
개요
- 최근 데이터 엔지니어 스터디에 참가했는데 1주차 프로젝트 회의를 앞두고 있다.
- 아직까지 정해진건 없지만 도메인, 기술 스택 등 내가 원하는 것을 직접 정리해보기 위한 목적으로 몇 개의 프로젝트를 생각해봤다.
- 할애할 시간이 많지는 않기 때문에 기대 결과나 실현 가능성은 간략하게만 생각해본다.
암호화폐 실시간 시세 차트
금융 도메인 + 실시간 처리 + 시각화
기획 의도
개인 수준에서 실시간 데이터에 접근할 수 있을만한 가장 좋은 경로는 암호화폐 거래소라고 생각한다.
근거는 아래와 같다.
- 암호화폐 거래소는 전통적인 금융 거래소 대비 데이터 접근에 대해 공개적인 성향이 있다. 거래 자체가 네트워크에 기록되며, 누구나 실시간으로 열람할 수 있는 것이 블록체인 기술의 핵심이기 때문에, 거래 과정에서 발생하는 상세한 내역을 투명하게 전달해준다.
- 업비트와 같은 거래소는 실시간 가격, 거래량, 과거 데이터 등 다양한 정보를 API로 제공해준다. 또한 업비트만 확인해봤을 때, API 문서가 알기 쉽게 정리되어 있고, 데이터 요청 및 응답 과정에서 익숙한 JSON 포맷을 지원한다.
- 자산 증식에 관심이 있다면 누구나 암호화폐, 또는 주식 거래를 해봤을 것이다. 매수/매도, 분봉/일봉, 시가/종가와 같은 개념은 억지로 공부를 안해도 거래를 하다보면 자연스럽게 알게 된다. 관심이 없다면 안타깝지만, 적어도 조금의 관심이 있다면 도메인을 이해해야할 걱정이 없다.
기대 결과
그럴듯한 제목을 지어야해서 차트라고 했지만, 하려는건 데이터 엔지니어링 기술 활용이기 때문에 겉에 보여지는건 중요하지 않을 것 같다.
활용하고 싶은 기술이래봤자 알고 있는게 별로 없어서 Kafka, Spark, Airflow 정도를 보고 있고, 시계열 데이터란 것에 집중한다면 Prometheus, Grafana 등을 활용해볼 수도 있을 것이다. 그외에 실시간성을 중시한다면 Flink란 기술도 활용해볼 수 있을 것 같은데 사실 잘 모른다.
해당 프로젝트를 통해 얻고 싶은 것은 아래와 같다.
1. 신뢰성 있는 데이터 수집 (ETL 과정에서 오류가 발생한다면 해결하는 경험)
2. 장애 복구 (의도적으로 병목 현상 등의 장애를 만들어서 해결하는 경험)
3. 데이터 모델링 (가상의 분석 목적을 설정하고 해당 목적에 맞는 테이블 모델링 경험)
4. 실시간 알림 또는 대시보드 구현 (실시간으로 변경되는 데이터를 조회할 수 있는 환경을 제공하는 경험)
추가로, 국내 주식 시장에서는 몇 달 전에 넥스트레이드라는 대체 거래소가 들어오면서 기존 한국거래소의 호가를 고려한 중간가라는 개념이 만들어졌다. 암호화폐 거래소도 업비트만 있는게 아니라 빗썸, 코인원 등 국내 거래소가 많이 있는데 여러 거래소에서 시세를 가져와 중간가, 고가, 저가 등을 보여줄 수 있으면 더욱 좋을 것 같다.
