
프로젝트명
LinkMerce는 커머스(Commerce)를 연결(Link)한다는 의미를 가집니다.
바로가기로 연결되는 Github 리포지토리에서 구현된 코드를 확인할 수 있습니다.
업무 상 여러 이커머스 플랫폼에서 마케팅을 위한 데이터를 수집했는데, 다른 업체에 외주로 유사한 데이터 수집 파이프라인을 설계하게 되면서 기존에 구현한 웹 스크래핑 작업들을 사용하기 쉽게 RESTful API로 정리해보려 합니다.
실시간성이 필요한 작업들은 아니라서 최종적인 목표는 Airflow Worker에서 해당 API를 직접 호출하기 위해 최적화하는 것입니다. 당장엔 데이터 수집과 변환을 같이 담당하지만, 향후 데이터 변환은 dbt와 같은 전문적인 툴에 위임할 예정입니다.
프로젝트 배경
마케팅부에서는 네이버 쇼핑과 같은 이커머스 플랫폼에서 보이는 다양한 정보를 매일마다 모니터링합니다. 이것은 반복적인 작업이기 때문에 사람이 일일이 처리하기에는 매우 비효율적인 작업니다. 그래서, 모든 데이터 수집 작업을 파이썬 코드로 구현하고 아래 예시와 같이 정해진 시간에 작업을 처리했습니다.
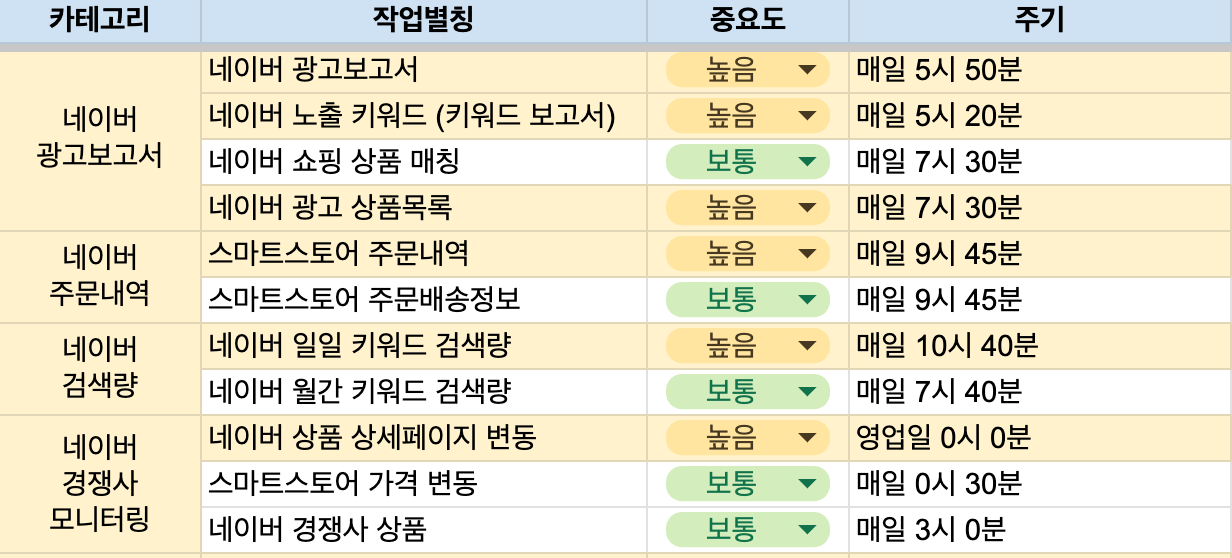
작업 스케줄링 경험
처음에는 파이썬 코드를 시간에 맞춰서 직접 실행했지만, 작업이 3개에서 10개, 10개에서 30개씩 계속해서 늘어나면서, 그리고 새벽에 처리해야할 작업도 생기면서 사람이 직접 실행할 수 없는 수준에 이르렀습니다.
