1. 자연어 처리 - NLP
자연어란 우리가 일상 생활에서 사용하는 언어
자연어 처리란 이러한 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일
자연어 처리는 음성 인식, 내용 요약, 번역, 사용자의 감성 분석, 텍스트 분류 작업 (스팸 메일 분류, 뉴스 기사 카테고리 분류), 질의 응답 시스템, 챗봇과 같은 곳에서 사용
자연어 처리 과정
- 형태소분석
- 구문분석
- 의미분석
- 담화분석
형태소분석
ex) 과자를 먹는 철수
- 형태소 분석기
과자 (명사)
를 (조사)
먹는 (동사)
철수 (명사)
구문분석
문장의 구성요소를 분해하고, 그들 사이의 위계 관계를 분석해 문장의 구조를 찾아내는 것
보통은 각각의 어절 단위로 나눠 Parsing tree를 이용해 해당하는 tag를 부여해서 분류
의미분석
문장의 뜻을 파악하는 작업이다.
담화분석
문장을 전체 문맥과 연결하여 정확한 의미를 분석하는 작업
2. 웹스크래핑
- Pycharm 활용
beautifulsoup
pip install beautifulsoup4
주로 사용되는 함수 : find(), find_all(), string, get_text(), select()
1. find(name, attrs, recursive=True, text, **kwargs)
ex) soup.find('div', {"class":"my-scope","id"="myid"})
2. find_all(name, attrs, recursive=True,text,limit=None,**kwars)
ex) soup.find_all('div',{"class":"my-scope"},limit=2)
3. select_one(selector)
select(selector)
ex) soup.select_one('div > table > tbody')
4. get_text(separator='',strip=False)
- separator : 구분자 지정
- strip : 공백 제거 유무
ex) soup.select_one('div > table > tbody').get_text(seperator='\n',strip=True)
5. find_parent(name,attrs,**kwargs)
ex) soup.find_parent('div',{"class":"my-scope","id"="myid"})
6. find_parents(name,attrs,**kwargs)
ex) soup.find_parents('div',{"class":"my-scope","id"="myid"})
selenium
pip install selenium
pip install webdriver-manager
명령어
-
브라우저 창 최대화
driver.maximize_window() -
브라우저 닫기
driver.close() -
현재탭 닫기
driver.quit() -
뒤로가기
driver.back() -
앞으로가기
driver.forward()
3. 자연어처리 기초
KoNLPy
한국어 정보처리를 위한 파이썬 패키지
- Konlpy colab 설치
!pip install konlpy- package import
from konlpy.tag import Okt
t = Okt()- 형태소 분석
sentence = '''
칼바람이 매섭게 불며 하루 만에 날씨가 돌변했습니다.
그간 온화했던 날씨를 생각하고 옷차림하시면 감기 걸릴 수 있습니다.
나가기 전에 옷차림을 한 번 더 점검하자는 의미에서 박성신의 '한번만 더'로 날씨톡톡 시작해 보겠습니다.
한파 특보가 전국 대부분 지역으로 확대됐습니다.
'''
print('형태소 :', t.morphs(sentence))- 품사 태깅
print('품사 태깅 결과 : ', t.pos(sentence))- 불용어 처리
stop_words = '날씨'
stop_words = set(stop_words.split(' '))
n_adj = [word for word in n_adj if not word in stop_words]
n_adjNLTK
import nltk
nltk.download("book",quiet=True)
from nltk.book import *
nltk.corpus.gutenberg.filleids()emma_raw = nltk.corpus.gutenberg.raw("austen-emma.txt")
print(emma_raw[:100])sent_tokenize : 문장단위 토큰 생성
from nltk.tokenize import sent_tokenize
print(sent_tokenize(emma_raw))
word_tokenize : 단어단위 토큰 생성
from nltk.tokenize import word_tokenize