실현 가능성
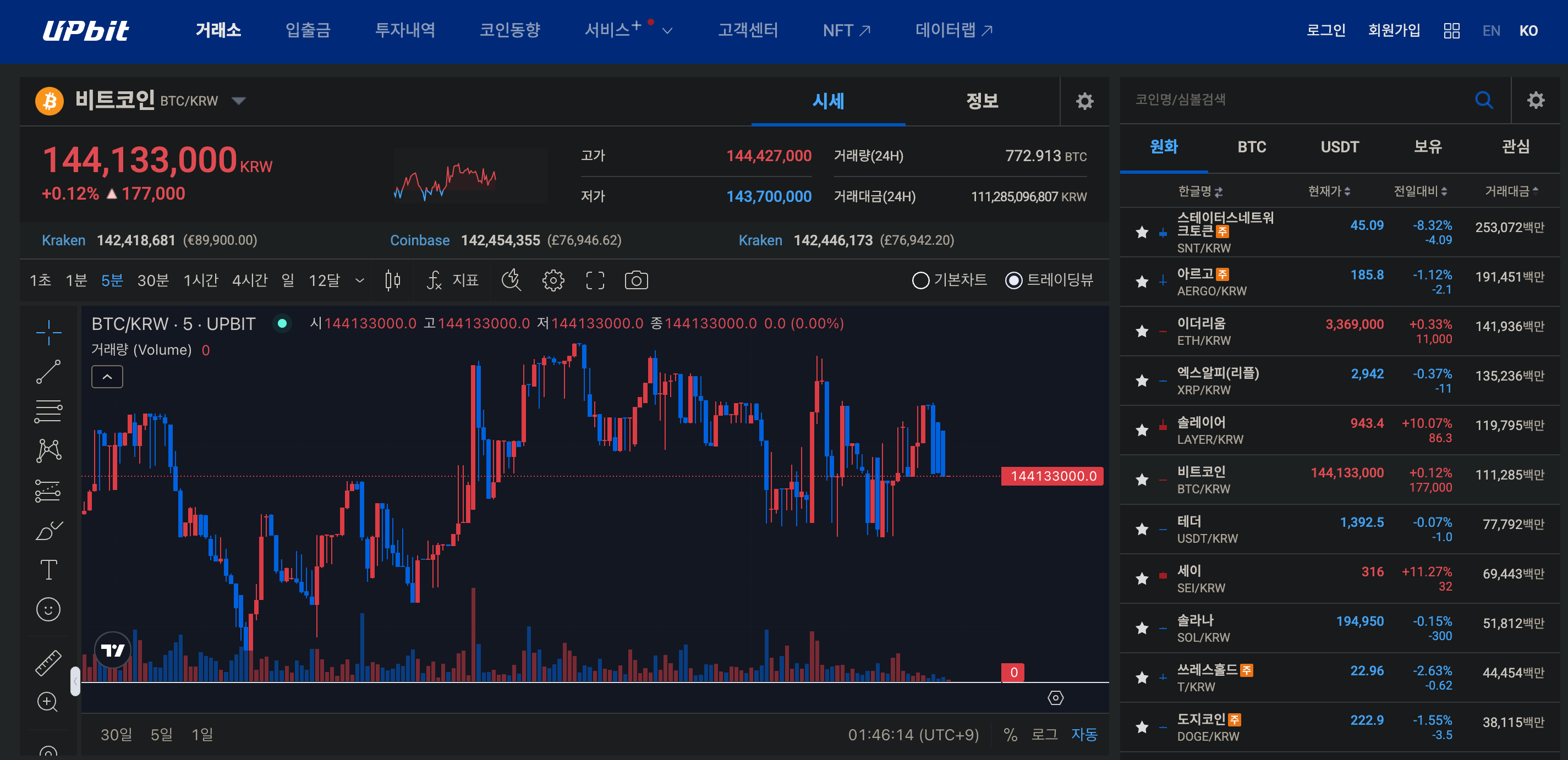
업비트는 Open API를 제공하며, 관련 문서를 제공한다.
요청 횟수와 관련해서는, 시세 조회 API에 대해서 직접적으로 알아보진 못했지만, 초당 30회 정도는 수집할 수 있을 것 같다. 그렇게까지 할 생각은 없고 초당 1회만 가능해도 충분하다.
시세 조회 API 중 초(second) 단위로 시세를 조회하는 것은 해당 API 문서를 참고해볼 수 있다.
기본적인 OHLC 가격만 알려줘도 충분하다. 거래량도 활용해볼 수 있을 것 같다.
업비트만 따졌을 때는 실시간 데이터 수집 자체로는 문제가 없을 것 같다.
