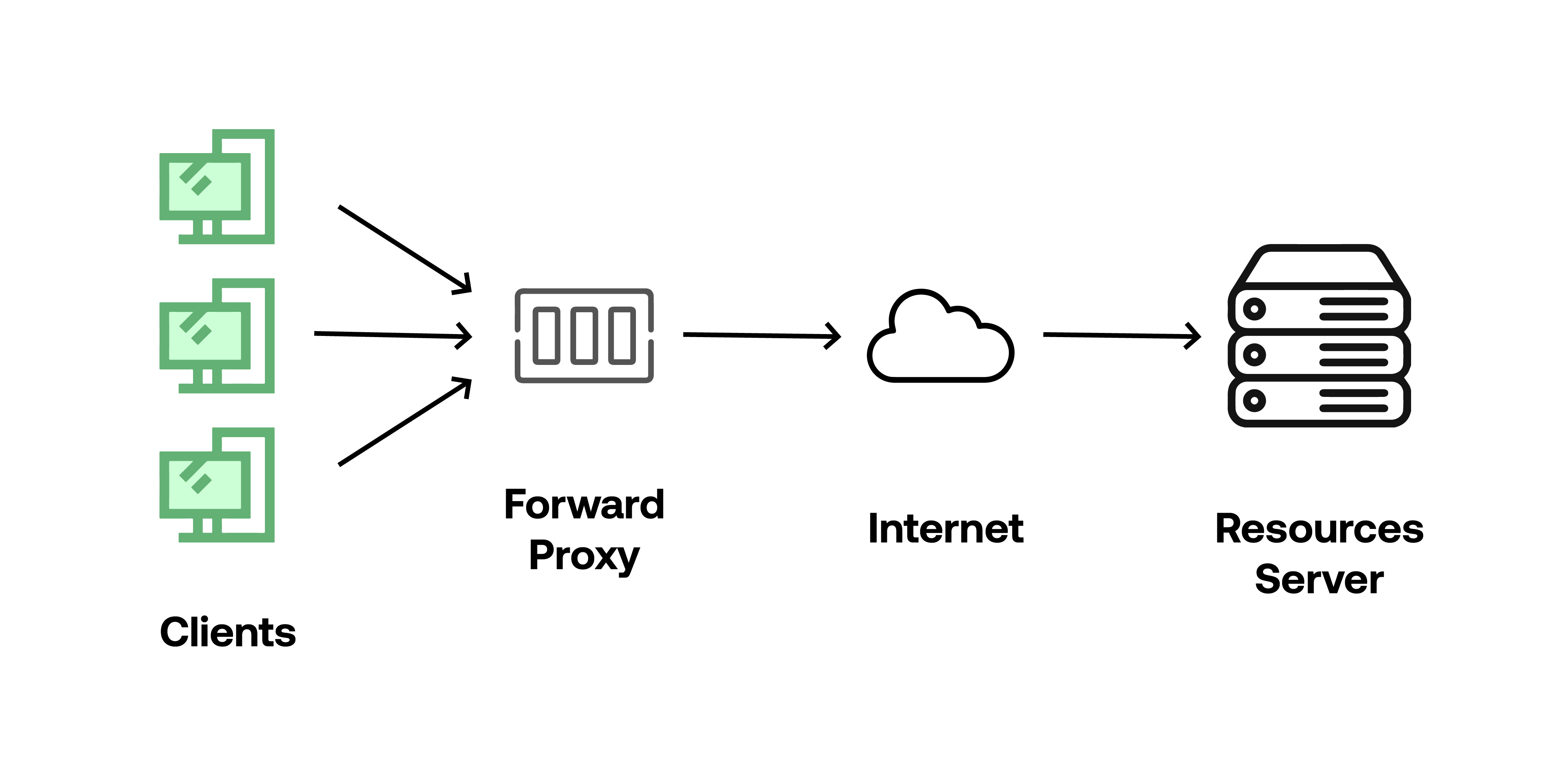
Forward Proxy는 클라이언트 가까이에 위치한 프록시 서버로 클라이언트를 대신해 서버에 요청을 전달해준다.
주로 캐싱을 제공하는 경우가 많아 사용자가 빠른 서비스를 이용할 수 있도록 돕는다.
장점
-
캐싱을 통해 빠른 서비스 이용 가능
클라이언트는 서비스의 서버가 아닌 프록시 서버와 소통하게 된다, 그런 과정에서 여러 클라이언트가 동일한 요청을 보내는 경우 첫 응답을 하며 결과 데이터를 캐시에 저장한 후, 서버에 재 요청을 보내지 않아도 다른 클라이언트에게 빠르게 결과를 전달해준다.
