JDBC, Hibernate, JPA, Spring Data JPA 차이
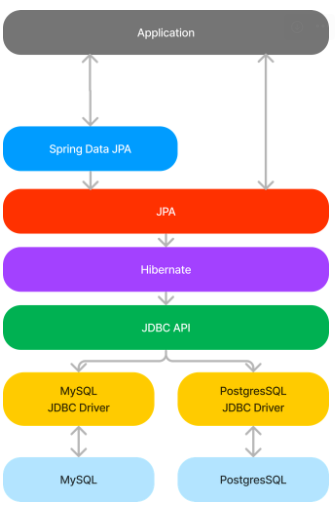
MYSQL이나 postgresSQL을 사용해서 JDBC 데이터 구현체를 만든다.
JDBC API는 하나의 인터페이스이다.
JDBC API만으로도 개발이 되고 Application 통신또한 되고 Repository Layer도 작성할 수 있다.
데이터베이스와 통신할 수도 있지만 이렇게 하는 것은 로우레벨의 인터페이스이다.
이제 여기서 다른 것을 더 얹어서 사용하면 된다.
대표적으로 얹는게 JPA(Java Persistence API)이다.
API가 Application Programming Interface이니까 JPA도 하나의 인터페이스이다.
JDBC의 API를 여러가지 조합해서 좀 더 쉬운 인터페이스를 만든게 JPA이다.
여러가지 조합했기에 구현체도 여러가지 있는데 그 중에서 Hibernate 구현체를 제일 많이 사용한다.
성숙도가 제일 높아서 Hibernate를 주로 JPA의 구현체로서 사용한다.
JPA와 Application이 통신하는 것이 JDBC API랑 Application이 직접 사용하는 것보다 더 쉽게 더 생산성 높게 사용할 수 있다.
이유는 JDBC를 감싸서(JDBC의 API를 여러가지 조합해 디벨롭했기에) 더 쉽게 만든 인터페이스이기 때문이다.
여기서 추가적으로 하나더 추상화 한것이 스프링 진영에서 개발한 Spring Data JPA가 있다.
Spring Data JPA는 Repository라는 인터페이스를 제공한다.
이 인터페이스를 통해서 JPA를 호출한다. => Spring Data JPA를 감싸 디벨롭한 것이기 때문에
Course-registration의 예제에서는 Spring Data JPA를 통해서 데이터베이스와 통신을 하고 필요에 따라서 JPA를 사용한다.
그래서 JPA를 잘 알아야 Spring Data JPA를 잘 사용할 수 있다.
JPA
Java Persistence API의 약자. 결국, 하나의 인터페이스. JDBC API를 내부적으로 사용하면서, SQL을 직접 사용하기 보다 객체지향적으로 데이터베이스를 다룰 수 있도록 하는 역할을 하는 ORM. 테이블과 매핑되는 객체 클래스 자체가 바로 Entity이다. @Entity 를 포함한 몇몇 어노테이션을 지정함으로써 JPA에서 관리하는 객체로 작동하게 한다.
@Entity
@Table(name = "post")
class Post(
@Column(name = "title")
var title: String,
// ... 다른 필드 및 메소드
@OneToMany(mappedBy = "post")
val comments: List<Comment> = mutableListOf(),
@ManyToOne
@JoinColumn(name = "author_id", nullable = false)
val author: User,
) {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) //Application에 위임할 수도 있는데 Supabase에서 BIGSEAL로 자동생성 했기에 여기서 strategy = GenerationType.IDENTITY로 데이터베이스에 위임하는 것이다.
var id: Long? = null
}@Entity어노테이션을 통해 Java 객체로 맵핑을 해주고,@Table어노테이션을 통해 어떤 테이블과 관계가 있는지 세부 속성을 명시해 줍니다.@Table은 생략이 가능하고, 생략할 때 JPA는 엔티티 클래스의 이름을 사용하여 테이블을 자동으로 맵핑합니다.@Id어노테이션을 통해 Entity의 Primary Key를 지정합니다!@GeneratedValue어노테이션을 통해 자동으로 생성되는 식별자를 사용할 수도 있습니다.@Column데이터베이스 컬럼과의 맵핑을 지정합니다.- 다른 엔티티와의 관계를 맵핑합니다.
@ManyToOne,@OneToMany,@OneToOne,@ManyToMany등의 어노테이션을 사용하여 객체간 관계를 설정합니다.
