메인 스레드
모든 자바 애플리케이션은 메인 스레드가 main() 메소드를 실행하면서 시작되며, main() 메소드에서 마지막 코드를 실행하거나 return문을 만나면 종료된다.
메인 스레드는 필요에 따라 작업 스레드를 만들어서 병렬로 코드를 실행할 수 있다.
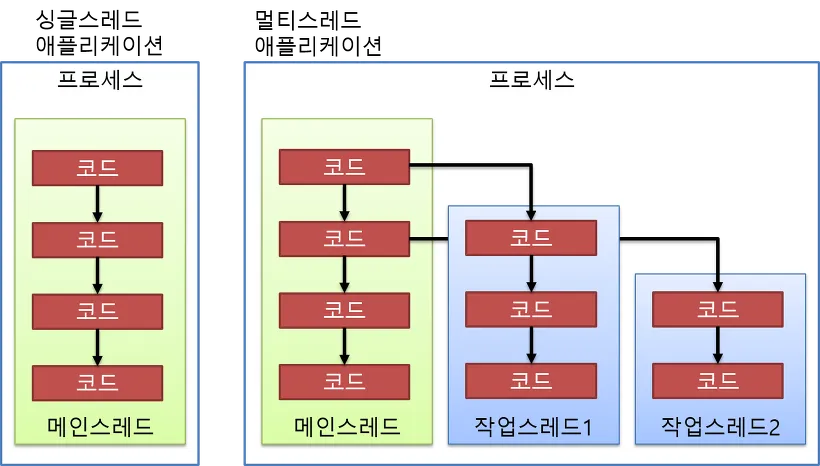
싱글 스레드 애플리케이션에서는 메인 스레드가 종료하면 프로세스도 종료되지만, 멀티 스레드 애플리케이션에서는 실행 중인 스레드가 하나라도 있으면 프로세스는 종료되지 않는다. 특히 메인 스레드가 작업 스레드보다 먼저 종료되어도 작업 스레드가 실행 중이라면 프로세스는 종료되지 않는 점을 주의해야 한다.
작업 스레드 생성과 실행
자바에서는 작업 스레드도 객체로 생성되므로 클래스가 필요하다. 크게 Thread 클래스를 직접 객체화하는 방법과 Thread를 상속한 클래스를 생성하는 방법이 있다.
Thread 클래스에서 직접 생성
Thread 클래스로부터 작업 스레드 객체를 직접 생성하려면 다음과 같이 Runnable 을 매개값으로 갖는 생성자를 호출하면 된다.
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
}});
Runnable은 작업 스레드가 실행할 수 있는 코드를 가지고 있는 객체이다. 다만, Runnable은 인터페이스이므로 구현 클래스를 정의해 주어야 한다. run() 메소드를 재정의해 주면 되고, 위 코드 대신 람다식으로 간단하게 표현해 주어도 된다.
Thread thread = new Thread(() -> System.out.println("작업 스레드입니다."));
작업 스레드는 생성되자마자 바로 실행되지는 않고, 별도로 start() 메소드를 호출해야한다. 해당 메소드가 호출되면 작업 스레드가 매개값으로 받은 Runnable의 run() 메소드를 호출하여 자신의 작업을 처리한다.
이제 스레드를 이해하기 위하여 예제를 하나 살펴 보자. 이번에 볼 예제는 0.5초 주기로 비프(beep)음을 발생시키면서 동시에 프린팅하는 작업이다.
메인 스레드만 사용한 예제
public static void main(String[] args) {
Toolkit toolkit = Toolkit.getDefaultToolkit();
for (int i = 0; i < 5; i++) {
toolkit.beep();
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
for (int i = 0; i < 5; i++) {
System.out.println("띵");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}메인 스레드만 있다면 비프음을 내는 작업이 다 끝나야만 프린팅이 가능하다. 실제로 실행해보면 비프음이 5번 발생이 발생한 이후에 출력이 되는 것을 알 수 있다.
메인 스레드와 작업 스레드를 동시에 사용한 예제
public static void main(String[] args) {
Thread thread = new Thread(() -> {
Toolkit toolkit = Toolkit.getDefaultToolkit();
for (int i = 0; i < 5; i++) {
toolkit.beep();
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();;
}
}
});
thread.start();
for (int i = 0; i < 5; i++) {
System.out.println("띵");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}메인 스레드에서 비프음을 발생하던 일을 작업 스레드에게 위임하였다. thread.start() 를 호출하는 순간 새로운 작업 스레드가 비프음을 발생하는 일을 시작하고, 메인 스레드는 그 아래 비프음을 출력하는 작업을 시작한다. 거의 동시에 비프음이 발생하면 출력이 되는 것을 알 수 있다.