-
보안
클라이언트에서 프록시 서버를 거친 후 서버에 요청이 도착하기 때문에, 서버에서 클라이언트 IP 추적이 필요한 경우 클라이언트 IP가 아닌 프록시 서버의 IP를 전달한다.
서버가 응답받은 IP는 프록시 서버의 IP이기 때문에 서버에게 클라이언트를 숨길수 있다.
Reverse Proxy
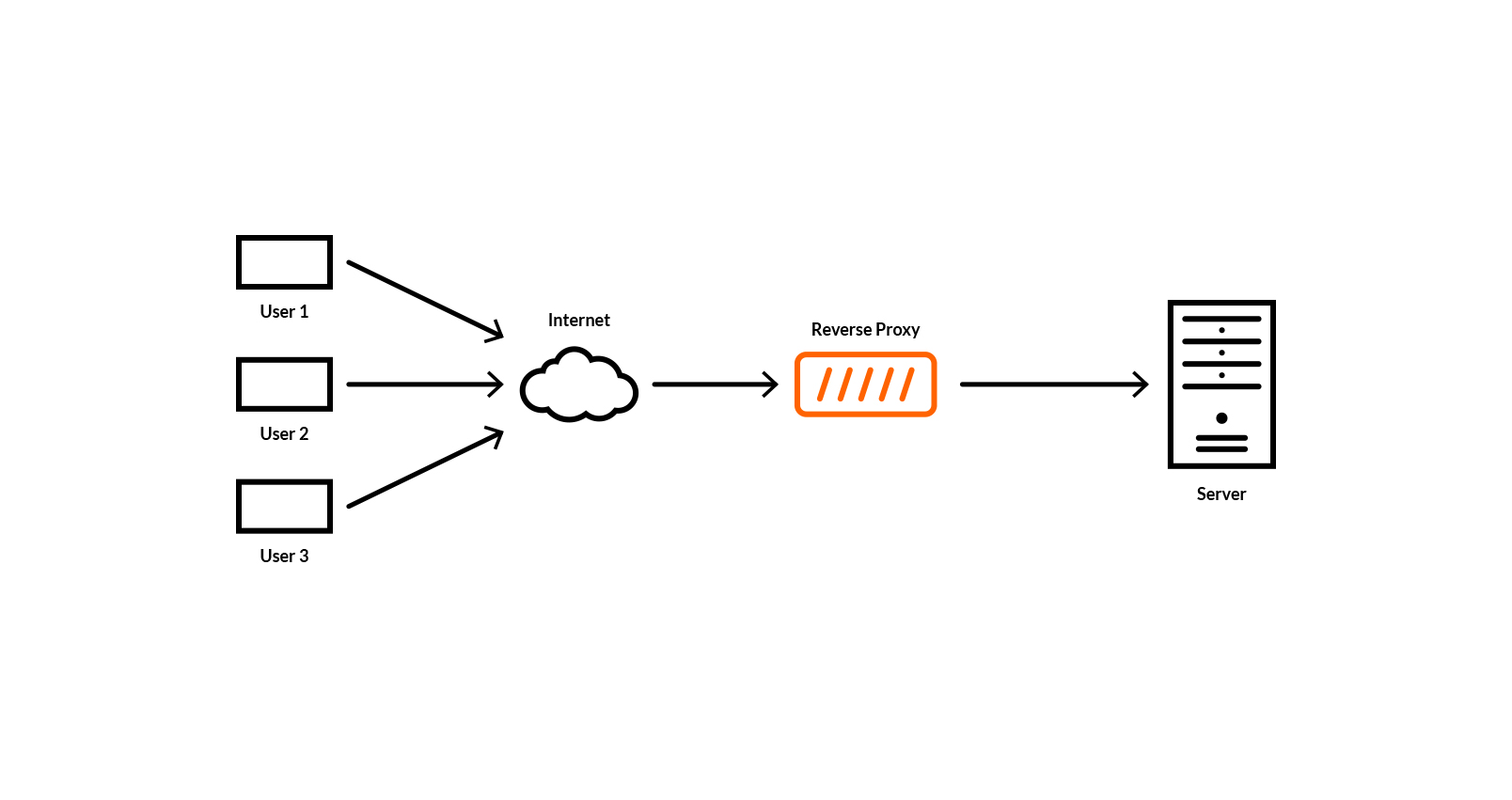
Reverse Proxy는 Forward와 반대로 서버 가까이에 위차한 프록시 서버를 대신해서 클라이언트에 응답을 제공한다, 분산처리를 목적으로 하거나 보안을 위해 프록시 서버를 이용한다
장점
-
분산처리
클라이언트 - 서버 구조에서 사용자가 많아져 서버에 과부하가 올 경우를 위해 부하를 분산할 수 있다.