이때 당시에 구글 클라우드(GCP)가 마음에 들어서 회사 차원에서 도입했던 때라서 최대한 GCP에서 제공하는 기능을 이용하려 했습니다. 그렇게 선택한 작업 스케줄링 방식이 Cloud Scheduler 입니다. Cloud Run 이라는 서버리스 컴퓨팅 서비스에 파이썬 코드를 함수로 등록하고, 스케줄러가 크론탭으로 지정한 시간에 HTTP 트리거 요청을 보냈습니다.
과거에 구현한 웹 스크래핑 시스템
서버리스 함수를 웹 스크래핑 목적으로만 사용하기에 비용이 많이 나올 일은 없지만, 그래도 최대한 비용을 아끼기 위해 컴퓨팅 리소스를 줄이려고 했습니다. 설치가 필요한 외부 패키지에 대한 의존도를 줄이고 내장 함수로부터 다양한 유틸리티 함수를 만들어서 웹 스크래핑에 이용했습니다.
웹 스크래핑과 관련하여 가장 관심있게 보던 툴이 Scrapy 라는 프레임워크였습니다. 직접 활용할 생각은 없었지만 Scrapy 에서 정의한 Spider 의 개념에 감명을 받아 웹 스크래핑 클래스의 명칭을 Spider 로 정했습니다.
아래 이미지는 Spider 로부터 발전된 클래스 간 상속도입니다.
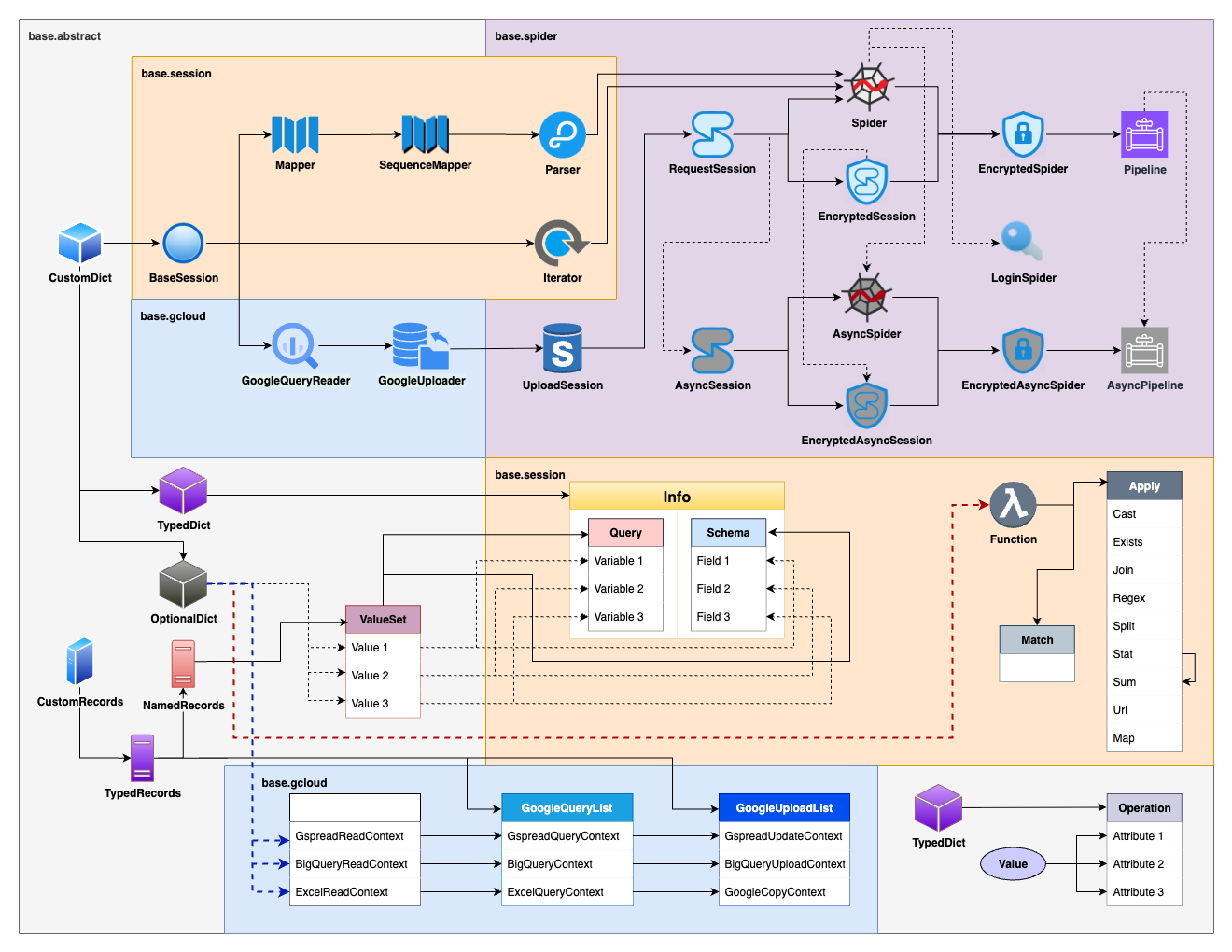
ETL 프로세스에 대해 데이터 수집은 ./base/spider.py 에서 추상 팩토리를 관리했습니다. 데이터 변환과 관련된 구조체 및 메서드는 ./base/session.py 에서 구현했습니다. (BigQuery와 구글 시트에) 데이터를 적재하기 위한 함수 및 이를 사용하는 클래스는 ./base/gcloud.py 에서 정의했습니다.
