Process
실행파일 형태로 존재하던 program이 memory에 적재되어 CPU에 의해 실행(연산)되는 것
Memory
CPU가 직접 접근할 수 있는 컴퓨터 내부의 기억장치
- Code 영역 : 실행한 프로그램의 코드가 저장되는 메모리 영역
- Data 영역 : 전역 변수와 static 변수가 저장되는 메모리 영역
- Heap 영역 : 프로그래머가 직접 공간을 할당/해제 하는 메모리 영역
- Stack 영역 : 함수 호출 시 생성되는 지역 변수와 매개 변수가 저장되는 임시 메모리 영역
PC register
memory에 적재 되어있는 process code영역의 명령어중 다음번 연산에서 읽어야 할 명령어의 주소값을 PC register가 순차적으로 가리키게 되고, 해당 명령어를 읽어와서 CPU가 연산을 하게 되면 process가 실행
Multi process
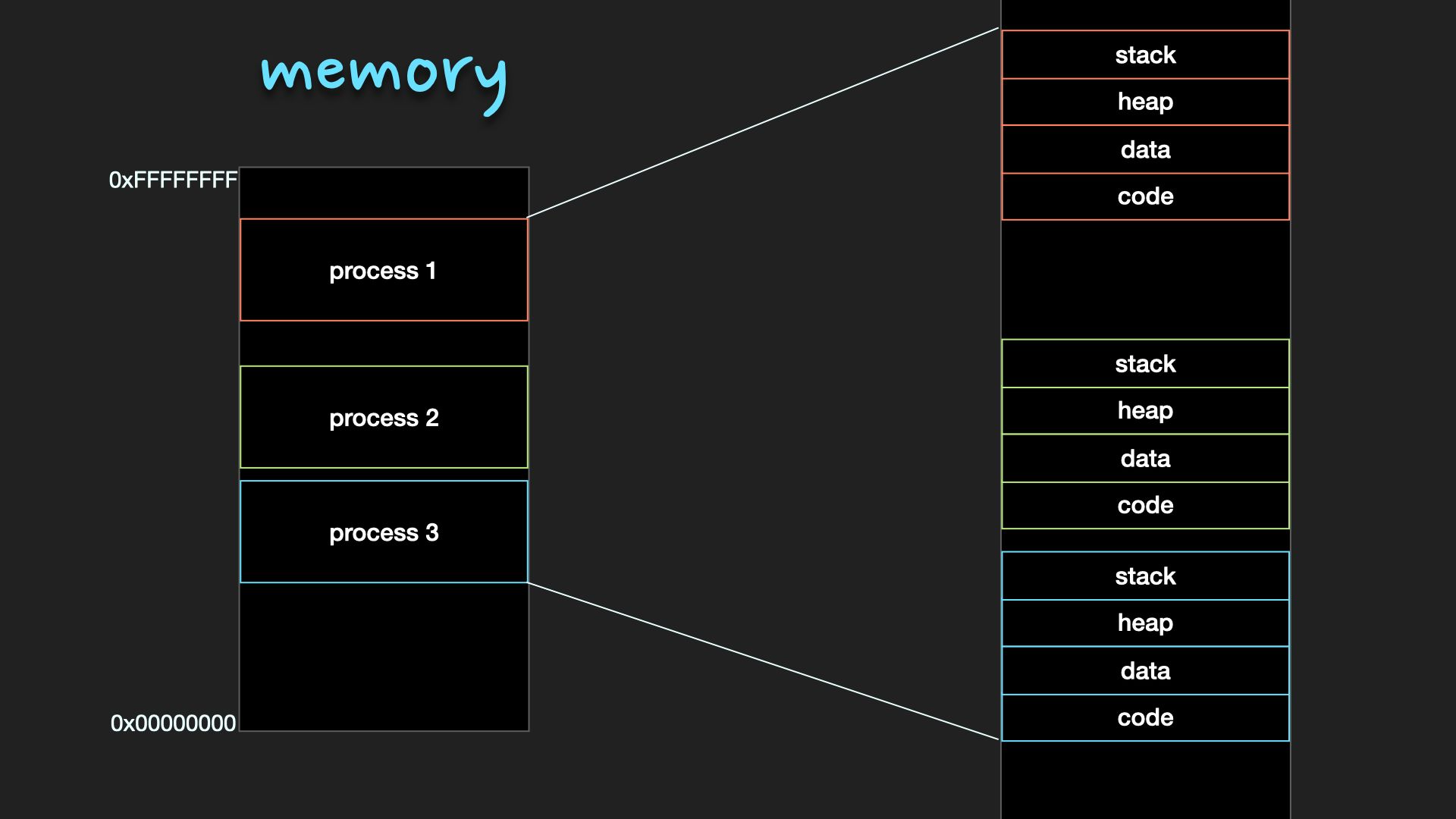
2개 이상의 process가 동시에 실행되는 것으로 CPU와 메모리를 공유
memory의 경우에는 여러 Process들이 각자의 Memory영역을 차지하여 동시에 적재
시분할 시스템
CPU의 작업시간을 여러 process들이 조금씩 나누어 쓰는 시스템
동시성(Concurrency)
CPU core가 1개일 때, 여러 process를 짧은 시간동안 번갈아 가면서 연산을 하게 되는 시분할 시스템으로 실행되는 것
병렬성(Parallelism)
CPU core가 여러개일 때, 각각의 core가 각각의 process를 연산함으로써 process가 동시에 실행되는 것
메모리 관리
여러 process가 동시에 memory에 적재된 경우, 서로 다른 process의 영역을 침범하지 않도록 각 process가 자신의 memory영역에만 접근하도록 운영체제가 관리(base, limit register)