대중교통 실시간 도착 알림
공공 데이터 + 실시간 처리 + 알림
기획 의도
정부에서는 공공데이터포털을 통해 다양한 데이터를 제공해준다. 그중에서 대중교통 도착 정보는 정부가 제공하는 API 중에서 가장 실시간성을 띈다.
기본적으로 대중교통은 시민이라면 한번쯤은 이용해보는 서비스이기 때문에 암호화폐보다 더욱 보편적이고, 버스나 지하철이 왔다갔다하는 것은 굳이 그 원리를 이해해야할 필요성도 없다.
기대 결과
지도 API를 쓴다면 시각적으로 더욱 눈길을 끄는 결과물을 만들 수 있겠지만, 데이터 엔지니어링 기술 활용이 목적이라 시각적인게 중요하지도 않고, 무료로 지도에 실시간으로 무언가를 표시할 수 있는 API는 찾아보지 못했다.
활용하고 싶은 기술은 마찬가지로 Kafka, Spark이고, Airflow는 배치 주기에 따라 사용할 수 있을지 아닌지를 판단해야할 것 같다. 분석이 목적이 아니라서 시계열 DB까지 필요할까 싶긴한데 이건 의논해봐야할 것 같다.
해당 프로젝트를 통해 얻고 싶은 것은 아래와 같다.
1. 신뢰성 있는 데이터 수집 (ETL 과정에서 오류가 발생한다면 해결하는 경험)
2. 장애 복구 (의도적으로 병목 현상 등의 장애를 만들어서 해결하는 경험)
3. 실시간 알림 구현 (실시간으로 데이터를 조회해서 특정 조건에 알림을 전송하는 경험)
실현 가능성
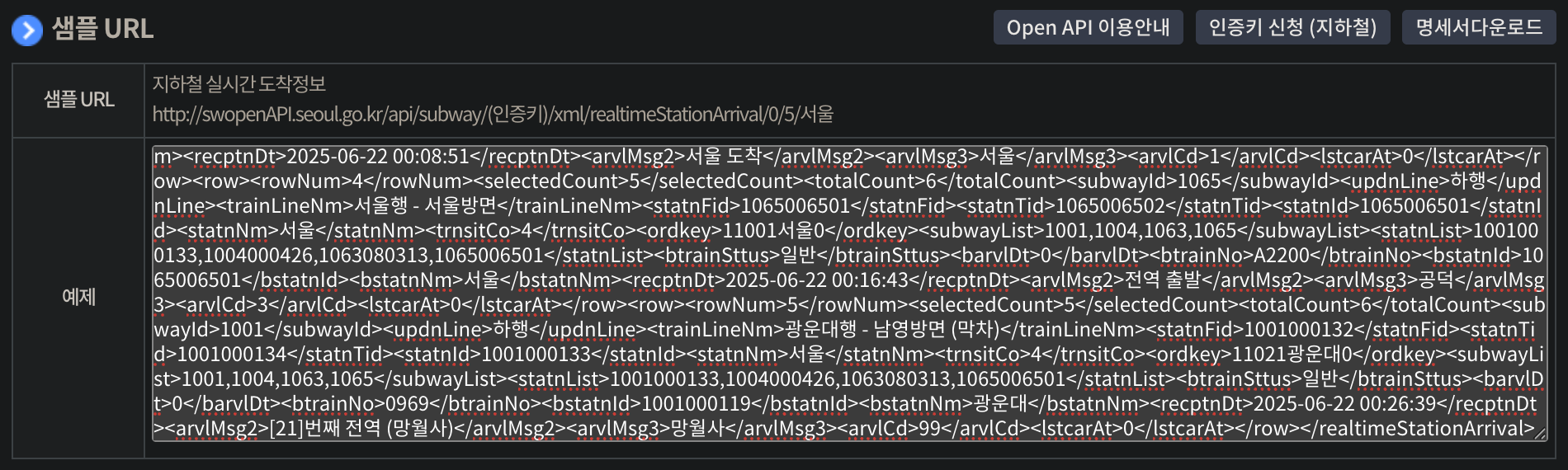
공공데이터포털의 서울특별시_지하철 실시간 도착정보 API도 있긴한데, 비로그인 상태에서 미리보기까지 지원하는 서울 열린데이터 광장의 서울시 지하철 실시간 도착정보 API를 활용해보는 것도 좋을 것 같다.