과거 시스템의 문제점
위 상속도를 보면 알 수 있는데, 데이터 수집을 담당하는 Spider 클래스가 데이터 수집만 처리하지 않습니다. 데이터 변환을 담당하는 Parser 클래스와 데이터 적재를 담당하는 GoogleUploader 클래스를 상속받아 ETL 프로세스 전체에 책임을 지고 있습니다.
ETL 프로세스 구현 시 하나의 Spider 를 중심으로만 생각하면 되기에, 컨베이어 벨트에서 상품을 찍어내듯이 편리하게 기능을 만들어낼 수 있다는 장점이 있습니다. 하지만, 한번이라도 반복적으로 사용해본 로직들은 전부 추상화를 해버린데다 이러한 ETL 프로세스가 하나의 클래스에서 유기적으로 얽혀있어서, 새로운 로직을 추가하기 위해 고려해야할 점이 많았고 특정 지점에서의 테스트도 어려웠습니다.
개선방향
이번 프로젝트를 기획하게 된 것도 이러한 복잡한 시스템을 뜯어고치기가 어려워서 처음부터 새로 만들고자 한 것입니다. 새로운 시스템은 ETL 프로세스에서 수집, 변환, 적재 기능을 철저하게 구분합니다.
데이터 수집을 담당하는 클래스는 Collector 로 정의합니다. Collector 는 requests.Session 또는 aiohttp.ClientSession 객체를 사용해 HTTP 요청을 보내고 응답 결과를 텍스트나 JSON 파싱해 반환합니다.
class Collector(SessionClient, metaclass=ABCMeta):
def collect(self, session: requests.Session, ...) -> Dict:
response = session.request(GET, url, ...)
return response데이터 변환을 담당하는 클래스는 Parser 로 정의합니다. Parser 는 다양한 타입의 객체를 입력으로 받아 정해진 타입의 객체로 반환합니다. 앞에서 정의한 Collector 에서 반환하는 딕셔너리 객체를 입력으로 받아 리스트로 파싱하는 ListParser 는 아래처럼 구현할 수 있습니다.
class ListParser(list, Parser):
def __init__(self, response: Dict, *args, **kwargs):
list.__init__(self, self.parse(obj, *args, **kwargs))
def parse(self, response: Dict, ...) -> List:
return response["data"]["items"]ETL 프로세스의 철저한 분리를 목적으로 하지만, HTTP 응답 결과를 그대로 적재하기엔 불필요한 정보가 많아서 Collector 가 Parser 를 매개변수로 받아서 Parser 를 호출하는 방식을 생각하고 있습니다. 따라서, 모든 Parser 는 호출, 즉 초기화와 동시에 파싱이 이루어지며 그 자체로 자료구조의 형태를 가집니다.
class Collector(SessionClient, metaclass=ABCMeta):
def collect(
self,
session: requests.Session,
parser: Callable | None = None,
...