word_tokenize(emma_raw[0:100])
RegexpTokenizer : 정규포현식 사용 토큰 생성
from nltk.tokenize import RegexpTokenizer
retokenize = RegexpTokenizer("[\w]+")
retokenize.tokenize(emma_raw[0:100])어간추출
from nltk.stem import PorterStemmer, LancasterStemmer
st1 = PorterStemmer()
st2 = LancasterStemmer()
words = ['working','works','worded']
print('Porter Stemmer :',[st1.stem(w) for w in words])
print('Lancaster Stemmer:',[st2.stem(w) for w in words])
->
Porter Stemmer : ['work', 'work', 'word']
Lancaster Stemmer: ['work', 'work', 'word']원형복원
from nltk.stem import WordNetLemmatizer
lm = WordNetLemmatizer()
[lm.lemmatize(w,pos='v') for w in words]품사출력
from nltk.tag import pos_tag
sentence = 'Emma refused to permit us to obtain the refuse permit'
tagged_list = pos_tag(word_tokenize(sentence))
tagged_list
->
[('Emma', 'NNP'),
('refused', 'VBD'),
('to', 'TO'),
('permit', 'VB'),
('us', 'PRP'),
('to', 'TO'),
('obtain', 'VB'),
('the', 'DT'),
('refuse', 'NN'),
('permit', 'NN')]명사선택
nouns_list = [t[0] for t in tagged_list if t[1] == "NN"]
nouns_list
-> ['refuse', 'permit']토큰 사용 빈도수 그래프
from nltk import Text
import matplotlib.pyplot as plt
emma_raw = nltk.corpus.gutenberg.raw('austen-emma.txt')
text = Text(retokenize.tokenize(emma_raw))
text.plot(20)
plt.show()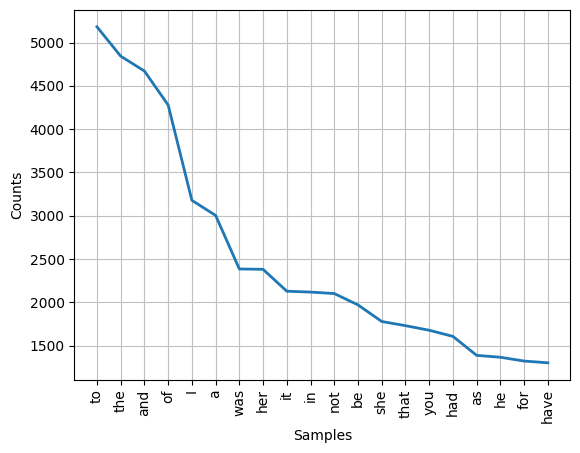
단어의 사용 위치
text.dispersion_plot(['Emma','Knightley','Frank','Jane','Harriet','Robert'])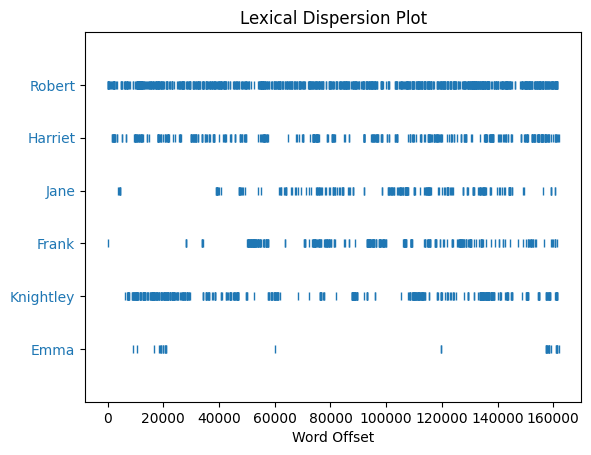
1. 문맥확인
text.concordance('Emma')
2. 문맥에서 주어진 단어대신 사용횟수가 높은 단어
text.similar('Emma')
3. 두 단어 공통 문맥
text.common_contexts(['Emma','she'])
4. 단어의 사용 빈도 정보
Fd = text.vocab()
Fd문맥에서 주어진 단어 대신 사용 횟수가 높은 단어
from nltk import FreqDist
stopwords = ['Mr.','Mrs','Miss','Mr','Mrs','Dear']
emma_tokens = pos_tag(retokenize.tokenize(emma_raw))
names_list = [t[0] for t in emma_tokens if t[1] == 'NNP' and t[0] not in stopwords]
fd_names = FreqDist(names_list)
fd_names.N() #전체 단어수fd_names['Emma'] #엠마 출연횟수
fd_names.freq('Emma') #엠마 출연 확률
fd_names.most_common(5) #출현횟수 상위 5개PyKoSpacing
한국어 띄어쓰기 변환 패키지
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git띄어쓰기 실행
from pykospacing import Spacing
text_data = '나는오늘파이썬을공부하고있습니다'
spacing = Spacing()
spacing_data = spacing(text_data)
print(text_data)
print(spacing_data)
-> 나는오늘파이썬을공부하고있습니다
나는 오늘 파이썬을 공부하고 있습니다colab 실습
https://colab.research.google.com/drive/17CPgMHMy9GWyVZIC2oqF3wjo_vZRzWDF?usp=sharing