Reverse Proxy 구조에서 프록시 서버로 요청이 들어오면 여러 대의 서버로 요청을 나누어 전달 후 처리한다. -
보안
Forward 와 반대로 Reverse Proxy는 클라이언트에게 서버를 숨길 수 있다, 클라이언트 입장에서의 요청을 보내는 서버가 프록시 서버가 되므로 실제 서버의 IP주소가 노출 되지 않는다.
Load Balancer
서비스에 너무 많은 사용자가 접속하거나, 하나의 서버에 너무 많은 혹은 너무 잦은 요청이 들어온다면 서버에는 과부하가 오게 된다.
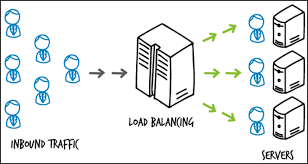
그래서 2가지 방법으로 문제를 해결하는 방법이 있다
Scale-Up
스케일-업은 물리적으로 서버의 사양을 높이는 하드웨어적인 방법이다.
서버의 수를 늘리지 않고 프로그램 구현에 있어 변화가 필요없다는 장점을 가지고있다.
하지만 서버의 사양을 높이는데 굉장히 높은 비용이 필요하고, 하드웨어의 업그레이드엔 한계점이 존재하는 큰 단점을 안고있다.
근본적으로 업그레이드를 하더라도 클라이언트의 요청이 더 많아지면, 서버에 발생하는 부하를 여전히 해결하지 못한다
Scale-Out
스케일-아웃은 서버의 갯수를 늘려 하나의 서버에 줄 부하를 분산시키는 방법이다.
많은 요청이 오더라도 여러대의 서버가 나눠서 처리하기 때문에 서버의 사양을 높이지 않고도 비교적 저렴하게 부하를 해결하는 방법이다
스케일 아웃 방법으로 여러 대의 서버로 부하를 처리하는 경우, 클라이언트로부터 온 요청을 여러 서버 중 어느 서버에 보내서 처리해야 할까?
요청을 여러 서버에 나눠 처리할 교통정리를 해줄 역할이 필요한데 이것이 바로 로드 밸런서 이며, 여러 서버에 정리해주는 기술 혹은 프로그램을 로드 밸런싱이라 한다.
로드 밸런서의 종류
-
L2: 데이터 전송 계층에서 Mac 주소를 바탕으로 로드 밸런싱 한다.
-
L3: 네트워크 계층에서 IP 주소를 바탕으로 로드 밸런싱 한다.
-
L4: 전송 계층에서 IP주소와 Port를 바탕으로 로드 밸런싱 한다.
-
L7: 응용 계층에서 클라이언트의 요청을 바탕으로 로드 밸런싱 한다.
AutoScaling
오토스케일링이란?
서버의 과부하를 분산시키기 위해 로드 밸런싱을 사용하는데, 서버가 언제 부하가 오고 언제 추가해야할지 사람이 쭉 지켜보다가 서버의 부하가 심해져 제대로 된 서비스를 제공하지 못하는 순간까지 기다릴순 없으니 갑작스러운 문제 등의 취약하다.
이런 상황을 오토스케일링을 통해 간편히 해결이 가능하다.
오토스케일링은 Scale-Out 방식으로 서버를 증설할 때 자동으로 서버를 관리해주는 기능이다
클라이언트의 요청이 많아져 서버의 처리 요구량이 증가하면 새 리소스를 자동으로 추가해주며, 반대의 상황 요구량이 적어지면 리소스를 감소시켜 적절한 분산 환경을 만들어준다.
장점
-
동적 스케일링
오토스케일링의 가장 큰 장점은 사용자의 요구 수준에 따라 리소스를 동적으로 스케일링 할 수 있다는 점이다.
스케일 업 할수있는 서버의 수에는 제한이 없고, 필요한 경우 서버 두 대에서 ~ 수 만대의 서버로 즉시 스케일 업이 가능하다. -
로드 밸런싱
리소스를 동적으로 스케일업 혹은 스케일-다운 한다, 로드 밸런서와 함께 사용한다면 다수의 EC2 인스턴스에게 워크로드를 효과적으로 분배할 수 있어 사용자가 정의한 규칙에 따라 워크로드를 효과적으로 관리 할 수 있다.