) -> Dict | List:
response = session.request(GET, url, ...)
return response if parser is None else parser(response)데이터 적재는 Airflow에서 제공하는 BigQueryHook 을 사용할 예정이었지만, 해당 Hook이 지원하는 insert_all() 메서드가 해당 문서에 따르면 스트리밍 방식으로 데이터를 적재한다고 명시되어 있습니다.
원래는 배치 처리만 하기 때문에 Load job 방식을 사용했는데, 가격 정책에서 스트리밍 방식에 대해 알아보니 200MB마다 $0.01의 비용을 추가로 내고 무료 한도도 없습니다. 그래서 기존에 사용하던 Load job 방식을 함수로 정의해서 호출하려고 합니다.
def load_table_from_json(
table: str,
project_id: str,
data: List[Dict],
account: Dict[str,str],
...
):
with BigQueryClient.from_service_account_info(account, project=project_id) as client:
destination = f"{project_id}.{table}"
job_config = LoadJobConfig(write_disposition="WRITE_APPEND")
client.load_table_from_json(data, destination, job_config=job_config).result()JSON 형식의 딕셔너리 리스트 객체를 BigQuery에 적재하는 함수는 위와 같이 구현할 수 있습니다. 참고로, BigQuery Storage Write API를 지원하는 google-cloud-bigquery 패키지를 사용합니다.
load_table_from_json() 은 JSON이 지원하지 않는 날짜 타입 등을 굳이 문자열로 바꿔줘야 해서, pandas.DataFrame 을 사용한다면 load_table_from_dataframe() 을 사용하는게 더 편합니다.
프로젝트 목적
프로젝트 배경 요약
- 이커머스 플랫폼에서 필요한 데이터를 수집 및 가공하는 기능은 이미 구현되어 있습니다.
- 하지만, 고수준으로 추상화된 프레임워크에 얽혀있어 원하는 부분만 떼어내기가 어렵습니다.
- 프레임워크 수정과 테스트 하기가 불편해 기존 ETL 프로세스에서 수집, 변환, 적재 기능을 철저하게 구분하고자 합니다.
목표와 방향성
- 처음부터 ETL 프로세스를 구분한 프로젝트 구조를 설계합니다.
- 데이터 수집은
Collecotr, 데이터 변환은Parser클래스로 정의합니다.
a.Collector와Parser는 서로 독립적이며, 변경사항이 서로에게 영향을 끼치면 안됩니다. - Airflow Worker에서 API를 호출하는 것을 목적으로 지연 로딩 등 최적화를 진행합니다.
프로젝트 구조
최근에 uv라는 패키지 관리자를 알게되고 [Python] uv 프로젝트 구성하고 배포하기 게시글을 작성하면서 uv로 프로젝트를 PyPI에 배포하는 과정까지 수행해보았습니다. uv는 의존성 설치가 빠르고 편해 프로젝트 관리에 매우 유용한데 이를 기반으로 아래와 같이 프로젝트 구조를 설계했습니다.
./
├── src/
│ └── linkmerce/
│ ├── auth/
│ ├── collect/
│ │ └── base.py
│ ├── extensions/
│ ├── parse/
│ │ └── base.py
│ ├── utils/
│ ├── exceptions.py
│ └── types.py
├── LICENSE
├── README.md
├── pyproject.toml
└── uv.lock의존성과 PyPI 배포를 위한 설정은 pyproject.toml 에 명시되어 있습니다. uv.lock 은 의존성의 바이너리 경로를 기록하여 다른 환경에서 프로젝트를 이어갈 때 동일한 가상환경을 만들 수 있습니다.
통합 API를 구성하는 실제 소스코드는 uv에서 권장하는 ./src/ 경로 아래에서 추가했습니다. __init__.py 같이 설명이 필요없는 파일은 제외했습니다.
패키지 경로인 ./src/linkmerce/ 아래에는 총 5개의 하위 경로와 2개의 하위 모듈이 있습니다. 중요한 순서대로 아래에서 설명하겠습니다.
collect
./src/linkmerce/collect/ 경로에는 Collector 를 상속받는 데이터 수집 기능이 정의되어 있습니다. Collector 는 base.py 모듈에 정의되어 있습니다.
