20920번
문제/입력/출력
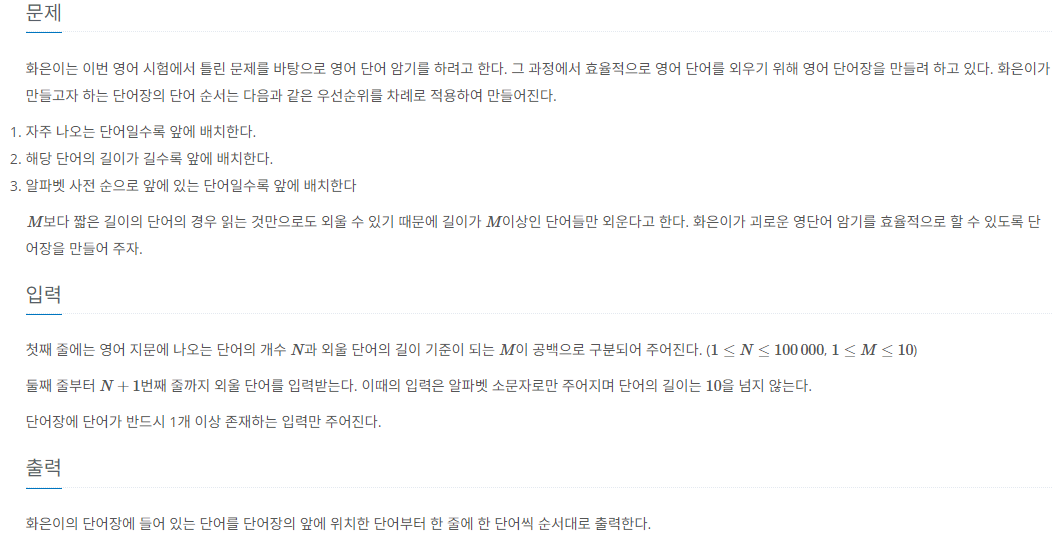
예제 입출력
문제 바로가기
백준 20920번
💡풀이방법
- 접근방법
- 영단어 정렬 조건 정리
- 자주 나온 단어부터
- 긴 단어부터
- 사전순으로
- 공통조건: M보다 짧은 단어는 제외함
- 정리
- 각 단어별로 조건 확인
- 길이가 M 이상인지 확인 후, true라면 단어의 빈도수를 저장
✏️관련 개념
- collections의 Counter
데이터의 빈도수를 계산하고 관리하는데 사용함
리스트의 각 항목이 몇 번 나타나는지를 계산하여 딕셔너리 형태로 저장
data = ['apple', 'orange', 'apple', 'orange', 'banana']
counter = Counter(data)
print(counter)
print(dict(counter))
- 코드 내에서의 Counter
반복을 돌면서 word_count.items()에서 각 (word, count)쌍 순회하며 리스트 요소로 변환
filtered_words = [
(word, count) for word, count in word_count.items()
if (len(word) >= M)
]
print(filtered_words)
- lambda 이용
-x[1]: count값(빈도수)이 큰 것부터(내림차순)
-len(x[0]): word의 길이가 긴 것부터(내림차순)
x[0]: 알파벳 순(오름차순)
filtered_words.sort(key = lambda x: (-x[1], -len(x[0]), x[0]))
💡구현 코드
from collections import Counter
import sys
input = sys.stdin.read()
def word_study(N, M, words):
word_count = Counter(words)
filtered_words = [
(word, count) for word, count in word_count.items()
if (len(word) >= M)
]
filtered_words.sort(key = lambda x: (-x[1], -len(x[0]), x[0]))
for word, _ in filtered_words:
print(word)
data = input.split()
N = int(data[0])
M = int(data[1])
words = data[2:]
word_study(N, M, words)