샘플 테스트의 결과가 XML 포맷으로 전달되어 가공이 까다로울 수 있는데, 대충 확인해보니 깊이가 있는 구조는 아니라서 단순히 딕셔너리 배열처럼 파싱하면 어렵지 않을 것 같다.
실시간 뉴스 헤드라인 알림
언론 도메인 + 실시간 처리 + 알림
기획 의도
일상적으로 이용하는 데이터 중에 업데이트 주기가 빠른 것이라면 뉴스 헤드라인이 있을 수 있다.
앞에 두 프로젝트의 경우 암호화폐 시세는 개인적인 흥미는 많지만 흔한 주제이고, 공공데이터는 너무 잘 되어있어 특별히 오류를 처리할게 없을 수 있다. 하지만, 뉴스 헤드라인은 언론사마다 제공하는 포맷도 다르고, 그것을 하나로 합치는 과정에서 적잖은 오류를 경험할 수 있을 것 같아 선정했다.
마찬가지로 단순히 뉴스 헤드라인을 보고 알림을 주는건 특별히 도메인을 이해하고 해야할 건 아니기 때문에 접근성도 좋다고 생각한다.
제목이 헷갈릴 수 있는데, 모든 뉴스 헤드라인을 알려주는건 아니고, 특정 키워드를 포함하는 헤드라인을 선택적으로 알려주는 것을 기대한다.
기대 결과
뉴스 헤드라인은 기본적으로 자연어 데이터다. 초(second) 단위로 며칠 쌓아봤자 GB 단위를 넘길까 말까하는 수준의 수치형 데이터 대비, (수집 대상인 언론사가 다양해야 겠지만) 길이가 긴 문자열 데이터 특성상 며칠만 지나도 메모리에 다 안올라올 정도의 데이터가 만들어질 것이다.
활용하고 싶은 기술이래봤자 어차피 똑같은 Kafka, Spark인 것 같고, 문자열 데이터 처리 관련해서 추가로 사용할만한 툴이 있을 것 같다.
해당 프로젝트를 통해 얻고 싶은 것은 아래와 같다.
1. 도메인간 데이터 취합 (서로 다른 도메인에서 발생하는 데이터를 통합적으로 사용할 수 있게 가공한 경험)
2. 장애 복구 (의도적으로 병목 현상 등의 장애를 만들어서 해결하는 경험)
3. 자연어 데이터 처리 (자연어 데이터를 안정적으로 DB에 쌓는 경험)
3. 실시간 알림 구현 (실시간으로 데이터를 조회해서 특정 조건에 알림을 전송하는 경험)
실현 가능성
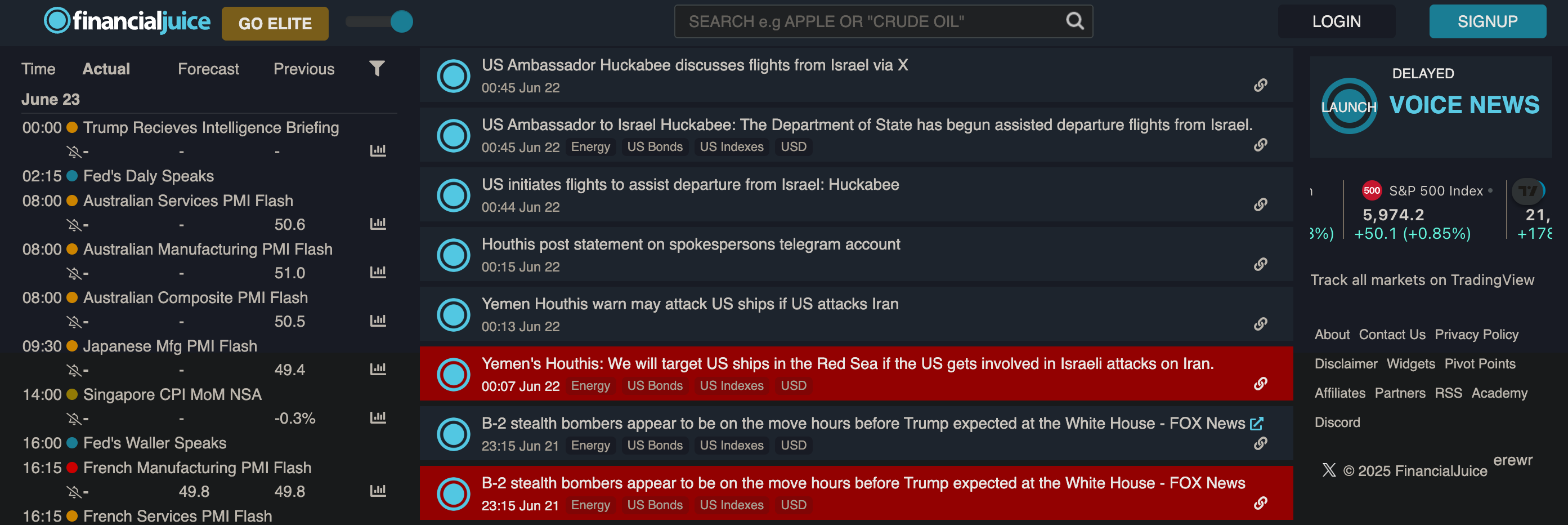