Collector 의 최상위 클래스는 세션 객체를 사용한다는 의미의 BaseSessionClient 로부터 시작합니다. BaseSessionClient 는 request() 메서드를 구현해야 하는 추상 클래스입니다.
class BaseSessionClient(metaclass=ABCMeta):
def __init__(self,
session: Session | ClientSession | None = None,
params: Dict = dict(),
body: Dict = dict(),
headers: Dict = dict(),
):
self.set_session(session)
self.set_request_params(**params)
self.set_request_body(**body)
self.set_request_headers(**headers)
@abstractmethod
def request(self, **kwargs):
raise NotImplementedError("The 'request' method must be implemented.")BaseSessionClient 를 상속받으면서 requests.Session 객체를 사용하는 RequestSessionClient 는 아래와 request() 메서드를 구현했습니다. 실제로는 request() 메서드를 직접 호출하지는 않고 request_text(), request_json() 같이 응답 결과에 대한 타입을 명시한 메서드를 사용합니다.
class RequestSessionClient(BaseSessionClient):
def request(
self,
method: str,
url: str,
params: Dict | List[Tuple] | bytes | None = None,
data: Dict | List[Tuple] | bytes | IO | None = None,
json: JsonSerialize | None = None,
headers: Dict[str,str] = None,
cookies: Dict | RequestsCookieJar = None,
**kwargs
) -> Response:
return self.get_session().request(method, url, params=params, data=data, json=json, headers=headers, cookies=cookies, **kwargs)구현하는 입장에선 다소 불편할 순 있지만, 사용자의 편의를 위해 동기식 요청 방식인 request() 뿐 아니라 비동기식 요청 방식인 request_async() 도 정의해야 합니다. aiohttp.ClientSession 객체를 사용하는 AiohttpSessionClient 는 아래와 같이 request_async() 메서드를 구현했습니다.
request_async() 메서드는 매개변수 등이 request() 와 동일하지만, 함수를 코루틴으로 재사용할 수는 없어서 굳이 코루틴으로 다시 정의했습니다.
하지만, ClientResponse 는 사용 후 close() 를 호출하거나 애초부터 async with 로 감싸줄 필요가 있어서 request_async() 를 직접 호출하지 않고 request_async_text(), request_async_json() 같이 별도의 메서드를 사용합니다.
class AiohttpSessionClient(BaseSessionClient):
def request(self, *args, **kwargs):
raise NotImplementedError("This feature does not support synchronous requests. Please use the request_async method instead.")
async def request_async(
self,
method: str,
url: str,
params: Dict | List[Tuple] | bytes | None = None,
data: Dict | List[Tuple] | bytes | IO | None = None,
json: JsonSerialize | None = None,
headers: Dict[str,str] = None,
cookies: Dict | LooseCookies = None,
**kwargs
) -> ClientResponse:
return await self.get_session().request(method, url, params=params, data=data, json=json, headers=headers, cookies=cookies, **kwargs)Collector 는 위 두 가지 클래스를 상속받으면서 collect() 추상 메서드를 가진 추상 클래스입니다. 필요한 request() 메서드는 이미 부모 클래스에서 구현했기 때문에 특별히 추가할건 없습니다.
class Collector(RequestSessionClient, AiohttpSessionClient, metaclass=ABCMeta):
method: str
url: str
@abstractmethod
def collect(self, **kwargs) -> Any:
raise NotImplementedError("This feature does not support synchronous requests. Please use the collect_async method instead.")
async def collect_async(self, **kwargs):
raise NotImplementedError("This feature does not support asynchronous requests. Please use the collect method instead.")parse
./src/linkmerce/parse/ 경로에는 Parser 를 상속받는 데이터 수집 기능이 정의되어 있습니다. Parser 는 base.py 모듈에 정의되어 있습니다.
Parser 는 최상위 클래스이며 parse() 메서드를 구현해야 하는 추상 클래스입니다.
class Parser(metaclass=ABCMeta):
@abstractmethod
def __init__(self, obj: Any, *args, **kwargs):
raise NotImplementedError("The '__init__' method must be implemented.")
