웹개발종합반 3주차
1주차는 HTML과 CSS를 통해 웹페이지의 화면이 어떻게 구현되는지 살펴보는 내용이 주였고, Javascript를 간단하게 맛을 보았어요.
2주차는 익숙해진 Javascript 문법을 통해 jQuery를 사용하는 방법을 간단하게 배워 HTML을 조작하는 방법과 더 나아가서 jQuery를 이용해서 만들어진 Ajax 프레임워크로 클라이언트에서 서버에 데이터를 요청하는 방법을 배웠죠. 이 때 openAPI를 이용해서 GET요청을 실습하면서 클라이언트와 서버의 통신에 대해서 조금이나마 감을 잡을 수 있었어요.
1주차와 2주차가 클라이언트 쪽에 대한 내용이었다면 3주차부터는 점차 서버 쪽으로 넘어갔어요. 여러 언어를 사용할 수 있겠지만 웹개발종합반 강의에서는 파이썬을 통해 서버를 구현하는 것을 보여주었어요.
3주차 수업내용으로는 먼저 2주차에서 배운 Ajax를 토대로 요청을 통해 어떻게 데이터를 크롤링(웹스크래핑)하는지에 대해서 실습을 했죠. 예를 들어서 기상청 사이트의 openAPI를 통해 얻을 수 있는 정보들을 어떻게 웹 화면에서 볼 수 있게 하는지를 실습한 것이죠. 그리고 mongoDB를 통해 DB에 대해서 살펴보았어요. DB에 연결하고 어떻게 조작하고 저장하는지 등을 실습했어요. 이 포스팅에서는 3주차 수업 중 개인적으로 기록해놓고 싶은 내용들을 작성해볼게요.
4, 5주차까지 가면 클라이언트와 서버, 도메인 생성과 배포까지 모든 과정을 간단하게 실습하게 되는데, 그 후에 웹어플리케이션의 작동과 만들어지는 과정을 전체적으로 한번 정리해 볼 예정이에요.
◾3-6. 파이썬 패키지 설치하기
-
파이썬 패키지(package)
-
👉 패키지? 라이브러리? →
Python 에서 패키지는 모듈(일종의 기능들 묶음)을 모아 놓은 단위입니다. 이런 패키지 의 묶음을 라이브러리 라고 볼 수 있습니다. 지금 여기서는 외부 라이브러리를 사용하기 위해서 패키지를 설치합니다.즉, 여기서는 패키지 설치 = 외부 라이브러리 설치!
-
-
pip(python install package) 사용 - requests 패키지 설치
import requests # requests 라이브러리 설치 필요 r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair') rjson = r.json() gus = rjson['RealtimeCityAir']['row'] for gu in gus: if gu['IDEX_MVL'] < 60: print (gu['MSRSTE_NM'], gu['IDEX_MVL'])requests라이브러리를 설치하면 openAPI의 URL을 통해서 데이터를 받는 요청을 보낼 수 있게 되고, for문 등을 활용해서 데이터를 조작할 수 있게되죠.
(Requests: HTTP 요청을 보낼 수 있도록 기능을 제공하는 라이브러리 입니다.)
openAPI 처럼 JSON형식으로 처음부터 잘 정리되어 있다면 좋겠지만, 만약 받아오려는 데이터가 따로 정리되어 있지 않다면 어떻게 할까요?
▶️ HTML 요소를 잘 조작한다면 원하는 데이터를 얻을 수 있을 거에요. 이를 위해서 웹 사이트를 구성하는 텍스트 정보를 HTML로 인식하게 하고, 그 후에 HTML요소를 selecting 할 수 있도록 도와주는
BeautifulSoup이라는 라이브러리를 설치했어요.
(BeautifulSoup: 웹 페이지의 정보를 쉽게 스크랩할 수 있도록 기능을 제공하는 라이브러리입니다.)
◾3-8. 웹스크래핑(크롤링) 기초
-
BeautifulSoup을 사용해서 웹스크래핑하기- 먼저 pip를 사용해서 bs4 패키지를 설치해줍니다.
-
그 후 크롤링에 필요한 기본 세팅을 합니다.