평소에 금융 시장 관련 헤드라인을 전달하는 FinancialJuice라는 서비스를 주로 이용한다. 무료로도 몇초 정도 딜레이된 헤드라인을 전달하는데, 관련한 API를 찾아보니 Juice Financial이라는 문서가 있다.
자세하게 확인은 안해봤는데, 이런 API를 통해서 뉴스 헤드라인을 가져올 수 있을 것 같다. 언론사는 많으니까 찾으면 4개 정도는 뉴스 헤드라인을 제공하는 API가 있기를 기대한다.
스트리밍 서비스 로그 모니터링
동영상 스트리밍 + 서비스 개발 + 로그 수집 + 실시간 모니터링
기획 의도
로그 모니터링이란 것을 해보고 싶고, 스트리밍 서비스에 관심이 많아서 둘을 결합한 프로젝트를 기획했다.
과정은 다음과 같다.
- 동영상 또는 오디오 스트리밍 웹사이트를 (UI는 대충하고 재생 기능만 있게) 만든다.
- Perplexity와 같은 웹사이트 검색을 수행하는 AI에게 스트리밍 사이트 주소를 제공하며 랜덤한 동작을 수행하도록 요청하여 사용자의 행동을 가정한다.
- 이때, 데이터 분석가가 있음을 가정하고 유입 경로, 조회수, 시청 시간 등의 지표를 산출한다.
- 실시간으로 총 몇 건의 수치가 발생했는지 모니터링하는 환경을 제공한다.
데이터 엔지니어 외적으로 서비스 개발 등 다소 관련없는 작업이 포함되어 있다. Cursor AI나 Replit과 같은 툴을 활용한 바이브 코딩으로 개발 시간을 절약할 수 있을 것 같은데, 실제로 써본적은 없어서 확신은 안된다.
기대 결과
서비스 환경에 최대한 가깝게 구현하여 직접 데이터를 만들어낸다는 점에서 차별적인 프로젝트라 생각한다.
하지만, 아직까지 막연하여 어떠한 기술을 사용해야 할지는 논의해야할 것 같다.
해당 프로젝트를 통해 얻고 싶은 것은 아래와 같다.
1. 서비스 운영 (실제 서비스 환경에서 만들어지는 데이터를 다루는 경험)
2. 이상 탐지 (사용자의 이상 행동을 탐지하고 대응하는 경험)
3. 스트리밍 데이터 제공 (서버에 저장된 동영상 또는 오디오를 사용자에게 제공하는 경험)
4. 스트리밍 지표 설계 (스트리밍 서비스 분석에 활용할 지표를 설계하고 수집하는 경험)
실현 가능성
앞서 말했듯이 막연하다. 기획 의도 시 제시한 4가지 과정 중에 그 어느 것도 실현 가능성을 확인할 수 없다.