Thread 하위 클래스에서 작성
말 그대로 Thread 클래스를 상속하여 run() 메소드를 재정의하는 방법이다.
public class BeepThread extends Thread {
@Override
public void run() {
Toolkit toolkit = Toolkit.getDefaultToolkit();
for (int i = 0; i < 5; i++) {
toolkit.beep();
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();;
}
}
}
// 추가 로직 작성 가능
}
public class Main {
public static void main(String[] args) {
Thread thread = new BeepThread();
thread.start();
for (int i = 0; i < 5; i++) {
System.out.println("띵");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}람다식을 사용한 예제와 거의 유사하지만, Thread 클래스를 상속하여 만든 하위 클래스로 작업 스레드를 구현하면 run() 메소드 외에 프로그래머가 원하는 메소드를 더 정의할 수 있다는 장점이 있다.
스레드 우선 순위
동시성 (Concurrency) vs 병렬성 (Parallelism)
동시성과 병렬성은 두 단어 모두 말 그대로 동시에 하는 것이 아닌가 생각이 들어서 혼동하기 쉽다.
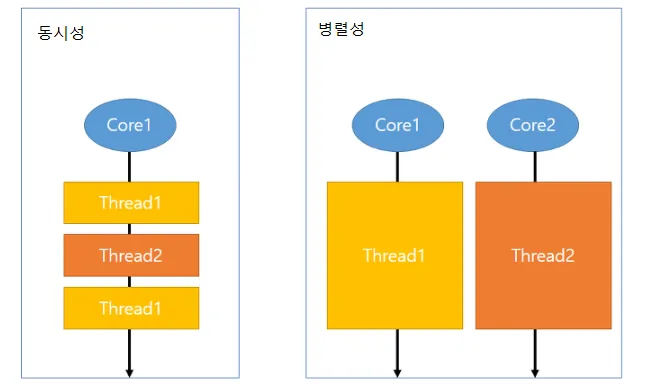
동시성 (병행성)
- 멀티 작업을 위해 하나의 코어에서 멀티 스레드가 번걸아가며 실행하는 성질이다.
- CPU 하나가 Time Sharing 기법을 통해 실제로 동시에 스레드가 실행되는 것은 아니지만, CPU 제어권을 매우 빠르게 스레드에게 줬다가 뺏으면서 사람이 보기에 마치 동시에 실행되는 것처럼 보이는 것을 뜻한다.
병렬성
- 멀티 작업을 위해 멀티 코어에서 개별 스레드를 할당 받아 동시에 실행하는 성질이다.
- 정말 말 그대로 CPU 각자가 나뉘어서 각자의 일을 하여 실질적인 동시 작업을 수행하는 것을 뜻한다.
스레드 스케줄링
스레드의 개수가 코어의 수보다 많을 경우 어떤 스레드에게 CPU 제어권을 주어야 하는지 결정해야 하는데, 이를 스레드 스케줄링이라고 한다. 스레드 스케줄링에 의해 스레드들은 아주 짧은 시간에 번갈아가면서 자신이 run() 메소드를 조금씩 실행한다.
자바의 스레드 스케줄링은 주로 우선 순위 방식과 라운드 로빈 방식을 사용하며, 전자는 프로그래머가 특정 스레드에게 우선 순위를 코드로 제어할 수 있지만 후자는 JVM에 의해 정해지므로 코드로 제어할 수 없다. 그래서 우선 순위 방식으로 스레드 스케줄링 하는 방법만 이야기하고자 한다.
스레드의 개수가 코어의 수보다 많을 경우 어떤 스레드에게 CPU 제어권을 주어야 하는지 결정해야 하는데, 이를 스레드 스케줄링이라고 한다. 스레드 스케줄링에 의해 스레드들은 아주 짧은 시간에 번갈아가면서 자신이 run() 메소드를 조금씩 실행한다.
자바의 스레드 스케줄링은 주로 우선 순위 방식과 라운드 로빈 방식을 사용하며, 전자는 프로그래머가 특정 스레드에게 우선 순위를 코드로 제어할 수 있지만 후자는 JVM에 의해 정해지므로 코드로 제어할 수 없다. 그래서 우선 순위 방식으로 스레드 스케줄링 하는 방법만 이야기하고자 한다.