ORM(Object-Relational Mapping)이란?
프로그램 상의 객체와 관계형 데이터베이스 간의 매핑을 담당.
객체를 데이터베이스에 저장하고 조회할 때, 별도의 SQL 쿼리를 작성하지 않아도 되며, 개발자는 객체 지향적인 코드로 데이터베이스를 다룰 수 있습니다. 객체 간의 관계를 바탕으로 SQL을 자동으로 생성해준다.
JPA 의 Persistence Context
영속성 컨텍스트(Persistence Context)라는 개념으로 우리가 JPA @Entity로 정의한 Entity들을 관리를 하기 위한 개념.
데이터가 휘발되는것을 영속성이 없다고 한다. 데이터베이스에 저장하면 영속성이 있다고 한다.
영속성을 부여할 객체(영속성 컨텍스트에 저장할만한 객체)라고 판단하면 데이터베이스로 저장되고 영속성 컨텍스트에 있는 Entity들이 영속성을 부여하지 않아도 된다고 판단하면 데이터베이스에 저장되지 않고 변경되지 않는다.
Transient(New): 새로운 엔티티 생성
Managed: 어떤 오퍼레이션을 통해서 managed상태로 들어간다. 이러면 영속성 컨텍스트에 저장이 된 상태이다.
Detached: 영속성 컨텍스트에 저장이 됐지만 JPA가 판단하기에 '얘는 사실 데이터베이스에 넣을 애가 아니었네'라고 여긴다면 detach(분리)상태로 변환된다.
Removed: Entity 혹은 값들이 삭제된 상태
=> 트랜잭션이 끝났을때 Managed상태와 Removed상태인 것을 구분해 어떤거를 수정하고 추가하고 삭제할지(CUD) JPA가 판단한다.
- 캐싱(Caching)
- 영속성 컨텍스트 내에 Entity를 Map 형태로 임시 저장하여 동일한 Entity를 조회할 시, 데이터베이스를 직접 조회하지 않고 해당 Entity를 사용할 수 있게 한다.
- 트랜잭션(Transaction)을 통한 쓰기 지연
- 우리는 이미
@Transactional어노테이션을 배우며 이 개념을 배웠습니다! 지연로딩과 유사하게 코드 상에서 Entity를 수정하거나 변경한다고 바로 반영하지 않고, Entity의 상태 변경을 통해 SQL 저장소에 쿼리를 저장해둡니다. 최종적으로 트랜잭션이 종료되는 시점, 즉 트랜잭션을 최종commit()하기 이전에 데이터베이스에 모아둔 쿼리를 보내 데이터베이스와 영속성 컨텍스트를 동기화 합니다. 최종적으로commit()이 종료되면, 데이터베이스에 변경이 반영이 됩니다. 이렇게commit()종료 이전에 쿼리를 보내 동기화를 하는것을flush()라고 표현합니다.flush()로 전송된 쿼리는 Rollback이 가능하지만,commit()이 완료되면 트랜잭션이 끝나므로 Rollback 을 할 수 없습니다.
- 우리는 이미
=> 트랜잭션 내에 SQL 저장소가 있는데 이 쿼리들이 모인 저장소를 트랜잭션이 끝났을때 이 쿼리들을 한번에 쭉 데이터베이스에 보낸다. 이렇게 최종적으로 트랜잭션(안에 있는 sql 쿼리들)을 데이터베이스에 반영하는 것을 commit()이라고 한다.
commit() : 최종적으로 데이터베이스에 변경을 반영한다는 뜻.
=> 커밋 종료전에 어떤 쿼리를 보낼지 데이터베이스랑 동기화를 하는 시점을 Flush라고 한다. 이때까지는 단순히 어떤 쿼리를 보낼지 결정하고 동기화하는 단계이기에 전송됐던 쿼리도 롤백이 가능하다. 하지만 커밋이 완료되면 트랜잭션이 끝나므로 롤백이 불가하다.
- Dirty Checking
- 위에서 언급한
flush()는 어떻게 어떤 쿼리를 보내야하는지를 판단할 수 있을까요? Entity의 변경 사항을 추적해서 판단합니다! 이 과정을 Dirty Checking이라 합니다. - 예를들어, 아래처럼 post의 title을 변경했을시에, Dirty Checking을 통해
아, post의 title이 변경되었느니 update 쿼리를 실행해야겠구나!를 판단하는 것입니다.
