그래프 Graph
그래프는 자료구조의 일종이다.
정점은 Node, Vertex 라고 하며 아래 그림에서 A, B, C, D, E인 부분을 의미한다.
간선은 Edge라고 하며 정점간의 관계를 나타낸다.
정점과 간선을 가지고 그래프 G는 G = (V,E)로 나타낸다.
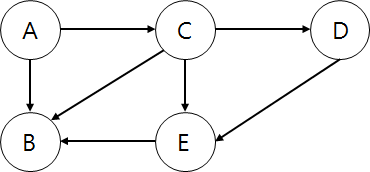
경로 는 정점에서 다른 정점으로 가는 간선의 연속 즉, 끊기지 않고 끝까지 가는 것을 말한다.
위 그림으로 예를 들면 정점 A에서 정점 B로 가는 경로를 구한다고 해보자.
A -> C -> D -> E -> B
A -> B
A -> C -> B
A -> C -> E -> B
이렇게 4가지가 나온다.
사이클은 시작 정점에서 다시 시작 정점으로 돌아오는 경로를 의미한다.
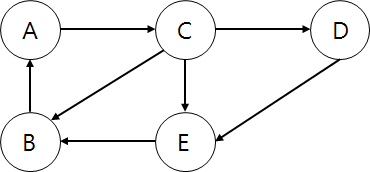
이와 같은 상황에서 정점 A에서 다시 정점 A로 돌아오는 경로는
A -> C -> B -> A
A -> C -> E -> B -> A
A -> C -> D -> E -> B -> A
이렇게 3가지의 경로가 나온다.
단순 경로와 단순 사이클은 같은 정점을 두 번 이상 방문하지 않는 경로 또는 사이클이라 한다.
그래프는 방향이 있는 그래프, 방향이 없는 그래프로 나뉜다. 방향이 있는 그래프는 위에서 보여준 그림과 같고 방향이 가리키는 방향으로 갈 수 있다. 즉, A -> C 는 되지만 C -> A는 안되는 것이다.
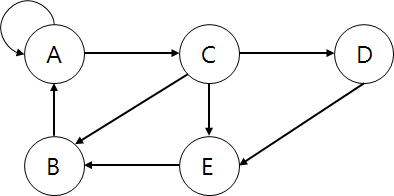
반대로 방향이 없는 그래프는 있는 그래프와 다르게 서로 갈 수 있다. A -> C 가 되면 C -> A도 되는것이고 이는 양방향 그래프라고도 한다.
추가적으로 간선이 여러개인 경우가 있다. 2번째 그림에서는 B -> A 인 간선이 하나인데 여기에 하나가 더 생기는 것이다.
루프는 간선의 양 끝 점이 같은 경우를 말한다. 아래와 같이 A -> A 를 의미하는 것이다.
가중치는 간선에 써있는 어떠한 값을 의미한다. 아래 그림처럼 수가 써있는 부분을 가중치라고 하는데, 대표적으로 이동하는 거리, 이동하는데 필요한 시간, 이동하는데 필요한 비용 등으로 주어진다. 가중치가 없는 경우에는 1이라고 생각하면 된다.
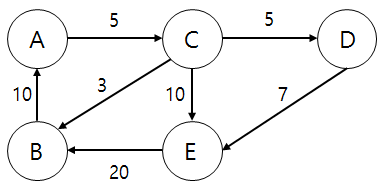
차수는 정점과 연결되어 있는 간선의 개수를 말한다. 위 그림이 방향이 없다는 가정하고 A의 차수는 2, C의 차수는 4이다. 위 그림처럼 방향 그래프의 경우 In-degree와 Out-degree로 나누어서 차수를 계산한다. E의 In-degree는 2이고, Out-degree는 1이다.
그래프의 표현
그래프의 정점과 간선을 이용해서 저장한다.
아래 그림과 같이 정점이 6개, 간선이 8개 있다. 정점은 정점의 수를 저장하면 된다.
정점 : {1, 2, 3, 4, 5, 6}
간선 : {(1,2), (1,5), (2,5), (2,3), (2,4), (3,4), (4,5), (4,6)}
이 와같이 나타낼 수 있으며 결국 그래프를 표현하는 것이 간선을 나타낸다고 볼 수 있다.
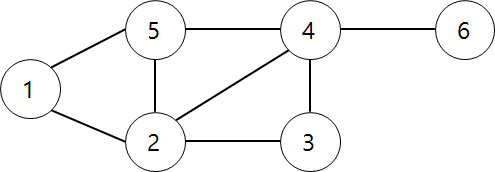
그래프의 저장 방법에는 인접 행렬과 인접 리스트가 있다. 위에서 간선을 1차원 배열로 처리할 수 있지만 효율적인 측면에서 떨어질 수 있다. 따라서 인접 행렬 또는 인접 리스트를 사용하면 한 정점 x와 연결된 간선을 효율적으로 찾을 수 있다.