우선 순위 방식
우선 순위는 1에서부터 10까지 주어지는데, 숫자가 클수록 우선 순위가 높다. Thread의 setPriority() 메소드를 통해 구현할 수 있다.
public class Main {
public static void main(String[] args) {
for (int i = 1; i <= 10; i++) {
Thread thread = new CalcThread("thread" + i);
if (i != 10) {
thread.setPriority(Thread.MIN_PRIORITY);
} else {
thread.setPriority(Thread.MAX_PRIORITY);
}
thread.start();
}
}
}
public class CalcThread extends Thread {
public CalcThread(String name) {
setName(name);
}
@Override
public void run() {
for (int i = 0; i < 2_000_000_000; i++) {
}
System.out.println(getName());
}
}가독성을 위해 Thread의 우선 순위 상수를 사용했다. MIN은 1, NORM은 5, MAX는 10을 뜻한다. 위와 같이 코드를 작성하여 실행하면 다음과 같은 결과를 얻는다.
thread10
thread8
thread5
thread9
thread6
thread1
thread7
thread3
thread4
thread2thread10이 우선 순위가 가장 높으므로 먼저 수행되고, 나머지는 우선 순위가 같으므로 정확한 순서를 판단할 수는 없다. 실제로 실행해 보면 매번 다르게 나온다.
스레드 풀
서버는 동시에 여러 사용자가 접속할 수 있다. 하지만 요청이 들어올 때마다 스레드를 계속해서 만들면 운영체제의 자원이 빨리 소진될 수 있다. 따라서 스레드를 제한된 개수로 만들기 위해 사용하는 방법이 스레드 풀이다.
스레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해 놓고, 작업 큐에 들어오는 작업들을 하나씩 스레드가 맡아 처리하는 기법이다. 작업 처리 요청이 급격히 증가하더라도 작업 큐라는 곳에 작업이 대기하다가, 여유가 있는 스레드가 그것을 처리하므로 스레드의 전체 개수는 일정하며, 애플리케이션의 성능도 저하되지 않는다.
스레드 풀의 장점
- 자원 효율성
정해진 개수의 스레드를 생성하여 관리하기 때문에 스레드 생성 및 삭제에 따른 오버헤드를 줄일 수 있다. - 응답성 및 처리량 향상
작업을 대기 상태로 유지하여 작업 처리 속도를 향상시킬 수 있다. - 작업 제어
스레드 개수가 정해져 있으므로 동시에 처리할 수 있는 작업의 개수를 제한할 수 있게 된다. - 스레드의 안전한 운영
스레드의 생명주기를 관리해준다.
스프링과 같은 프레임워크에서는 스레드 풀의 스레드 개수를 수백 개 이상으로 운영g한다. 이는 Context Switching이 일어남에도 불구하고도 이런 선택을 내린 것인데, 왜 그럴까?
웹 애플리케이션에서는 빈번하게 네트워크, 파일 입출력과 같은 작업을 처리해야하는데 이들은 주로 Blokcing I/O 방식으로 동작한다. 즉 스레드가 입출력에 의해 차단되어 대기하는 것이다.
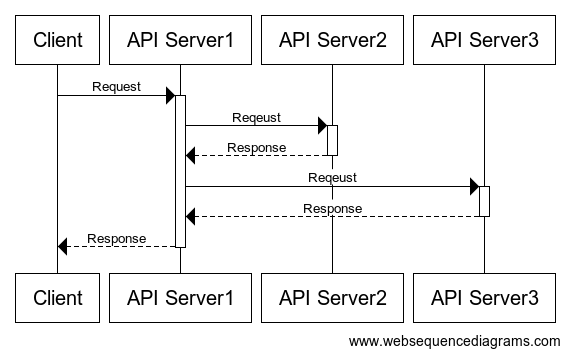
- 위의 그림에서는 네트워크 I/O의 Blocking I/O를 나타낸다.
- 클라이언트와 서버1, 서버2, 서버3이 있다고 가정하자. 클라이언트 PC에서 서버1에 요청을 보내면 서버1은 서버2와 서버3에 요청을 보낸다.
- 이 때 서버1에서 서버2로 요청을 보내는 시점에 서버1에서 실행된 스레드는 차단되어 서버2의 스레드가 끝나 응답을 반환하기 전까지 대기한다.
- 서버2의 응답이 반환되면 서버1에서 차단된 스레드는 다시 실행되어 서버3으로 요청을 보내고 응답이 반환될 때 까지 서버1의 스레드는 다시 차단된다.
- 이렇게 하나의 스레드가 I/O에 의해 차단되어 대기하는 것을 Blocking I/O라고 한다.
- Blocking I/O 방식의 문제점을 보완하기 위해서 멀티스레딩 기법으로 추가 스레드를 할당하여 차단된 시간을 효율적으로 사용할 수 있다.
즉 만일 스레드가 적다면 Blocking I/O로 인해 스레드가 block될 것이고 놀고 있는 CPU가 생기게 된다. 따라서 비싼 돈 주고 산 CPU에게 열심히 일을 시키기 위해 스레드를 늘리는 것이다.