- 위에서 언급한
val post = em.find(Post::class.java, postId)
println(post.title) // "Title1"
post.title = "New Title2"주의점으로, Dirty Checking은 Entity가 영속성 컨텍스트에 저장된 상태, 즉 Managed 상태에 대해서만 수행됩니다!
JPA의 Entity Manager
영속성 컨텍스트(Persistence Context)를 두어 Entity를 관리하는 주체.
@PersistenceContext 어노테이션을 통해 주입할 수도 있고, 생성자 주입을 했을시에도 자동적으로 주입된다.
EntityManager는 여러 종류의 함수를 지원하여, Entity의 상태를 변경한다.
위에서 본 상태 변경 함수를 이용해서 쿼리나 값을 영속성 컨텍스트에 넣을지 아니면 삭제 상태로 넣을지 지원하는 역할.
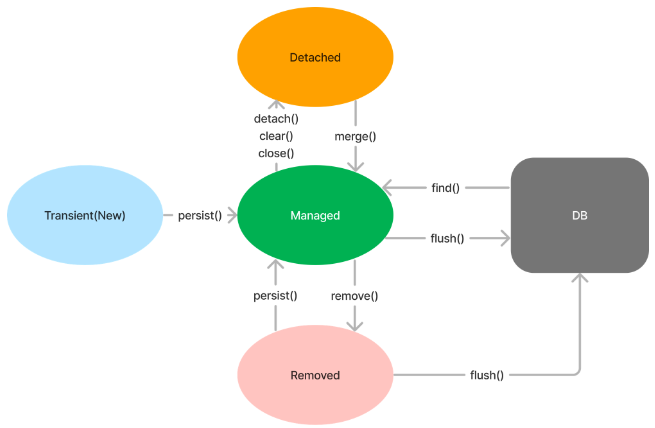
persist(): Entity를 영속성 컨텍스트에 추가합니다.merge(): Detached 상태의 Entity를 다시 영속성 컨텍스트에 추가하여, 변경이 감지되도록 합니다.remove(): Entity를 삭제합니다.detach(): 영속성 컨텍스트에서 Entity를 분리하여 Detached 상태로 만듭니다.clear(): 영속성 컨텍스트를 초기화하여 모든 Entity를 Detached 상태로 만듭니다.close(): EntityManger를 종료합니다.flush(): 영속성 컨텍스트 내에서 변경된 Entity를 감지하여 데이터베이스와 동기화합니다. 최종 반영이 된다.find(): 주어진 Entity의 PK를 이용하여 Entity를 데이터베이스에서 조회하여 영속성 컨텍스트에 추가합니다. SELECT 쿼리가 동작한다.
SQL에서 CRUD를 하는것과 굉장히 유사하다.
Spring Data JPA 의 Repository
EntityManager를 한 단계 더 추상화한 Spring Data JPA의 Repository 인터페이스를 사용.
Spring Data JPA는 아래와 같은 Repository 인터페이스를 제공
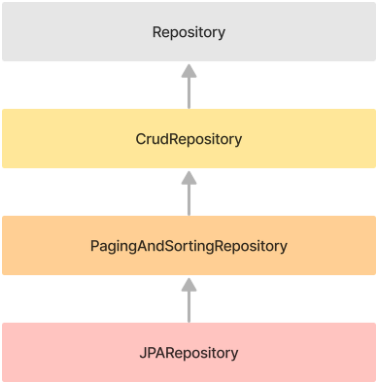
- CrudRepository는 기본적인 데이터베이스 대상 CRUD를 위한 method를 제공합니다.
- PagingAndSortingRepository는 CrudRepository를 상속받아, 기본 CRUD에 더해 페이징 및 정렬 기능을 제공합니다.
- JPARepository는 PagingAndSortingRepository를 상속받아 부가적인 기능을 추가로 제공합니다.
- 우리는 여기서 제일 기능이 많은 JPARepository 인터페이스를 사용할 예정입니다!
interface PostRepository: JpaRepository<Post, Long> {
fun findByTitle(title: String): List<Post>
// SELECT * FROM post WHERE title = argument
}PostRepository : 어떤 Repository인지 네이밍 해주고
JpaRepository 를 상속을 받는다.