CPU의 연산과 PC register
CPU는 PC register가 가리키고 있는 명령어를 읽어들여 연산을 진행
PC register에는 다음에 실행될 명령어의 주소값이 저장
Context
process가 현재 어떤 상태로 수행되고 있는지에 대한 총체적인 정보, PCB에 저장
PCB(Process Control Block)
운영체제가 프로세스를 표현한 자료구조
프로세스의 중요한 정보가 포함되어 있기 때문에 일반 사용자가 접근하지 못하도록 보호된 메모리 영역 안에 저장
일부 운영체제에서 PCB는 커널 스택에 위치, 보호를 받으면서도 비교적 접근하기가 편리하기 때문
| PCB | |
|---|---|
| Process State | new, running, waiting, halted 등의 state가 있다. |
| Process Number | 해당 process의 number |
| Program counter(PC) | 해당 process가 다음에 실행할 명령어의 주소를 가리킨다 |
| Registers | 컴퓨터 구조에 따라 다양한 수와 유형을 가진 register 값들 |
| Memory limits | base register, limit register, page table 또는 segment table 등 |
| ... |
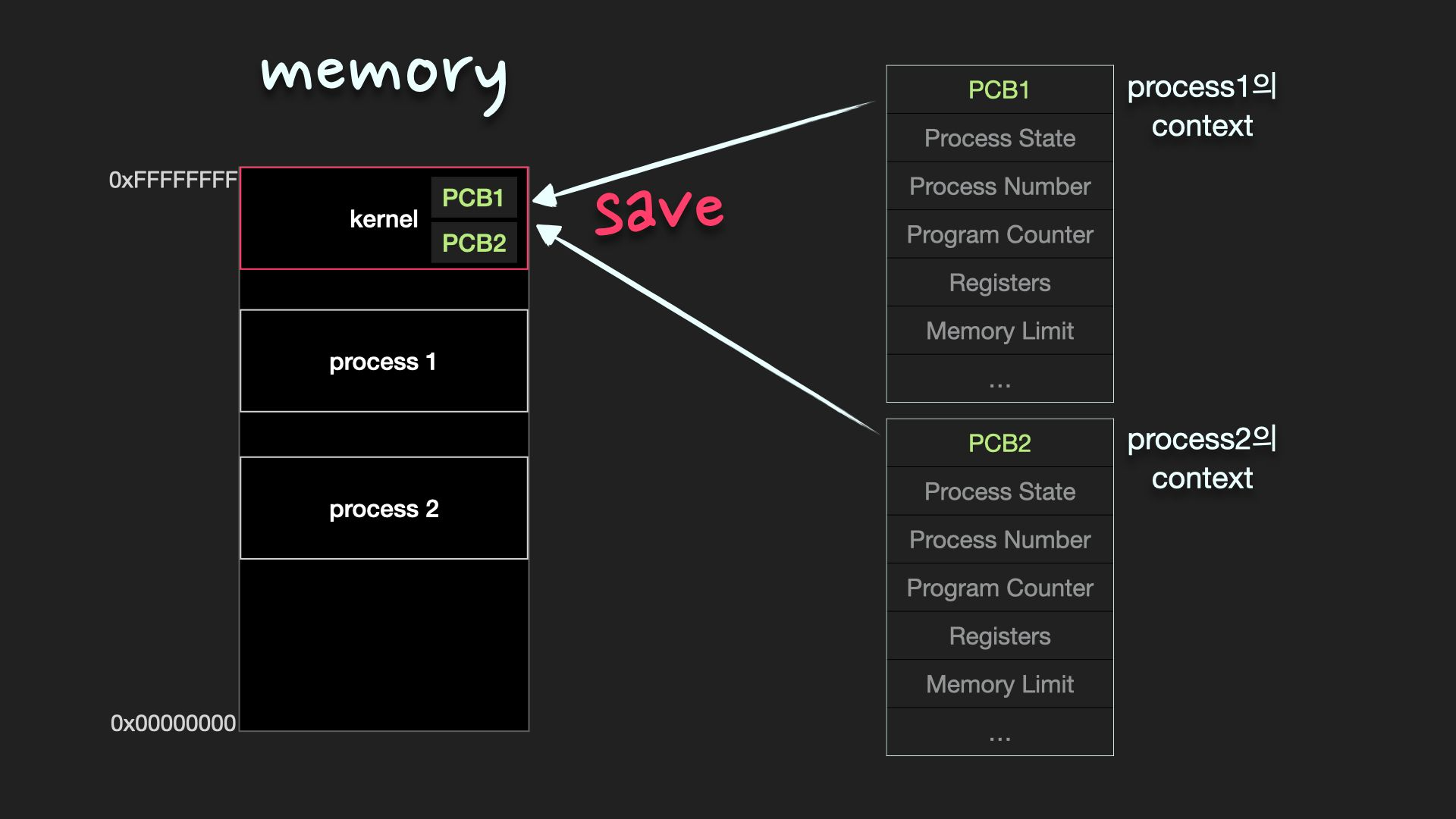
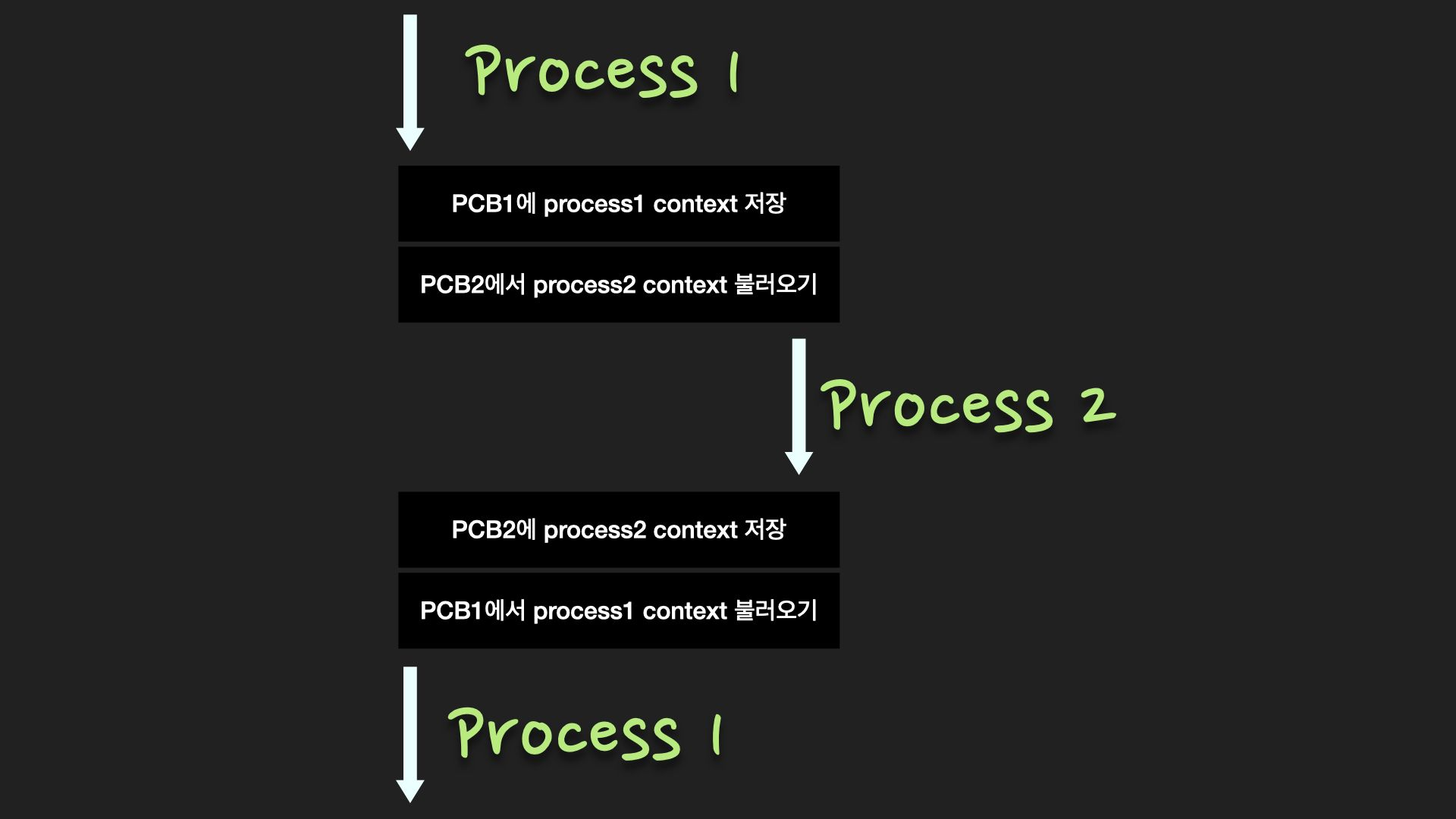
Context switch
한 프로세스에서 다른 프로세스로 CPU 제어권을 넘겨주는 것
이전의 프로세스의 상태르 PCB에 저장하여 보관하고 새로운 프로세스의 PCB를 읽어서 보관된 상태를 복구하는 작업이 이루어짐.