import requests from bs4 import BeautifulSoup # 타겟 URL을 읽어서 HTML를 받아오고, headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver? sel=pnt&date=20210829',headers=headers) # HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦 # soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨 # 이제 코딩을 통해 필요한 부분을 추출하면 된다. soup = BeautifulSoup(data.text, 'html.parser') ############################# # (입맛에 맞게 코딩) ############################# -
HTML selector 선택
# 선택자를 사용하는 방법 (copy selector) soup.select('태그명') soup.select('.클래스명') soup.select('#아이디명') soup.select('상위태그명 > 하위태그명 > 하위태그명') soup.select('상위태그명.클래스명 > 하위태그명.클래스명') # 태그와 속성값으로 찾는 방법 soup.select('태그명[속성="값"]') # 한 개만 가져오고 싶은 경우 soup.select_one('위와 동일') -
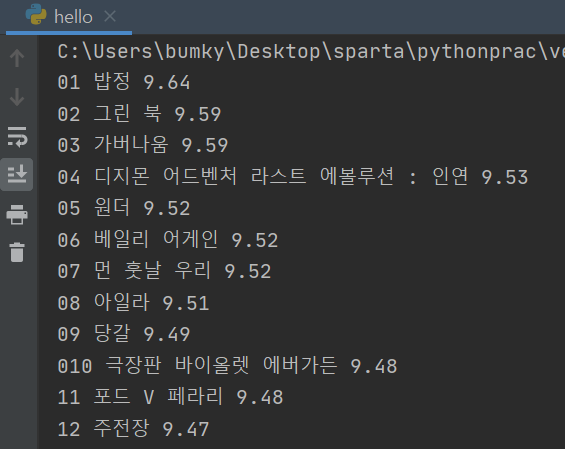
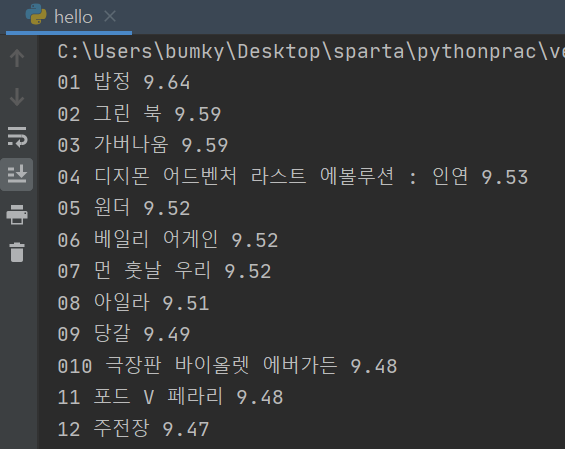
완성코드와 출력
- 완성코드
import requests from bs4 import BeautifulSoup headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver? sel=pnt&date=20210829',headers=headers) soup = BeautifulSoup(data.text, 'html.parser') #old_content > table > tbody > tr:nth-child(3) > td.title > div > a #old_content > table > tbody > tr:nth-child(4) > td.title > div > a movies = soup.select('#old_content > table > tbody > tr') for movie in movies: a = movie.select_one('td.title > div > a') if a is not None: title = a.text rank = movie.select_one('td:nth-child(1) > img')['alt'] star = movie.select_one('td.point').text print(rank, title, star)- 출력결과
◾3-10. DB개괄
1) 들어가기 전에 - DB는 왜 쓰는 것일까?
👉 우리가 방 정리를 하는 이유는 무엇일까?
- 1번: 잘 넣어두기 위해서 / 2번: 나중에 잘 찾기 위해서
👉 한가지 더! 교보문고에 가서 책을 찾는 다고 하면?
- 꽂혀진 방법대로 찾아야 쉽게 찾을 수 있겠죠! 😎 (섹션 → 출판사 → 책 제목)
- 우리 눈에 보이진 않지만, 사실 DB에는
Index라는 순서로 데이터들이 정렬되어 있답니다!
2) 들어가기 전에 - DB의 두 가지 종류

-
RDBMS(SQL)
행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사합니다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것입니다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있습니다.
ex) MS-SQL, My-SQL 등 -
SQL
딕셔너리 형태로 데이터를 저장해두는 DB입니다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 됩니다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있습니다.
ex) MongoDB
👉 용도에 맞게 사용하는 것이 좋다고 하네요.
3) 들어가기 전에 - DB의 실체에 관하여
👉 자, 그럼 DB의 실체는 무엇일까요? 특별한 컴퓨터일까요?
- 아닙니다! 아주 간단하게, 우리가 쓰는 프로그램과 같은 것이랍니다.
- 즉, 내 컴퓨터에 게임도 설치하고, PPT도 설치하고, DB도 설치할 수 있는 것이죠.
👉 그 런 데! 이 마저도 요새는 Cloud 형태로 제공해주는 곳들이 많답니다.
- 유저가 몰리거나 / DB를 백업해야 하거나 / 모니터링 하기가 아주 용이하기 때문이죠!
(꿀팁 - 요새 트렌드는클.라.우.드!) - 그래서, 우리도 최신 클라우드 서비스인
mongoDB Atlas를 사용해 볼 것이랍니다!
◾3-12. mongoDB 연결하기
1) mongoDB - Atlas 연결하기
👉 pymongo 라이브러리의 역할
예를 들어, MS Excel를 파이썬으로 조작하려면,
특별한 라이브러리가 필요하지 않겠어요?
마찬가지로, mongoDB 라는 프로그램을 조작하려면,
특별한 라이브러리, pymongo가 필요하답니다!
-
패키지 설치하기
pymongo, dnspythondnspython은 pymongo를 통해 mongoDB에 연결하기 위해 URI를 입력하기 위한 서식을 사용할 수 있게 해주는 라이브러리이다. 간단하게 말해서 DNS 핸들링에 도움을 준다.
Pymongo에서도 요구 dependency로 dnspython을 알려주고 있다. -
다시, mongoDB Atlas 화면에서 Connect your application 클릭
- 해당 Cluster에서
Connect▶️Connect your application을 선택하면 나오는 URI 코드를 복사해서 문법에 맞게 입력한다.
(URI 서식을 위해서 dnspython 라이브러리를 설치해야 한다.)from pymongo import MongoClient client = MongoClient('여기에 URL 입력') db = client.dbsparta
◾3-13. pymongo로 DB조작하기
2) pymongo 사용법. 코드요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})◾3-14. 웹스크래핑 결과 저장하기
- 예시 코드
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.55vah.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
doc = {
'rank': rank,
'title': title,
'star': star
}
db.movies.insert_one(doc)