JpaRepository<Post, Long> 를 상속 받을때 Post로 어떤 Entity(table)인지 명시해주고 이 엔티티의 PRIMARY KEY 즉 id가 어떤 타입인지 Long으로 명시해준다.
=> 이렇게만 해주면 JPARepository를 편하게 사용할 수 있다.
이렇게 인터페이스를 정의하면, Spring Data JPA는 이 인터페이스의 구현체를 자동으로 생성한다.
Entity간의 관계 설정(일대일, 일대다, 다대다)
package com.teamsparta.courseregistration.domain.course.model
import com.teamsparta.courseregistration.domain.courseapplication.model.CourseApplication
import com.teamsparta.courseregistration.domain.lecture.model.Lecture
import jakarta.persistence.*
@Entity // 데이터베이스와 매핑되는 객체
@Table(name = "course")
class Course (
@Column(name= "title")
var title: String,
@Column(name = "description")
var description: String? = null,
@Enumerated(EnumType.STRING) // 0,1 숫자가 아닌 이름 스트링으로 저장됨
@Column(name = "status")
var status: CourseStatus, // String으로만 명시하면 open, closed말고 다른걸 써서 실수할 수 있으니 enumclass 상수로 지정해 관리.
@Column(name = "max_applicants")
var maxApplicants: Int = 30,
@Column(name = "num_applicants")
var numApplicants: Int = 0,
//Course는 Lecture를 가지고 있다. 일단 단순하게 다 양방향 관계로 설정
@OneToMany(mappedBy = "course", fetch = FetchType.LAZY, cascade = [CascadeType.ALL], orphanRemoval = true) // FK를 누가 가지고 있는지 양방향 관계일 때 연관관계가 아닌 쪽에 mappedBy에 명시. course는 1:N 중 1에만 mappedBy 표기. 1은 FK가 없고 PK만 가지고 있으니까.
// cascade는 부모에만 설정. 부모가 저장하면 하위애들도 저장되고 삭제되면 삭제되니까. 코틀린에서 무조건 Array 형태로 사용. [] 안 감싸면 오류남
// 보통 현업에서 LAZY 지연관계를 많이 쓴다. 불필요한 쿼리를 하지않고 성능향상을 위해서 주로 사용. 근데 만약에 Course랑 Lecture가 항상 붙어다녀 같이 조회된다면 굳이 지연로딩을 해서 필요할 때만 조회할 필요가 없다면 EAGER로 변경.
val lectures: MutableList<Lecture> = mutableListOf(), // Lecture 데이터가 변할 수 있으니 뮤터블 리스트로 설정
@OneToMany(mappedBy = "course", fetch = FetchType.LAZY, cascade = [CascadeType.ALL], orphanRemoval = true)
val courseApplications: MutableList<CourseApplication> = mutableListOf()
) {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 데이터베이스에 위임해서 아이디를 자동 생성
var id: Long? = null // PRIMARY KEY인 id를 nullable 하게 두면 안되지만 데이터베이스에 위임하기 위해서 null값 허용한 것.
// 연결된 데이터베이스에 갔다와야 Entity의 id가 생기기 때문에 nullable 하게 설정한 것
}package com.teamsparta.courseregistration.domain.courseapplication.model
import com.teamsparta.courseregistration.domain.course.model.Course
import jakarta.persistence.*
import org.apache.catalina.User
@Entity
@Table(name = "course_application")
class CourseApplication(
@Enumerated(EnumType.STRING)
@Column(name = "status")
var status: CourseApplicationStatus,
// N인 모델에 1인 모델을 쓰는 것임
@ManyToOne
@JoinColumn(name = "course_id")
val course: Course,
// N인 모델에 1인 모델을 쓰는 것임
@ManyToOne
@JoinColumn(name = "user_id")
val user: User, // 이렇게 val userId: Long 이런 식으로 해도 됨. 객체가 객체를 들고 있다보면 너무 강한 결합이 되어 소프트웨어 유지보수가 힘듦. 각각의 Aggregate가 독립적으로 발전해야될 때 id를 이용해 조회하게 해서 결합을 약하게 만듦.