IPC
process는 각자 자신만의 독립적인 주소 공간을 가지는데, 다른 process가 이 주소 공간을 참조하는 것은 허용하지 않기 때문에 다른 process와 데이터를 주고 받을 수 없음
-> IPC 기법을 통해 process들 간 통신이 가능
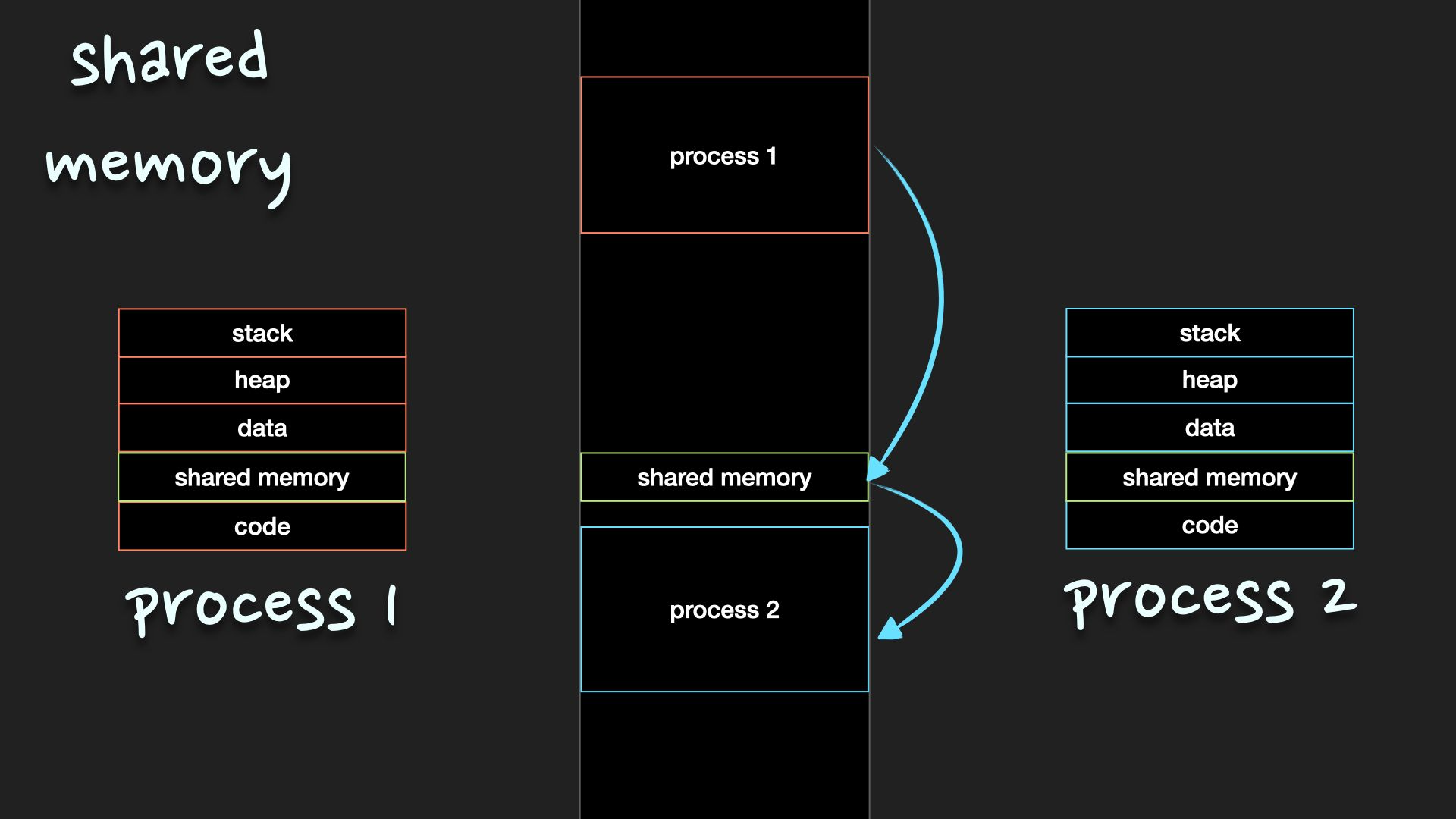
공유 메모리 (shared memory)
process들이 주소 공간의 일부를 공유하여 읽기/쓰기를 통해서 통신 수행
- process가 공유 메모리 할당을 kernel에 요청하면 kernel은 process에 메모리 공간을 할당
- 공유 메모리 영역이 구축된 이후에는 모든 접근이 일반적인 메모리 접근으로 취급되기 때문에 더 이상 kernel의 도움 없이도 각 process들이 해당 메모리 영역에 접근
- 장점 : kernel의 관여 없이 데이터를 통신 할 수 있기 때문에 IPC 속도가 빠름
- 단점 : 동시에 같은 메모리 위치에 접근하게 되면 일광선 문제가 발생
- 공유메모리, POSIX
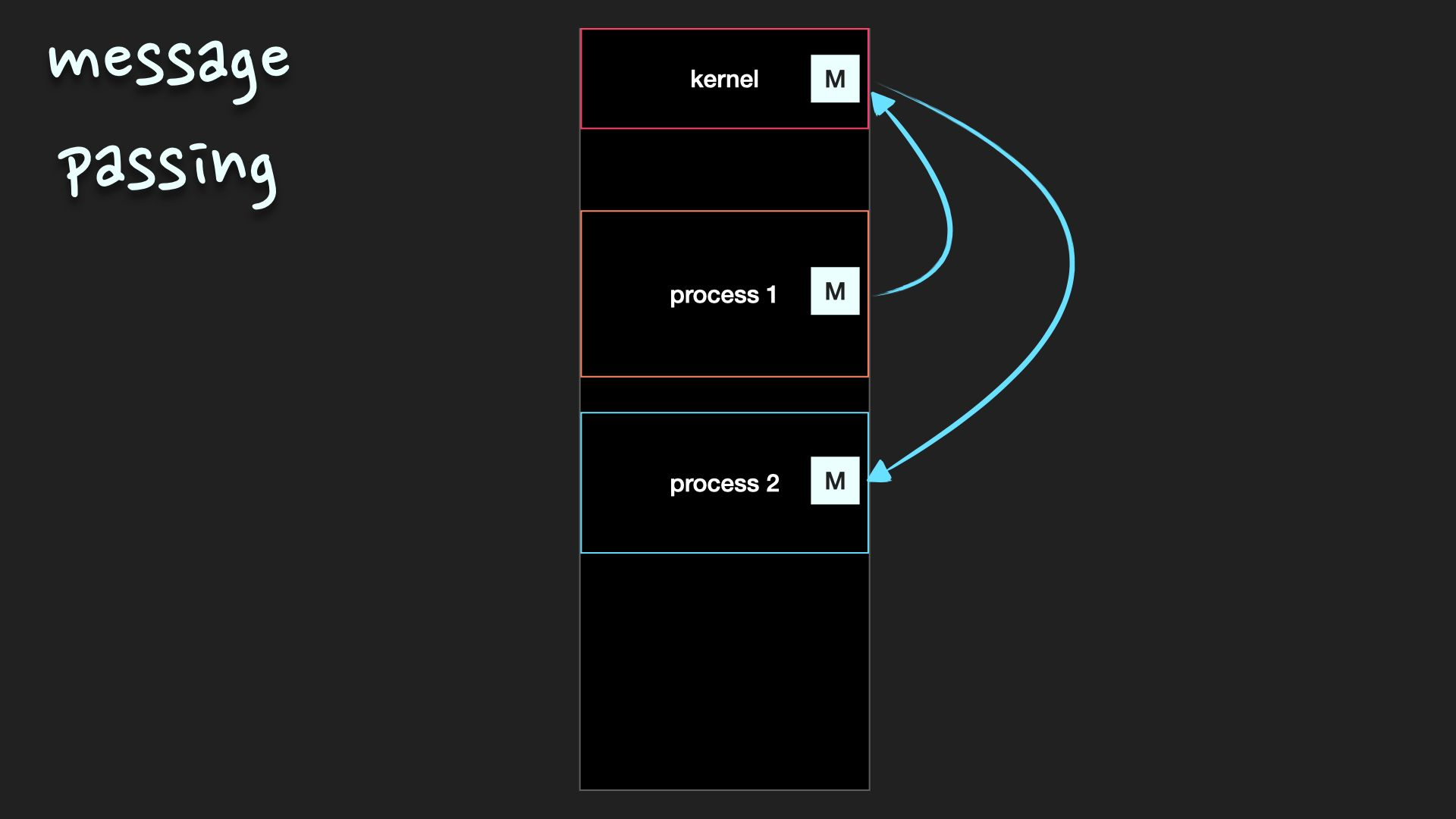
메시지 전달 (message passing)
