
문제
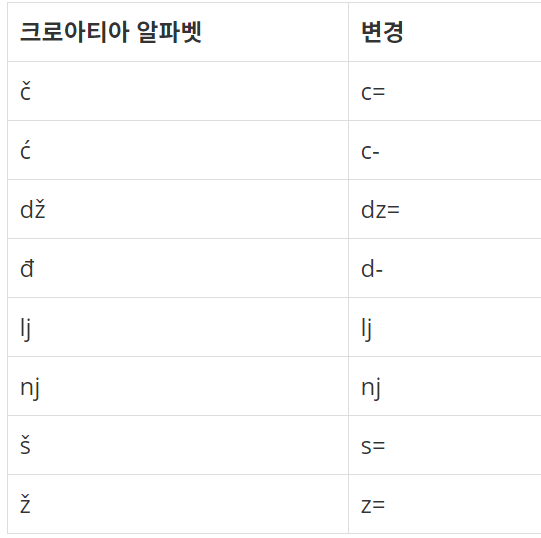
예전에는 운영체제에서 크로아티아 알파벳을 입력할 수가 없었다. 따라서, 다음과 같이 크로아티아 알파벳을 변경해서 입력했다.
예를 들어, ljes=njak은 크로아티아 알파벳 6개(lj, e, š, nj, a, k)로 이루어져 있다. 단어가 주어졌을 때, 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.
dž는 무조건 하나의 알파벳으로 쓰이고, d와 ž가 분리된 것으로 보지 않는다. lj와 nj도 마찬가지이다. 위 목록에 없는 알파벳은 한 글자씩 센다.
입력
첫째 줄에 최대 100글자의 단어가 주어진다. 알파벳 소문자와 '-', '='로만 이루어져 있다.
단어는 크로아티아 알파벳으로 이루어져 있다. 문제 설명의 표에 나와있는 알파벳은 변경된 형태로 입력된다.
출력
입력으로 주어진 단어가 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.
풀이
문제에서 변환되는 8개의 알파벳을 제외하고 나머지는 하나씩 세는걸로 주어졌다. 그래서 대부분의 사람들이 8개의 경우를 다 if문이나 switch~case로 풀려고 했을 것이다. (필자도 마찬가지...)
우연히 다른 사람의 코드를 보면서 String.replace() 함수를 보게되었고, 이를 사용했을 때 엄청나게 간결해지는 코드를 확인할 수 있었다.
replace()를 사용하여 한자리의 문자열로 치환하여 저장하고 마지막에는 해당 문자열의 길이를 출력하면 된다.
소스
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String str = sc.nextLine();
str = str.replace("c=", "0");
str = str.replace("c-", "0");
str = str.replace("dz=", "0");
str = str.replace("d-", "0");
str = str.replace("lj", "0");
str = str.replace("nj", "0");
str = str.replace("s=", "0");
str = str.replace("z=", "0");
System.out.println(str.length());
}
}
