• 프로젝트 생성
목표 : Spring Data JDBC를 사용해 CRUD 기능을 구현.
목적 : Spring Data JDBC 사용법 학습
결론 :
spring data jdbc -- 이게 왜 생겼는가.
jpa - ORM으로 SQL을 안써도 되니까 쓴다.
msa가 아닌 환경에서 JPA 안쓰려면? 쿼리를 써야한다.
jpa - 컬렉션 함수를 쓰는데 좋지않다. 쿼리로하면 컬렉션 함수를 쓸 수 있다.
테이블 조인이 곤란한 상황? -> mybatis 쓰면됨!
jpa -- entity가 테이블이 생성됨.
msa환경 테이블 많아봐야 3~4개 - jpa 사용 가능.
jpa 단점 어려움.
복잡한 요소를 빼고 단반향으로 쓰자 나온 것이 spring data jdbc.
jpa의 복잡한 요소를 다 뺀 것이 Spring Data jdbc이다.
jdbc 방식은 쿼리가 어렵다. 네이티브 쿼리
-- 레파지토리 기반에서 어노테이션으로 쓸 수 있다.
전제 조건이있다
--- msa 환경처럼 table이 적고 쿼리가 적은 환경에서
spring-data-jdbc 쓴다, 조인을 할 거면 API로 한다.
프로젝트 생성
완성 깃허브 소스 코드
crud 기능만 완성
https://github.com/eternityhwan/osc-board-data-jdbc
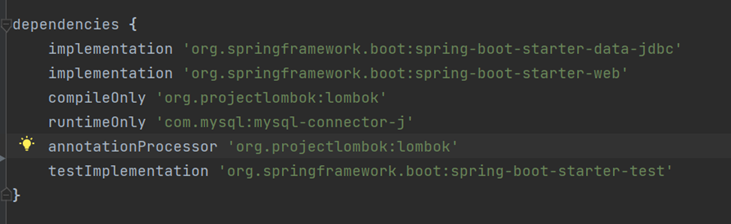
다음 의존성을 사용합니다.
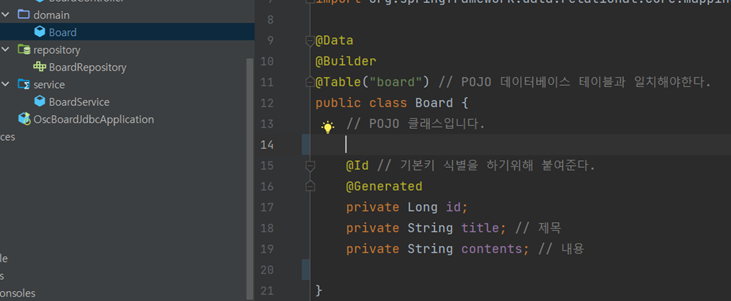
도메인 추가
Entity 어노테이션이 없습니다.
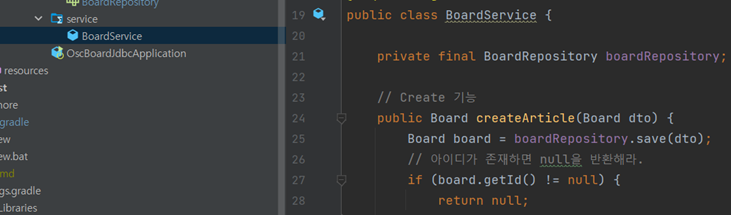
레파지토리 추가
Spring Data 추상화 레파지토리인 CrudRepository를 상속받아 사용합니다.
스프링 데이터 JPA와 동일한 방법입니다.

POJO 클래스 생성.
서비스 추가
엔티티를 만들기 위해서는 POJO(Plain old java object)를 사용해야 합니다.
Spring Data JDBC는 POJO를 데이터베이스 테이블에 매핑할 수 있습니다.
1. 생성된 POJO는 데이터베이스 테이블과 일치해야 합니다.
그렇지 않은 경우 @Table 주석을 사용하여 실제 테이블 이름을 참조하는 데 도움이 됩니다.
2. 기본 키를 식별하려면 @Id 주석이 필요합니다.
3. POJO 및 데이터베이스 테이블 열의 모든 지속성 필드가 일치해야 하는 것이 좋습니다. 그렇지 않으면 @Column 주석이 열 이름을 제공하는 데 도움이 됩니다.
정리
실제로 해보면 Spring-Data-JPA와 Spring-Data-JDBC 의 차이는
양방향 지향과 단반향 지향의 차이 뿐입니다.
레파지토리를 똑같이 EXTENDS 받아 CRUD 하는 것은 같습니다.