system call을 사용하여 구현
- kernel을 통해 send(message)와 receive라는 두 가지 연산을 제공 받음
- 장점 : 충돌을 회피 할 필요가 없기 때문에 적은양의 데이터를 교환하는데 유용, 구현하기 쉬움
- 단점 : 메모리 공유보다 속도가 느림
- pipe, socket, message queue 등
Thread
한 process 내에서 실행되는 동작의(기능 function)의 단위, 독립적으로 함수 호출
Multi thread
하나의 process가 동시에 여러개의 일을 수행할 수 있도록 해주는 것, 즉 하나의 process에서 여러 작업을 병렬로 처리하기 위해 multi thread를 사용.
한 process 내에 여러개의 thread가 있고 각 thread들은 Stack 메모리를 제외한 나머지 영역(Code, Data, Heap) 공유
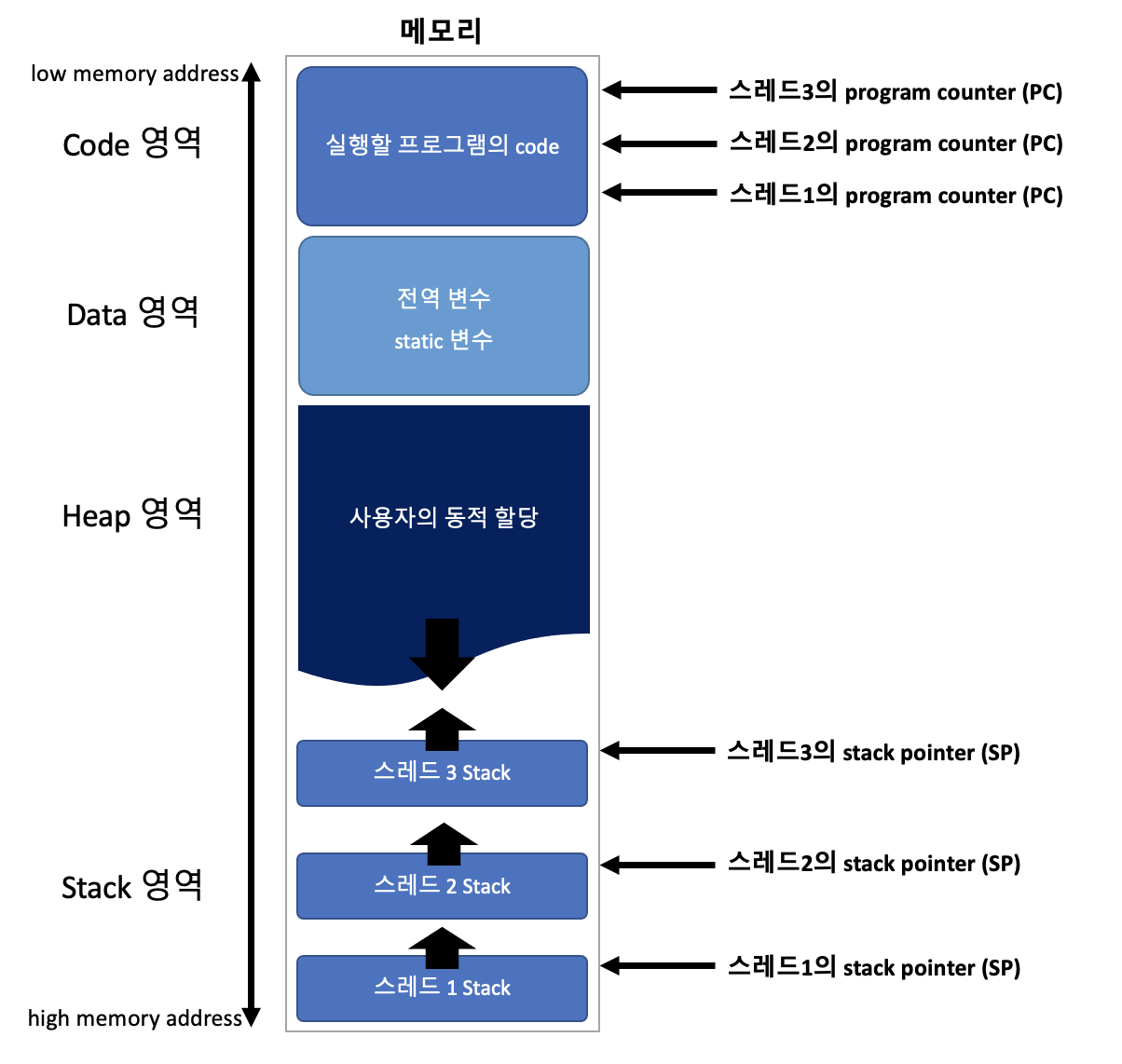
Stack memory & PC register
thread가 함수를 호출하기 위해서는 인자 전달, Return Address 저장, 함수 내 지역 변수 저장 등을 위한 독립적인 stack memory 공간이 필요.