인접 행렬
정점의 개수를 V라고 했을 대 V X V 크기의 이차원 배열을 이용한다.
A[i][j] = 1 (i -> j 간선이 있을 때), 0 (없을 때) 아래와 같은 표로 나타낼 수 있다. 만약 가중치가 존재한다면 가중치 값으로 써야한다.
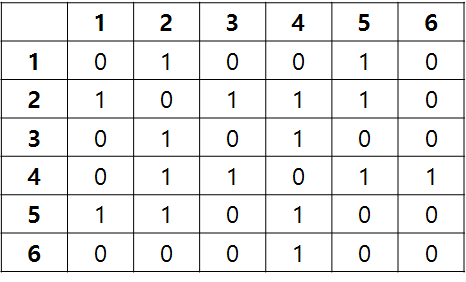
정점의 개수가 V 간선의 개수가 E 라고 했을 때
공간은 이 필요하다. 한 정점과 연결된 모든 간선을 구하는데 걸리는 시간은 이다. 왜냐하면 한 정점을 기준으로 인접행렬에 들어가 있는 값을 모두 확인해야 하기 때문이다.
인접 리스트
리스트를 이용해서 구현한다. A[i] = i와 연결된 정점을 리스트로 포함 왜 리스트로 하냐면 몇 개가 있을지 모르기 때문이다.
A[1] : 2, 5
A[2] : 1, 3, 4, 5
A[3] : 2, 4
A[4] : 3, 5, 2, 6
A[5] : 1, 2, 4
A[6] : 4
이렇게 연결된 정점을 넣어주면 되고, 가중치가 있는 경우 (정점, 가중치) 이렇게 넣으면 된다.
리스트는 크기를 동적으로 변경할 수 있는 Linked List를 사용해야 한다. 자바의 경우 ArrayList를 사용하면 된다.
인접 리스트의 공간은 가 필요한데, 인접 행렬과 다르게 연결된 간선만 저장하기 때문이다. 한 정점과 연결된 모든 간선을 찾는 시간은 와 같다. 이유는 하나의 정점과 연결된 모든 간선이 저장되어 있고 그 개수가 정점의 차수와 같기 때문이다.
그래서 인접 리스트가 인접 행렬보다 빠르다. 하지만 임의의 두 정점 사이에서 간선이 있는지 없는지 구하는 시간은 인접 행렬이 빠르다.
간선 리스트
간선을 저장하는 배열을 이용해서 구현한다. E라는 1차원 배열에 간선을 모두 저장한다.
E[0] = 1 2
E[1] = 1 5
E[2] = 2 1
....
이렇게 모든 간선을 저장한다. 그 다음 각 간선의 앞 정점을 기준으로 개수를 센 뒤 누적을 시켜준다.


이렇게 누적까지 완료되면 특정 정점의 연결된 간선을 구하기 위해서는 앞에 cnt[i-1] 부터 cnt[i] - 1 까지 구하면 된다.
문제
문제 1. ABCDE
N명의 친구 관계가 주어졌을 때 A - B - C - D - E 과 같은 친구관계가 존재하는지 구하는 문제이다.
이 문제는 앞서 공부한 간선리스트, 인접행렬, 인접리스트를 모두 사용해서 풀어본다.
A -> B, C -> D 는 그냥 간선이기 때문에 간선 리스트로 찾을 수 있고, B -> C는 인접행렬로 찾을 수 있다. 마지막으로 D -> E는 인접 리스트로 찾는다.
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
boolean[][] a = new boolean[n][n];
ArrayList<Integer>[] g = (ArrayList<Integer>[]) new ArrayList[n];
ArrayList<Edge> edges = new ArrayList<Edge>();
for (int i = 0; i < n; i++) {
g[i] = new ArrayList<Integer>();
}
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
edges.add(new Edge(from, to));
edges.add(new Edge(to, from));
a[from][to] = a[to][from] = true;
g[from].add(to);
g[to].add(from);
}
m *= 2;
for (int i = 0; i < m; i++) {
for (int j = 0; j < m; j++) {
int A = edges.get(i).from;
int B = edges.get(i).to;
int C = edges.get(j).from;
int D = edges.get(j).to;
if (A == B || A == C || A == D || B == C || B == D || C == D) {
continue;
}
if (!a[B][C])
continue;
for (int E : g[D]) {
if (A == E || B == E || C == E || D == E) {
continue;
}
System.out.println(1);
System.exit(0);
}
}
}
System.out.println(0);
}
}
class Edge {
int from, to;
Edge(int from, int to) {
this.from = from;
this.to = to;
}
}그래프의 탐색
목적 : 임의의 정점에서 시작해서 연결되어 있는 모든 정점을 1번씩 방문하는 것
그래프의 탐색에는 DFS, BFS 두가지가 있다. 차이는 어떤 순서로 정점을 방문할 것인가에 있다. DFS는 깊이 우선 탐색이고 BFS는 너비 우선 탐색이다.