@abstractmethod
def parse(self, obj: Any, *args, **kwargs) -> Any:
raise NotImplementedError("The 'parse' method must be implemented.")Parser 는 파싱 결과에 따라 다양한 클래스로 세분화됩니다. 현재는 딕셔너리의 리스트형만 취급하고 있습니다. 먼저, 리스트의 기반이 되는 ListParser 를 아래와 같이 정의할 수 있습니다. 해당 클래스를 직접적으로 사용할 일은 없을 것 같아서 기본적인 기능만 구현했습니다.
class ListParser(list, Parser):
sequential: bool = True
def __init__(self, obj: Any, *args, **kwargs):
list.__init__(self, self.parse(obj, *args, **kwargs))
def parse(self, obj: Any, *args, **kwargs) -> Iterable:
if isinstance(obj, Sequence if self.sequential else Iterable):
return obj
else:
self.raise_parse_error()다음으로, 딕셔너리의 리스트형을 취급하는 RecordsParser 를 아래와 같이 정의할 수 있습니다. 한주 전쯤에는 DictParser 를 정의하고 RecordsParser 의 dtype 으로 할당했지만, 이번주에 DuckDB라는 좋은 툴을 알게되어서 아래에서 새로운 클래스를 만들었습니다.
class RecordsParser(ListParser):
dtype: Type = dict
drop_empty: bool = True
sequential: bool = True
def parse(self, obj: Any, *args, **kwargs) -> Iterable:
if isinstance(obj, Sequence if self.sequential else Iterable):
iterable = map(lambda record: self.map(record, *args, **kwargs), obj)
return filter(None, iterable) if self.drop_empty else iterable
else:
self.raise_parse_error()
def map(self, record: Any, *args, **kwargs) -> Dict:
return self.dtype(record, *args, **kwargs)DuckDB는 인메모리 데이터베이스로, 파이썬에서는 duckdb 패키지를 사용해서 파이썬 객체를 DB에 올려 SQL문을 사용해 데이터 가공을 처리할 수 있습니다.
일반적인 HTTP 응답 결과인 중첩된 JSON을 파싱하는데는 다소 복잡한 참조를 거쳐야 하는데, DuckDB를 사용하면 SELECT product.category.name AS categoryName 과 같이 중첩된 구조를 간단하게 파싱할 수 있습니다. 또한, TRY_CAST, NULLIF 등 편리한 SQL 함수를 사용할 수 있습니다.
해당 SQL문을 make_query() 메서드에서 정의합니다.
class QueryParser(RecordsParser, metaclass=ABCMeta):
table_alias: str = "data"
def __init__(self, obj: Any, *args, **kwargs):
super().__init__(obj, *args, **kwargs)
def parse(self, obj: Any, *args, **kwargs) -> Iterable:
if isinstance(obj, Sequence if self.sequential else Iterable):
return self.select(obj, *args, **kwargs)
else:
self.raise_parse_error()
def select(self, obj: Sequence[Any], *args, ...) -> List[Any]:
query = self.make_query(*args, **kwargs)
from linkmerce.utils.duckdb import ... as select
return select(query, params={self.table_alias: obj})
@abstractmethod
def make_query(self, *args, **kwargs) -> str:
raise NotImplementedError("The 'make_query' method must be implemented.")참고로, collect/ 경로와 parse/ 경로는 정확히 동일한 구조를 갖고 있습니다. 어떠한 Collector 에서 대응되는 위치의 Parser 를 참조하는게 다소 귀찮아서 Collector 에 import_parser() 메서드를 추가했습니다.
import_parser() 메서드는 현재 경로에 대한 문자열을 parse/ 경로로 가공하고, importlib 패키지를 사용하여 가공된 경로에 있는 Parser 생성자를 가져옵니다.
예를 들어,
.../collect/naver/api/search.py모듈에BlogSearchCollector가 있고,.../parse/naver/api/search.py모듈에BlogSearchParser가 있다고 가정합니다.