multi thread에서는 각각의 threada마다 PC register를 보유
-> 한 process 내에서도 thread끼리 context swtich가 일어나는데, PC register에 code address가 저장되어 있어야 이어서 실행을 할 수 있기 때문.
교착상태(Deadlock)
둘 이상의 thread가 각기 다른 thread가 점유하고 있는 자원을 서로 기다릴 때, 무한 대기에 빠지는 상황
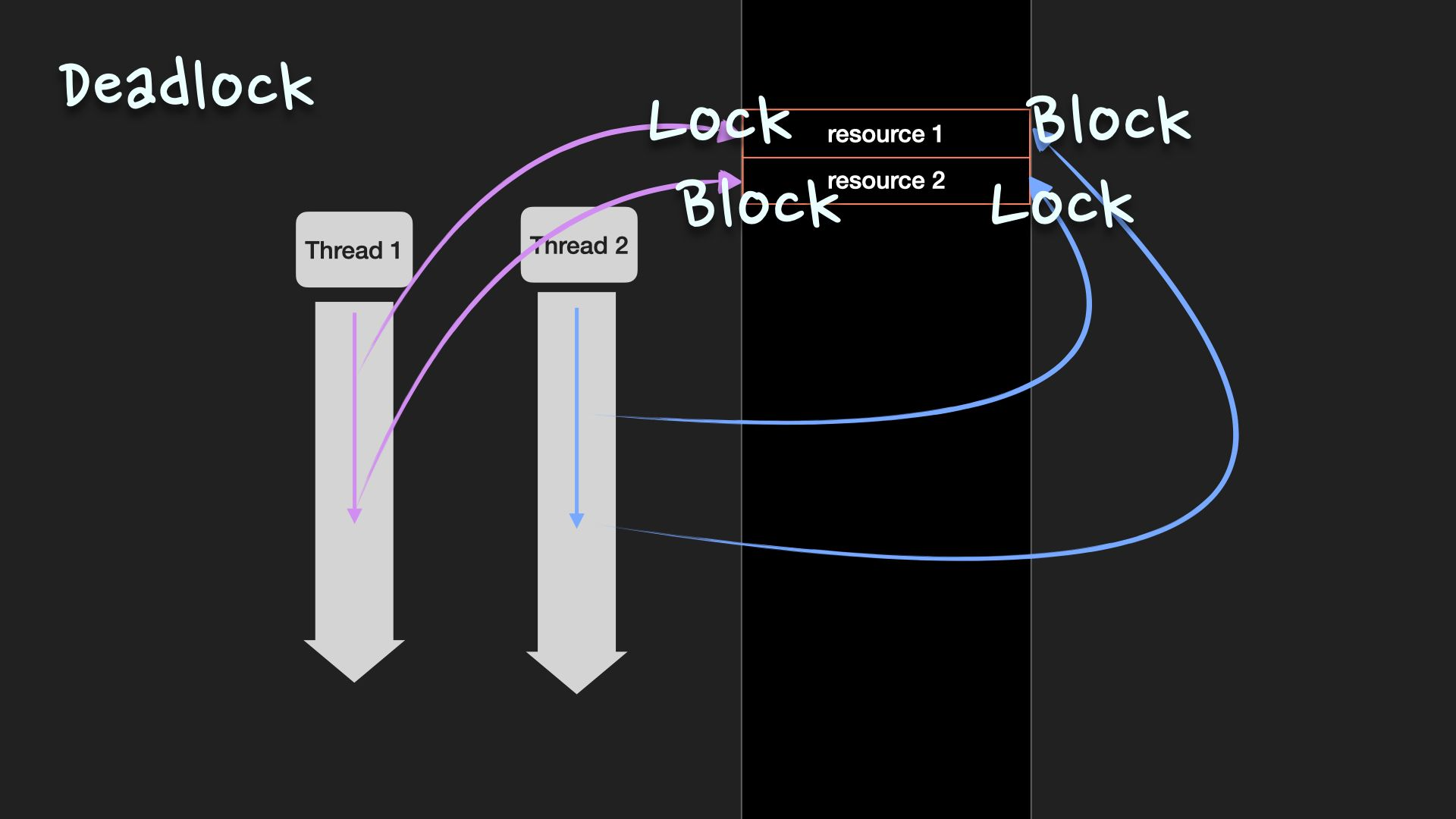
발생 조건
- 상호 배제(mutual exclusion)
- 동시에 한 thread만 자원을 점유할 수 있는 상황
- 다른 thread가 자원을 사용하려면 자원이 방출될 때까지 대기
- 점유 대기(hold-and-wait)
- thread가 자원을 보유한 상태에서 다른 thread가 보유한 자원을 추가로 기다리는 상황
- 비선점(no preemption)
- 다른 thread가 사용 중인 자원을 강제로 선점할 수 없는 상황
- 자원을 점유하고 있는 thread에 의해서만 자원이 방출
- 순환 대기(circular wait)
- 대기 중인 thread들이 순환 형태로 자원을 대기하고 있는 상황
해결방법
| 기법 | 설명 | 비고 |
|---|---|---|
| 무시 | deadlock 발생 확률이 낮은 시스템에서 아무런 조치도 취하지 않고 deadlock을 무시하는 방법 | - 무시 기법은 시스템 성능 저하가 없다는 큰 장점이 있습니다. |
| - 현대 시스템에서는 deadlock이 잘 발생하지 않고, 해결 비용이 크기 때문에 무시 방법이 많이 사용됩니다. | ||
| 예방 | 교착 상태의 4가지 발생 조건중 하나가 성립하지 않게 하는 방법 | - 순환 대기 조건이 성립하지 않도록 하는 것이 현실적으로 가능한 예방 기법입니다. |
| - 자원 사용의 효율성이 떨어지고 비용이 큽니다. | ||
| 회피 | thread가 앞으로 자원을 어떻게 요청할지에 대한 정보를 통해 순환 대기 상태가 발생하지 않도록 자원을 할당하는 방법 | - 자원 할당 그래프 알고리즘, 은행원 알고리즘 등을 사용하여 자원을 할당하여 deadlock을 회피합니다. |
| 탐지-회복 | 시스템 검사를 통해 deadlock 발생을 탐지하고, 이를 회복시키는 방법 | - 자원 사용의 효율성이 떨어지고 비용이 큽니다. |
Multi Process & Multi Thread
- Multi Thread는 Multi Process보다 적은 메모리 공간을 차지하고 context switching이 빠름
- Multi Process는 Multi Thread보다 많은 메모리 공간과 CPU 시간을 차지
- Multi Thread는 동기화 문제와 하나의 thread 장애로 전체 thread가 종료 될 위험이 있음
- Multi Process는 하나의 process가 죽더라도 다른 process에 영향을 주지 않아 안정성이 높음
| 메모리 사용 / CPU 시간 | Context switching | 안정성 | |
|---|---|---|---|
| multi process | 많은 메모리 공간 / CPU 시간 차지 | 느림 | 높음 |
| multi thread | 적은 메모리 공간 / CPU 시간 차지 | 빠름 | 낮음 |
장단점
Multi Thread가 Multi Process보다 좋은점
Multi Process -> Multi Thread로 구현 할 경우 메모리 공간과 시스템 자원 소모가 줄어듬, process를 생성하고 자원을 할당하는 등의 system call을 생략 할 수 있기 때문에 자원을 효율적으로 관리.
