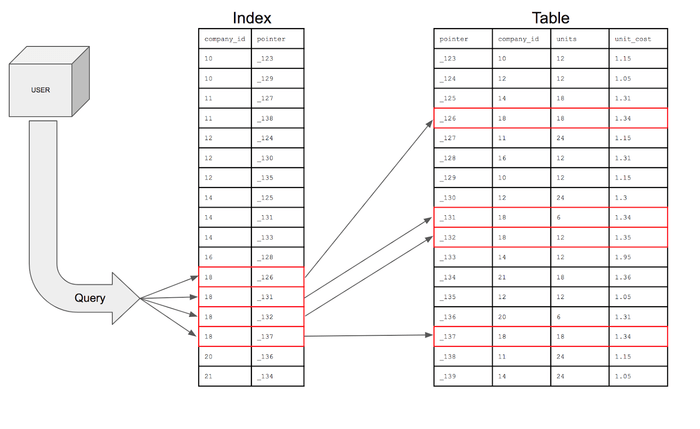
인덱스 (index)란?
데이터베이스 인덱스(index)는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블에 저장된 데이터의 검색 속도를 향상시키기 위한 자료구조이다.
인덱스 == 정렬
지정한 칼럼을 메모리 영역에 목차를 생성하는 것.
인덱스란 데이터의 저장(INSERT, UPDATE, DELETE) 의 성능을 희생하고 그 대신에 데이터의 읽기 속도를 높이는 테이블의 동작속도(조회)를 높여주는 자료구조이다. 즉 테이블의 컬럼들을 기준으로 빨리 접근하기 위한 목차를 생성하는것이다.
Mysql innoDB 스토리지 엔진은 이를 위해 B+ Tree구조를 사용한다.
예를 들어, 책에서 원하는 내용을 찾는다고 가정하면, 책의 모든 페이지를 넘기면서 원하는 내용이 나올 때까지 찾는 것보다 목차 또는 저자가 남긴 색인(index)을 통해 찾는 것이 더욱 빠를 것이다. 데이터베이스의 인덱스가 책의 목차와 색인과 같은 역할을 한다.
이처럼 데이터베이스에서 인덱스를 사용하면, 데이터를 검색할 때 전체 테이블을 스캔하는 것이 아니라, 인덱스를 사용하여 검색 대상 레코드의 범위를 줄일 수 있다. 이는 대량의 데이터를 다루는 경우 데이터 검색 속도를 크게 향상시킨다.
인덱스 장점과 단점
장점
- 검색 대상 레코드의 범위를 줄여 검색 속도를 빠르게 할 수 있다.
- 중복 데이터를 방지하거나 특정 컬럼의 유일성(Unique)을 보장할 수 있다.
- ORDER BY 절과 GROUP BY 절, WHERE 절 등이 사용되는 작업이 더욱 효율적으로 처리된다.
단점
-
인덱스 생성에 따른 추가적인 저장 공간이 필요하다. (인덱스 사용 시 해당 정보를 담은 MYI 파일 생성)
-
CREATE(삽입), DELETE(삭제), UPDATE(수정) 작업 시에도 인덱스를 업데이트해야 하므로 성능 저하가 발생할 수 있다.
한 페이지를 동시에 수정할 수 있는 병행성이 줄어든다. -
인덱스 생성 시간이 오래 걸릴 수 있다.
인덱스는 데이터베이스에서 검색 및 처리하는 속도를 향상시키는 데 중요한 역할을 한다. 하지만, 인덱스를 적절하게 활용하지 않으면 오히려 데이터베이스의 성능이 저하되거나 저장 공간이 낭비될 수 있다.
따라서, 인덱스를 적절히 선택하고 생성하는 것이 중요하다.
인덱스를 사용하는 경우
1. 대량의 데이터를 검색하는 경우
대량의 데이터를 검색해야 하는 경우에는 인덱스를 사용하여 검색 속도를 향상시킬 수 있다. 대량의 데이터를 전체 스캔하는 것은 매우 느리고 부하가 발생하기 때문에 이 경우에 인덱스를 사용하여 검색하는 것이 효율적이다.
2. 정렬된 결과를 출력하는 경우
인덱스를 사용하여 데이터를 정렬하면 매우 빠르게 정렬된 결과를 출력할 수 있다. 따라서 데이터를 정렬하는 경우에는 인덱스를 사용하는 것이 좋다.
3. 조인 연산을 수행하는 경우
조인 연산을 수행하는 경우에는 인덱스를 사용하여 연산 속도를 향상시킬 수 있다. 인덱스를 생성하여 조인 대상 테이블의 데이터를 빠르게 검색하는 것이 좋다.
4. 유니크한 값을 가져오는 경우
인덱스는 유니크한 값을 가지고 있는 필드에 대해 중복되지 않는 값을 빠르게 검색할 수 있다. 이러한 경우 인덱스를 사용하여 검색 속도를 빠르게 할 수 있다.
5. 검색 빈도가 높은 경우
검색 빈도가 높은 필드에 대해서 인덱스를 생성하여 검색 속도를 향상시키는 것이 좋다.
인덱스 생성 사용 쿼리
모두 mysql workbench에서 사용 가능.
고유 인덱스 만들기
용도: 고유 인덱스는 특정 열(또는 열의 조합)에 대해 고유한 값을 가져야 하는 경우 사용됩니다. 일반적으로 기본 키(primary key)를 지원하기 위해 사용됩니다.