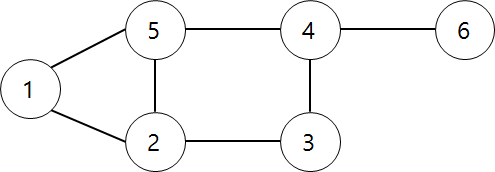
DFS - 깊이 우선 탐색
스택을 이용해서 갈 수 있는 만큼 최대한 많이 가고 갈 수 없으면 이전 정점으로 돌아간다.
현재 정점이 1일 때 스택에 1를 넣는다. 그 다음 갈 수 있는 정점은 2 또는 5가 되는데, 이중 하나만 선택을 한다. 2를 선택했을 때 스택에는 1, 2 이렇게 된다. 정점 2에서 갈 수 있는 정점은 3 과 5가 있는데 3을 선택하여 스택에 넣는다. 이제 스택에는 1, 2, 3이 되었다. 다음으로 갈 수 있는 정점은 4 스택에는 1, 2, 3, 4가 되고 그 다음은 5 또는 6중에 5를 선택하면 스택에는 1, 2, 3, 4, 5가 된다. 이 다음에는 갈 수 있는 정점이 없기 때문에 5를 스택에서 빼고 확인을 하면 6으로 갈 수 있기 때문에 스택에는 1, 2, 3, 4, 6이 된다. 마지막으로 6에서는 더이상 갈 수 없어서 스택에서 하나씩 뽑아서 스택에는 더이상 아무 정점이 없을 때 탐색이 종료 된다.
DFS는 재귀 호출을 통해 인접 행렬 또는 인접 리스트로 구현할 수 있다.
BFS - 너비 우선 탐색
큐를 이용해서 지금 위치에서 갈 수 있는 것을 모두 큐에 넣는 방식이다. 큐에 넣을 때 방문했다고 체크해야 한다. 예를들어 똑같이 위 그림에서 현재 정점이 1이라고 해보자. 그러면 큐에는 1이 들어간다. 그 다음에 1에서 갈 수 있는 정점은 2와 5니까 두개 모두 큐에 넣는다. 그러면 1, 2, 5가 큐에들어가게 되고 이후 1를 큐에서 뺀다. 그 다음 2에서 갈 수 있는 정점은 1, 5, 3 이 있는데 이때 1, 5는 이미 방문한 적이 있기 때문에 큐에는 3만 들어간다. 다시 2를 큐에서 빼면 현재 정점은 5이다. 5에서 갈 수 있는 정점은 4만 남기 때문에 큐에는 4가 들어간다.
현재까지 큐에는 5, 3, 4가 되었다. 이제 5를 빼면 현재 정점은 3이 되는데, 더이상 갈 수 있는 정점이 없기 때문에 다음으로 진행한다. 이렇게 진행하면 큐가 비어지게 되는데 이때가 탐색이 종료된다.
문제 : DFS와 BFS
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 문제이다.
public static ArrayList<Integer>[] a;
public static boolean[] c;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
int start = sc.nextInt();
a = (ArrayList<Integer>[]) new ArrayList[n + 1];
for (int i = 1; i <= n; i++) {
a[i] = new ArrayList<Integer>();
}
for (int i = 0; i < m; i++) {
int u = sc.nextInt();
int v = sc.nextInt();
a[u].add(v);
a[v].add(u);
}
for (int i = 1; i <= n; i++) {
Collections.sort(a[i]);
}
c = new boolean[n + 1];
dfs(start);
System.out.println();
c = new boolean[n + 1];
bfs(start);
System.out.println();
}
public static void dfs(int x) {
if (c[x]) {
return;
}
c[x] = true;
System.out.print(x + " ");
for (int y : a[x]) {
if (c[y] == false) {
dfs(y);
}
}
}
public static void bfs(int start) {
Queue<Integer> q = new LinkedList<Integer>();
q.add(start);
c[start] = true;
while (!q.isEmpty()) {
int x = q.remove();
System.out.print(x + " ");
for (int y : a[x]) {
if (c[y] == false) {
c[y] = true;
q.add(y);
}
}
}
}