Context Switching 시 캐시 메모리를 초기화 할 필요가 없어서 속도가 빠름
데이터를 주고 받을 때를 비교해보면, process 간의 통신(IPC) 보다 Multi Thread 간의 통신 비용이 적기 때문에 통신으로 인한 오버헤드가 적음 -> 통신시 별도의 자원을 이용하지 않고, process에 할당된 Heap 영역 등을 이용하여 데이터를 주고 받기 때문
Multi Thread가 Multi Process보다 안좋은점
thread 간의 자원 공유 시 동기화 문제가 발생 할 수 있어서 프로그램 설계 시 주의가 필요, 하나의 thread에 문제가 생기면 process 내의 다른 thread에도 문제가 생길 수 있음
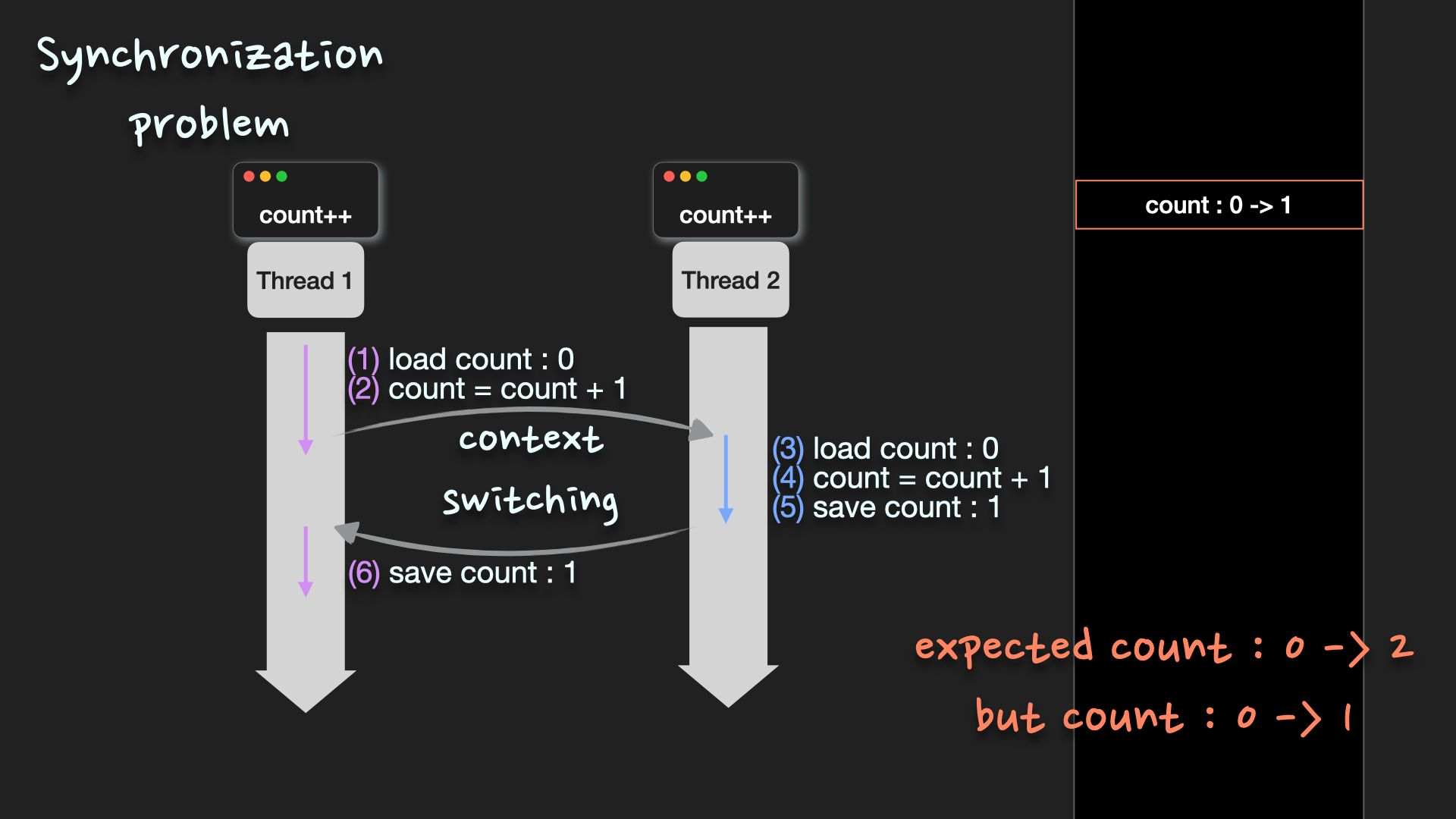
Multi process/thread 동기화 문제
서로 다른 thread가 메모리 영역을 공유하기 때문에 여러 thread가 동일한 자원에 동시에 접근하여 엉뚱한 값을 읽거나 수정하는 문제
경쟁상황(race condition)
실행 결과가 접근이 발생한 순서에 따라 달라지는 상황
