서버 과부화의 의미
서버가 리소스를 소진하여 들어오는 요청을 처리하지 못할 때 발생.
이 때 사용자의 웹요청을 처리하지 못해 응답없을이 뜨게 됩니다.

해결책 1
모니터링을 통한 자원 할당
사실 이러한 서버 과부화로 서버가 응답없음이 뜨는 것은 여러가지 이유가 있지만 그 중에 하나가 바로 "자원의 한계점 도달"입니다. 보통 서버의 cpu 사용량이 80~90%에 도달하거나 메모리가 부족해 계속 스와핑이 발생하면 과부화 상태가 됩니다.
이는 모니터링을 통한 자원의 적절한 할당으로 해결.
자원은 cpu, 메모리, 대역폭도 포함.
128gb가 한계 메모리라 하는데 요청이 너무 많아서 메모리에 한계가 온것.
이러면 메모리를 늘려주면된다, ex) AWS의 autoscaling
AWS는 모니터링 시스템을 지원해준다.
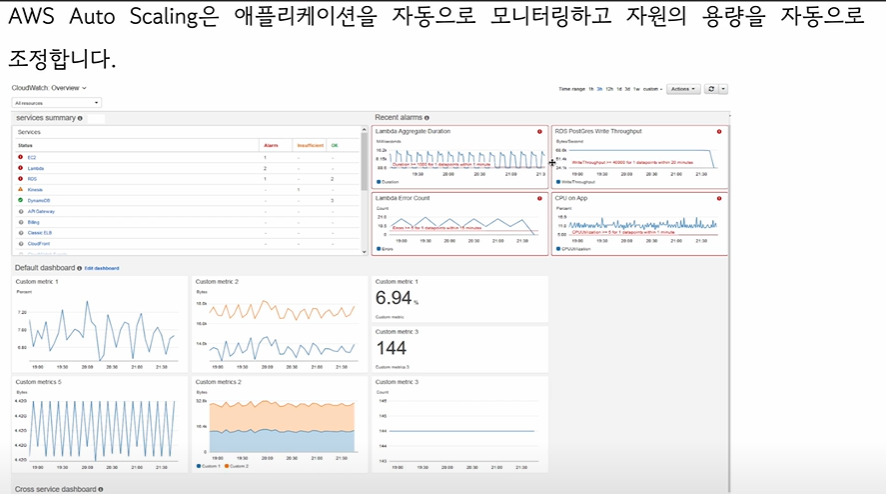
모니터링을 왜 할까?
서버 과부화 방지 때문도 있지만
1. 어떤 페이지에 어떤 트래픽 과다가 발생했느냐
2. 어떤 네트워크에서 병목현상이 일어났느냐.
등을 확인하기위한 기준을 잡기위해 하는 것.
활용도가 낮은 페이지, 높은 페이지를 파악할 수 있다 서비스 개선에도 도움이 된다.
즉 문제점을 파악하고 해결하기위해 모니터링은 필수이다.
A,B,C 중에 B에만 몰린다면 B에만 자원을 할당하면 된다.
아니면 A,C 서비스는 왜 인기가 없는지 파악할 수 있으니까 도움이 많이 되지.
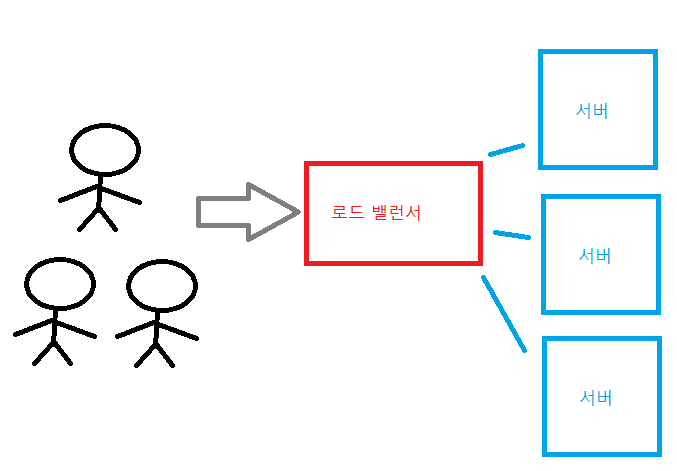
로드밸런서
AWS 오토스케일링은 빠르긴 하나 구성에 시간이 걸리기 때문에 로드밸런서를 통해 트래픽을 분산하는 방법도 있다.
하나의 서버에 몰빵하는게 아니라
분산, 서버에는 오토스테일링을 걸고
필요하다면 로드밸런서에도 오토스케일링을 걸 수도 있다.
블랙스완 프로토콜
예측할 수 없는 사고가 일어난 것을 말한다
사후에는 이 사고의 원인등을 분석할 수 있지만 사전에는 이 사고를 예측할 수 없는 것을 말합니다.
엄청나게 많은 대비를 했지만 서버가 죽을 수 있다.
- 영향을 받는 시스템과 각 시스템에 상대적 위험 수준을 확인.
-- 체계적으로 데이터를 수집하고 원인에 대한 가설을 수립한 후 이를 테스팅 - 잠재적으로 영향을 받을수 있는 내부의 모든 팀에 연락
- 최대한 빨리 취약점에 영향을 받는 모든 시스템을 업데이트
- 복원계획을 포함한 우리의 대응 과정을 파트너와 고객 등 외부에 전달.