이때, BlogSearch Collector에서 import_parser("BlogSearch") 를 호출하면 BlogSearch Parser를 가져올 수 있습니다.
class Collector(...):
def import_parser(self, name: str, module_name: Literal["parse"] | str = "parse") -> Callable:
from importlib import import_module
if module_name == "parse":
from inspect import getmodule
module_name = getmodule(self.collect).__name__.replace("collect", "parse", 1)
module = import_module(module_name, __name__)
return getattr(module, name)auth
아직 추상 팩토리도 구현되지 않았지만, 향후 로그인 또는 API 인증과 관련한 기능이 정의될 경로입니다.
로그인 후 쿠키 문자열을 로컬 스토리지에 파일로 저장하는 방식을 구상하고 있습니다.
utils
프로젝트 전체에서 사용하는 유틸리티 함수를 정의합니다. 함수가 의존하는 외부 패키지를 기준으로 별도의 모듈로 구분합니다.
예를 들어, ./src/linkmerce/utils/duckdb.py 모듈에서 아래와 같은 함수를 정의할 수 있습니다. duckdb 패키지와 관련된 모든 함수는 해당 모듈에 기록됩니다. 예시인 select_to_json() 함수는 SELECT 쿼리를 실행하여 그 결과를 JSON 형식으로 반환하는 기능을 합니다.
def select_to_json(
query: str,
params: Dict | None = None,
conn: DuckDBPyConnection | None = None,
) -> List[Dict]:
relation = (conn if conn is not None else duckdb).execute(query, parameters=params)
columns = [column[NAME] for column in relation.description]
return [dict(zip(columns, row)) for row in relation.fetchall()]extensions
프로젝트 의존성에 아직 추가되지 않은 패키지를 사용하지만, 향후 의존성을 추가하고 utils/ 경로에 옮길 목적의 함수들을 extensions/ 경로에 미리 정의합니다.
예를 들어, ./src/linkmerce/extensions/pandas.py 모듈에서 아래와 같은 함수가 정의되어 있습니다. 아직까지 pandas 패키지가 의존성에 추가되지 않았지만, 향후 엑셀 파일을 읽는 것과 같은 기능을 사용할 일이 있을 것 같아 미리 정의했습니다.
def read_table(
io: bytes | str,
table_format: Literal["excel", "csv", "html", "xml"] | Sequence = "xlsx",
sheet_name: str | int | List | None = 0,
header: int | Sequence[int] | None = 0,
dtype: DtypeArg | None = None,
engine: Literal["xlrd", "openpyxl", "odf", "pyxlsb", "calamine"] | None = None,
parse_dates: bool | Sequence[int] | Sequence[Sequence[str] | Sequence[int]] | Dict[str, Sequence[int] | list[str]] = None,
file_pattern: Dict | None = None,
**kwargs
) -> pd.DataFrame:
...exceptions.py
프로젝트 전체에서 공통적으로 사용하는 예외 타입을 정의합니다.
class ParseError(ValueError):
...
class RequestError(RuntimeError):
...
class UnauthorizedError(RuntimeError):
...types.py
프로젝트 전체에서 공통적으로 사용하는 타입 힌트를 정의합니다.
from typing import Dict, IO, List, Union
JsonObject = Union[Dict, List]
JsonSerialize = Union[Dict, List, bytes, IO]앞으로의 계획
이번 글에서는 프로젝트를 시작하게 된 배경과 프로젝트의 기본적인 구조를 소개했습니다.
이미 실제로 데이터 수집 및 변환 기능을 2개 정도 구현했는데, 앞으로는 실제 구현 사례와 구현 과정에서 발생하는 특이사항 등을 기록할 예정입니다.
또한, auth/ 에 대한 틀이 만들어진다면 로그인 동작 구현 사례와 함께 설명할 수 있을 것입니다.
서두에 안내했듯이 해당 프로젝트는 Github 바로가기에서 추적할 수 있습니다.
지금은 이커머스 플랫폼 대상의 웹 스크래핑에 초점이 맞춰져 있지만, 향후에 사방넷이나 이지어드민 같은 쇼핑몰 통합관리 솔루션에서 제공하는 주문내역 추적, 발주처리 및 배송조회, 교환/반품 관리 등의 기능이 추가되고, 커머스 도메인 경험이 있는 분들이 지원하는 오픈소스 프로젝트로 발전하기를 기대하고 있습니다.