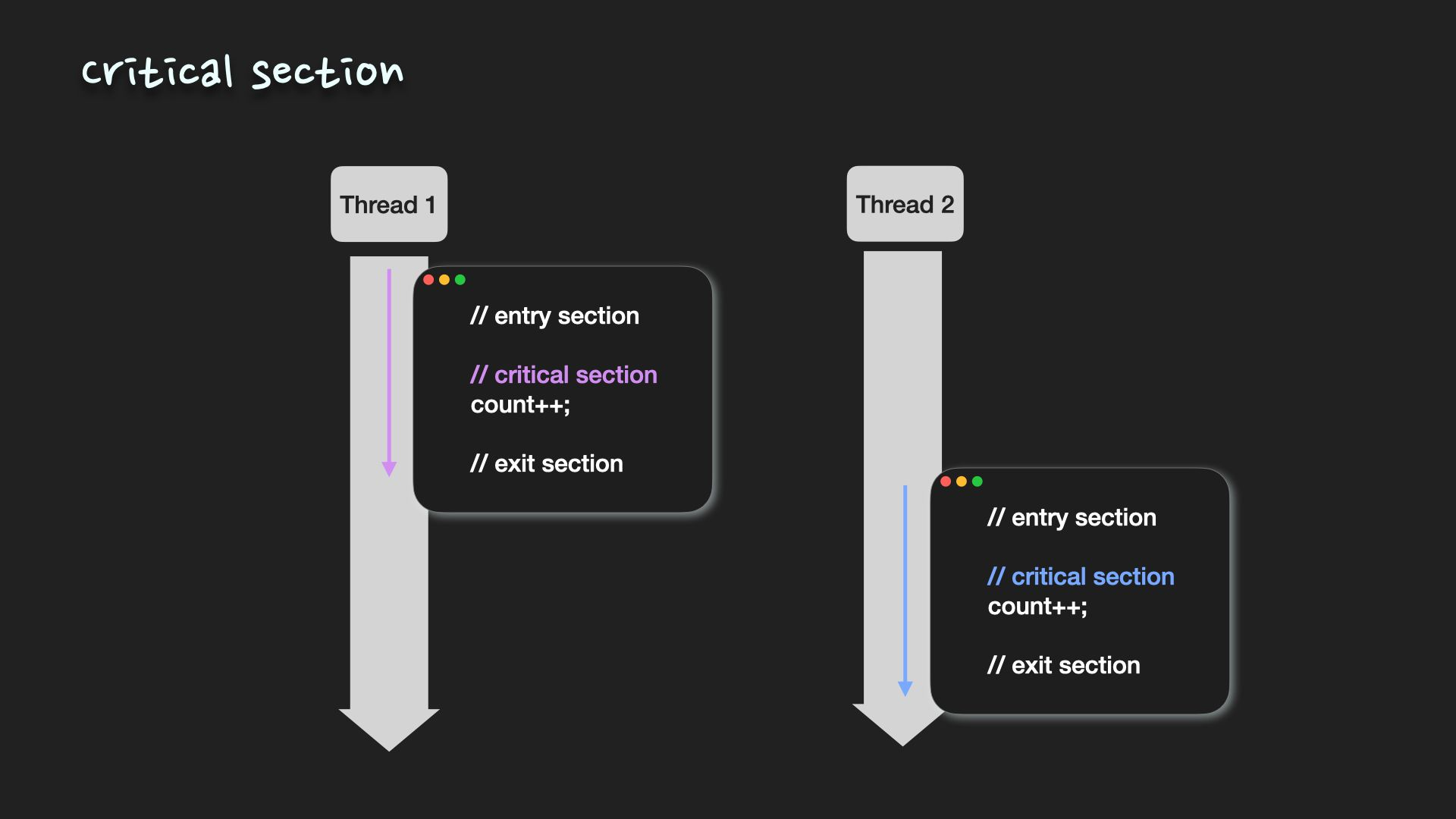
임계영역(critical section)
둘 이상의 process/thread가 동시에 동일한 자원에 접근하도록 하는 프로그램 코드 부분을 의미, 임계영역 내의 코드는 원자적으로(atomically) 실행이 되어야 함
-> 각각의 process/thread는 자신의 임계구역으로 진입하려면 진입 허가를 요청해야 함 (entry section), 진입이 허가되면 임계영역 실행 가능.
-> 임계영역이 끝나고 나면 exit section으로 퇴출
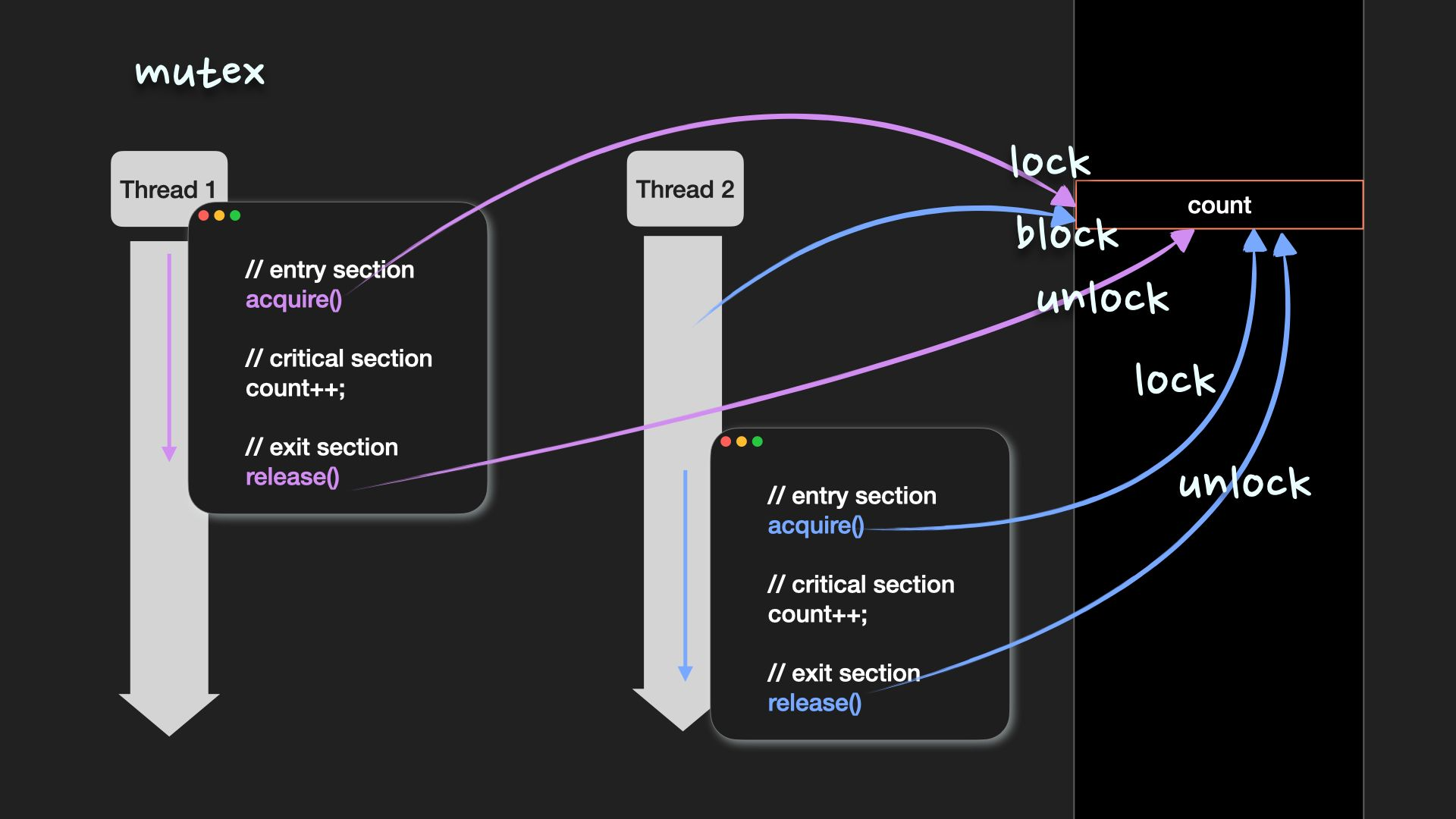
Mutex
mutual exclusion의 축약어, 공유자원에 접근할 수 있는 process/thread의 수를 1개로 제한
임계영역을 보호하고 경쟁상황을 방지하기 위해 process/thread는 임계영역에 들어가기 전에 반드시 lock을 획득해야 하고, 임계구역을 빠져나올 때 lock을 반환해야 함
acquire() // entry section
// critical section