특징: 각 행의 인덱스 값은 고유해야 하며, 중복된 값을 허용하지 않습니다.
CREATE UNIQUE INDEX index_name ON table_name(column1, column2, ...);
비고유 인덱스 만들기
용도: 비고유 인덱스는 특정 열(또는 열의 조합)에 대한 빠른 검색을 지원합니다. 고유성이 요구되지 않습니다.
특징: 동일한 인덱스 값이 여러 행에서 나타날 수 있습니다.
CREATE INDEX index_name ON table_name(column1, column2, ...);
FULLTEXT 인덱스 만들기
용도: 풀텍스트 인덱스는 문자열 데이터(텍스트)에서 단어 기반의 검색을 지원합니다. 전체 문장 또는 단어에 대한 검색에 사용됩니다.
특징: 일반적인 문자열 인덱스와는 달리 단어의 일부분을 사용하여 검색할 수 있습니다.
CREATE FULLTEXT INDEX index_name ON table_name(column1, column2, ...);
인덱스의 자료구조
- 해시 테이블(Hash table)
해시 테이블은 키(Key)와 해시 값(Hash Value) 쌍으로 이루어진 자료구조이다. O(1)의 시간복잡도를 가지고 있어 상당히 빠른 검색을 할 수 있는 것이 특징이다.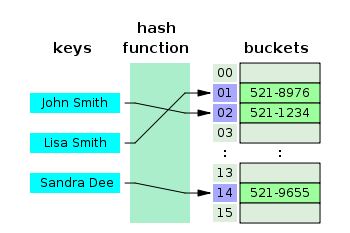
해시 테이블의 검색 방식은 키를 해시 함수를 사용하여 해시 값으로 변환한 후, 해당 해시 값에 해당하는 값을 찾아서 검색한다. 해시 테이블은 검색 속도가 매우 빠르지만, 데이터의 분포에 따라 충돌이 발생할 수 있다. 따라서 충돌을 해결하기 위한 방법이 필요하다.
또한, 해시는 등호(=) 연산에만 특화되어 있어 부등호 연산(>, <)이 자주 사용되는 데이터베이스 검색을 위해서는 해시 테이블이 적합하지 않다.
- B-Tree
B-Tree는 데이터베이스에서 가장 널리 사용되는 인덱스 자료구조 중 하나이다. O(logN)의 시간 복잡도를 가지고 있다. B-Tree는 균형 잡힌 이진 검색 트리로 데이터베이스에서 검색 속도를 높이기 위해 사용된다.
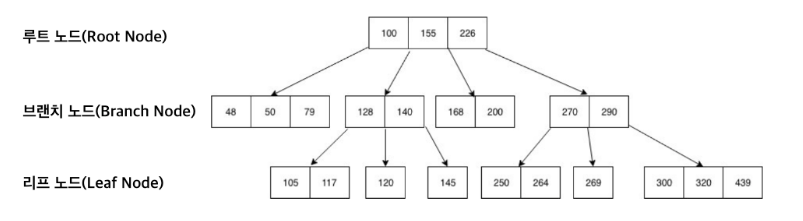
B-Tree의 각 노드 내 데이터들은 항상 정렬된 상태인 것이 특징이며, 데이터와 데이터 사이의 범위를 이용하여 자식 노드를 가진다. (자식 노드의 개수는 n+1개)
또한, 한 노드에서 여러 개의 키를 가질 수 있고, 키에 해당하는 데이터도 함께 갖고 있다.
- B+Tree
B+Tree는 B-Tree의 변형된 구조로 B-Tree와 비슷하지만 몇 가지 차이점을 가지고 있다. B+Tree 또한 균형 잡힌 이진 검색 트리이다. B+Tree는 B-Tree에 비해 더 많은 키를 가질 수 있다.
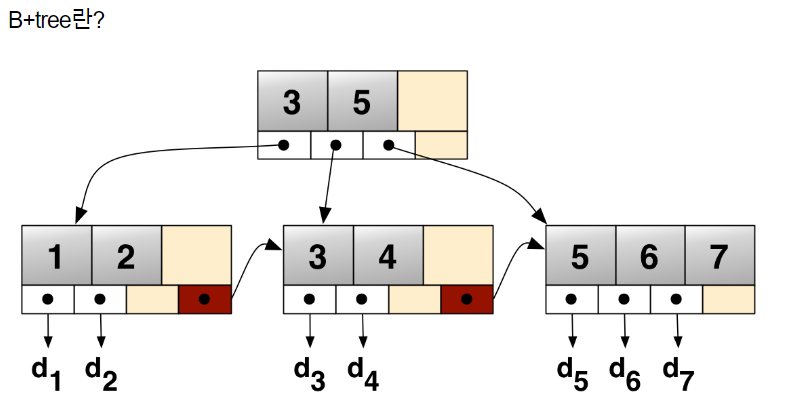
B+Tree는 B-Tree와 달리 내부 노드(Internal node)와 단말 노드(Leaf node)로 구분된다. B+Tree의 모든 데이터는 단말 노드에서만 저장되며, 내부 노드에는 검색을 위한 인덱스만 저장된다.
모든 리프 노드가 연결 리스트로 연결되어 있으며, 순차적으로 저장되어 있다. 이러한 특징으로 인해 범위 검색(Range Search)이나 순차 검색(Sequential Search)에 효율적이다.