-
타겟 트래킹
사용자는 특정 타겟에 대해서만 오토스케일링을 할 수 있으며, 사용자가 설정한 타겟에 맞춰 EC2 인스턴스의 수를 조정한다.
-
헬스 체크와 서버 플릿 관리
오토스케일링을 이용하면 EC2 인스턴스의 헬스 체크 상태를 모니터링 할 수 있다.
만일 헬스 체크를 하는 과정에 특정 인스턴스에 문제가 감지되면, 자동으로 다른 인스턴스로 교체한다.
다수의 EC2 서버에서 애플리케이션을 호스팅 하는 경우, 이들 이련의 EC2 서버 집합을 AWS는 서버 플릿이라 부른다.
오토스케일링은 적정 수준의 서버 플릿 용량을 유지하는 데 도움을 준다
ex) 한 기업의 애플리케이션 6대의 EC2 서버에서 실행 중 일때 6대 서버에 대한 헬스 체크 상태를 모니터링 하다가 특정 서버에 문제가 생기면 즉시 대응 조치를 할 수 있다, 한 대 또는 그 이상의 서버가 다운 되면 오토스케일리은 6대의 서버 인스턴스 처리 용량을 유지하기 위해 부족분 만큼의 서버를 추가로 실행시키는 방식으로 서버 플릿을 유지한다.
EC2 오토스케일링 활용
시작 템플릿 (Launch Configuration)
오토스케일링으로 인스턴스를 확장 또는 축소하려면 어떤 서버를 사용할지 결정해야 하는데, 이는 시작 템플릿을 통해서 가능하고, AMI 상세정보, 인스턴스 타입, 키 페어, 시큐리티 그룹 등 인스턴스에 대한 모든 정보를 담고 있다.
만약 시작 템플릿을 사용하고 있지 않고 시작 템플릿을 생성하지 않으려는 경우엔 대신 시작 구성을 생성할 수 있다.
시작 구성은 EC2 오토스케일링 사용자를 위해 생성하는 EC2 인스턴스 유형을 지정한다는 점에서 시작 템플릿과 비슷하며, 사용할 AMI의 ID, 인스턴스 유형, 키 페어, 보안 그룹 등의 정보를 포함시켜 시작 구성을 생성한다
오토스케일링 그룹 생성
오토스케일링 그룹은 스케일업 및 스케일 다운 규칙의 모음으로 EC2 인스턴스 시작부터 삭제까지의 모든 동작에 대한 규칙과 정책을 담고있다.
(오토스케일링 그룹 생성을 위해선 스케일링 정책 및 유형을 잘 숙지하고 있어야한다.)
Scaling 유형
-
인스턴스 레벨 유지
기본 스케일링 계획으로도 불리며, 항상 실행 상태를 유지하고자 하는 인스턴스의 수를 지정할 수 있다, 일정한 수의 인스턴스가 필요한 경우 최소, 최대 및 원하는 용량에 동일한 값을 설정할 수 있다.
-
수동 스케일링
기존 오토스케일링 그룹의 크기를 수동으로 변경할 수 있다, 사용자가 직접 콘솔이나 API,CLI등을 이용해 수동으로 인스턴스 추가,삭제 해야하는 방법으로 추천하지 않는 방법
-
일정별 스케일링
예측 스케일링트래픽의 변화를 예측할 수 있으며, 특정 시간대에 어느 정도의 트래픽이 증감하는 패턴을 파악했다면 일정병 스케일링을 사용하는 것을 추천한다, 어느 시간대에는 트래픽이 최고치에 이르고 다른 시간대에는 트래픽이 거의 없다면 해당 시간에 맞춰 서버를 증설 혹은 스케일 다운 시키는 규칙을 추가하면 된다.
-
동적 스케일링
수요 변화에 대응해 오토스케일링 그룹의 용량을 조정하는 방법을 정의하며, 이 방식은 CloudWatch가 모니터링 하는 지표를 추적하여 경보 상태일 때 수행할 스케일링 규칙을 정한다.
예를 들면 CPU 처리 용량의 80% 수준까지 급등한 상태가 5분 이상 지속될 경우 오토스케일링 작동돼 새 서버를 추가하는 방식이다
이런 스켈일링 정책을 정의할 땐 항상 스케일 업과 스케일 다운의 대한 두 가지 정책을 작성해야 한다.