release() // exit sectionbusy waiting은 다른 process/thread가 생산적으로 사용할 수 있는 CPU를 낭비한다는 단점이 있음
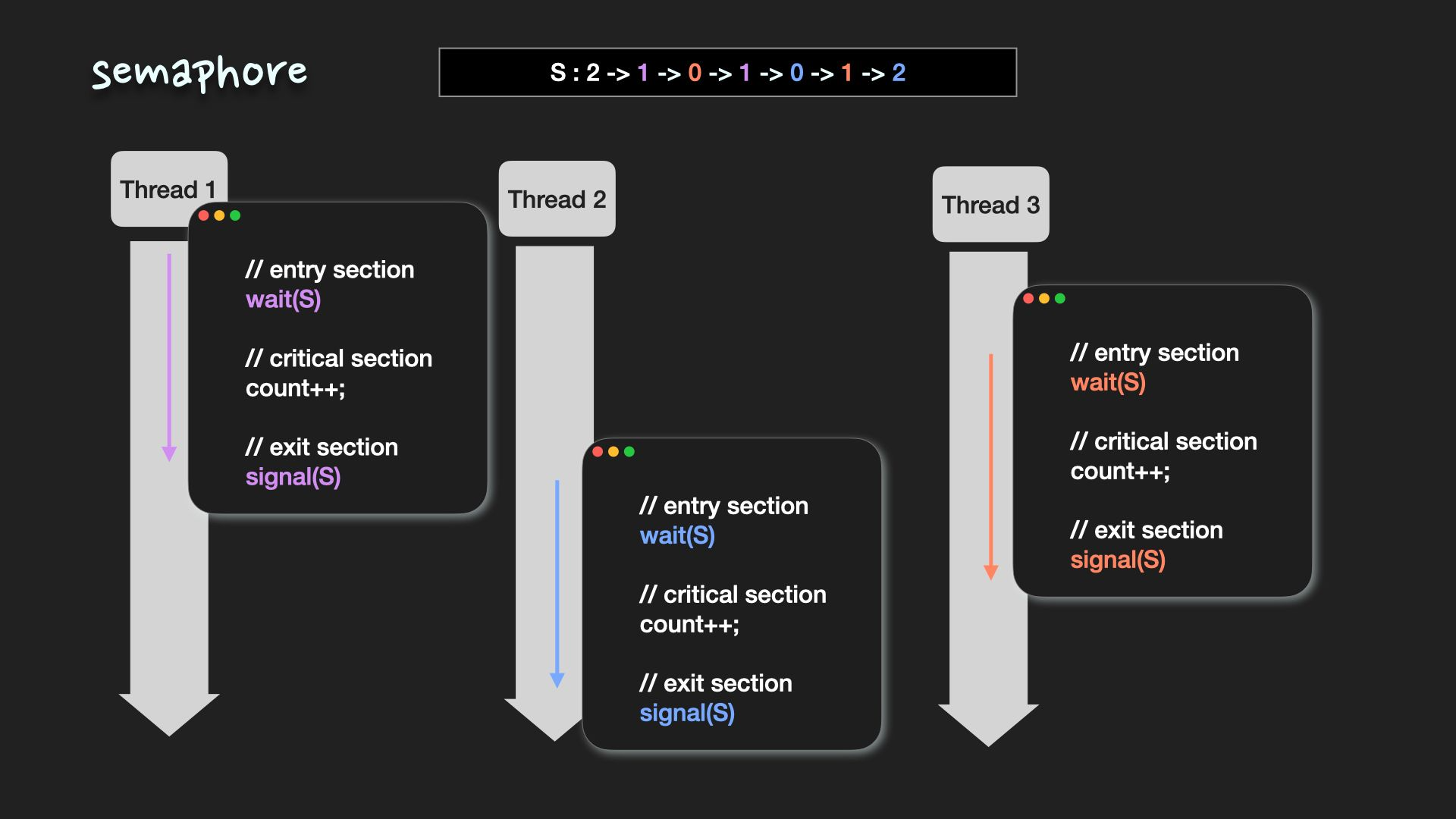
Semaphore
mutex와 가장 큰 차이점은 공유 자원에 접근할 수 있는 process/thread의 개수가 2개 이상이 될 수 있다는 것
semaphore 변수 S(세마포)에 동시에 접근 가능한 process/thread의 개수를 저장, S가 0보다 크면 임계영역으로 들어갈 수 있고, 임계영역에 들어가면 S값을 1 감소
S값이 0이 되면 다른 process/thread는 임계영역으로 접근 불가, 임계영역에서의 작업이 끝나고 임계영역에서 exit하면서 S값을 1증가
wait(S) // entry section
// critical section
signal(S) // exit sectionsemaphore 값이 0,1만 가질 수 있는 경우 binary semaphore라고 하는데, 이는 mutex랑 거의 유사하게 동작