조회 (lookup)
Array
메모리상에서 연속적으로 데이터를 저장하였기 때문에 저장된 데이터에 즉시 접근(random access O(1))
Linked List
메모리상에서 불연속적으로 데이터를 저장하기 때문에 순차 접근(Sequential Access)만 가능, 즉 특정 Index의 데이터를 조회하기 위해 O(n)의 시간이 걸림.
삽입 / 삭제 (Insert / delete)
Array
맨 마지막 원소를 추가/삭제하면 O(1), 하지만 중간에 있는 원소를 삽입/삭제하면 해당 원소보다 큰 인덱스의 원소들을 한 칸씩 shift하는 비용(cost)이 발생. 따라서 시간복잡도는 O(n)
Linked List
어느 원소를 추가/삭제 하더라도 node에서 다음주소를 가르키는 부분만 다른 주소 값으로 변경하면 되기 때문에 shift 할 필요가 없어서 시간복잡도는 O(1), 하지만 index까지 도달하는데 O(n)의 시간이 걸리기 때문에, 실질적으로 추가/삭제 시 시간복잡도는 O(n)
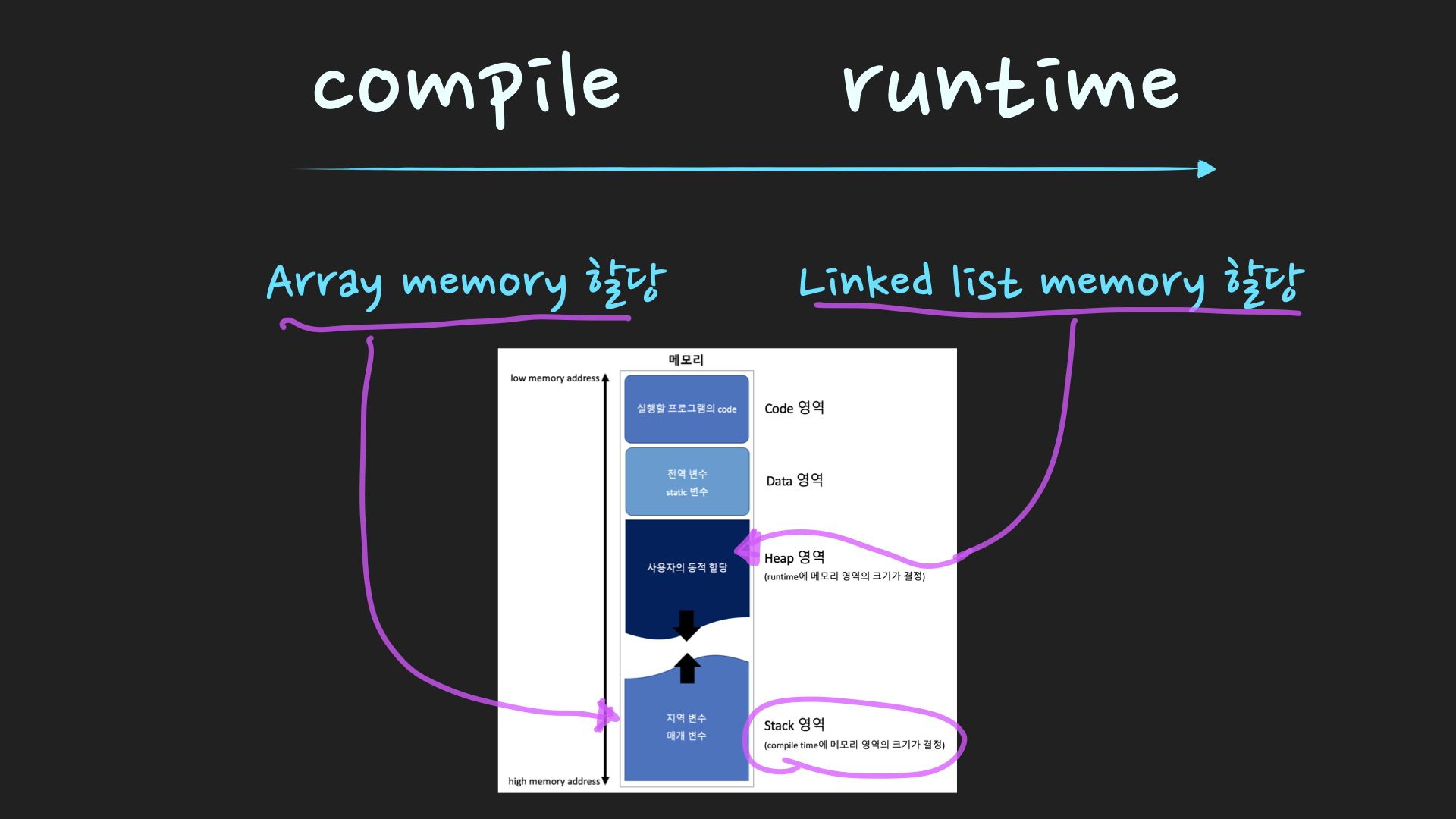
Memory
Array
데이터 접근과 append가 빠름, 하지만 fixed size를 설정하여 메모리 할당, 데이터가 저장 되어 있지 않더라도 메모리를 차지하고 있기 때문에 메모리 낭비가 발생
Linked List
runtime 중에서도 size를 늘리고 줄일 수 있음, initial size를 고민할 필요 없고 필요한 만큼 memory allocation을 하여 메모리 낭비가 발생하지 않음