) {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null
}- 우리는 EntityManager의 다양한
persist(),merge()와 같은 기능을 통해, Entity가 영속성 컨텍스트에서 들어가거나 분리되는 등의 상태 변경이 일어난다는 것을 배웠습니다. - Entity 간의 연관 관계를 지정할 때, 설정을 통해 영속성 상태가 변경될때 이를 관계가 있는 다른 Entity에 전파할 수 있습니다. 이를 보통 Cascade라 칭합니다. DDL에서도 외래키를 지정할때 이러한 CASCADE 옵션을 줄 수 있는데, 이와 비슷합니다. 단지 Application 레벨에서 이를 관리하는 점이 다릅니다.
- Cascade의 경우, 부모 자식 관계에서 부모 Entity의 영속성을 전파할 때 쓰입니다.
Course와 Lecture입장에서, 우리는 Course가 삭제되면 하위의 Lecture도 모두 삭제된다는 Policy를 설정하였으므로, Course를 삭제할 때 Lecture도 모두 삭제해줘야 합니다. 하지만, Cascade를 통해 영속성을 전파한다면, 직접 삭제를 할 필요없이 JPA가 이 역할을 모두 대신해줍니다. - 주요한 CASCADE 옵션은 아래와 같습니다.
- CascadeType.ALL
- 모든 변경 작업(저장, 삭제, 갱신)을 전파합니다. 자식 Entity가 부모 Entity의 생명주기를 따라갑니다.
- CasecadeType.Persist
- 저장 작업을 전파합니다. 즉, 부모 Entity를 저장할 때 자식 Entity도 함께 저장됩니다.
- CasecadeType.Merge
- 병합 작업을 전파합니다. 즉, 부모 Entity를 병합할 때 자식 Entity도 함께 병합됩니다.
- CascadeType.REMOVE
- 삭제 작업을 전파합니다. 부모 Entity를 삭제할 때 자식 Entity도 함께 삭제됩니다.
- CascadeType.REFRESH
- 부모 Entity를 새로고침 할 때 자식 Entity도 함께 새로고침 됩니다.
- CascadeType.DETACH
- 부모 Entity가 detach 될 때 자식 Entity도 Detached 상태가 되어 변경 사항 반영을 하지 않습니다.
- CascadeType.ALL
- 실무에서는 주로, CascadeType.ALL, CasecadeType.Persist 를 많이 사용
고아 자식 객체 자동 삭제하기
- Cascade는 자식 객체에 영속성을 어떻게 전파할 것 인지의 옵션입니다.
- Casecade를 ALL 로 설정하고, 아래와 같은 코드를 작성하면 삭제되는 Lecture는 어떻게 될까요?
두개가 같은 뜻
val course = em.find(Course::class.java, 1L)
course.lectures.removeFirst()
em.flush()CasecadeType.ALL에는 CascadeType.REMOVE가 존재하니, 해당 Lecture 데이터는 DB에서 삭제가 될까요? 아닙니다.아래와 같은 SQL문이 실행됩니다.
UPDATE lecture SET course_id = NULL WHERE course_id = 1;- JPA는 이를 단지 관계가 끊어진 걸로 보기에, 삭제는 일어나지 않습니다. 그런데, 이래도 괜찮을까요? course가 지정되지 않은 lecture가 생겼어요. 이는, 우리의 Policy를 위반합니다. 즉, 데이터의 무결성을 해친다고 할 수 있습니다.
- 이렇게 관계가 끊어졌을 때, 자식을 ‘고아 상태’ 라고 표현할 수 있는데요, 이런 고아 상태의 자식을 제거할 수 있는 옵션이 있습니다. 바로
orphanRemoval입니다. 아래처럼@OneToMany어노테이션에 설정을 하면, 관계가 끊어졌을시 JPA가 자동으로 자식 데이터를 삭제해 줍니다. 즉, DELETE 문이 호출됩니다!
@OneToMany(mappedBy = "course", cascade = [CascadeType.ALL], orphanRemoval=true)
var lectures: MutableList<Lecture> = mutableListOf()orphanRemoval 로 관계가 끊어지면 고아 자식 객체를 자동으로 삭제해달라는 옵션.
orphanRemoval=true를 설정하면 DELETE문이 실행된다.
CascadeType.REMOVE 랑은 다르다. CascadeType.ALL 안에 REMOVE가 포함돼있는 것.
CascadeType.ALL = JPA가 단순히 연관관계가 끊어졌다고 보는 것이니까 삭제되지 않은 것.
CascadeType.REMOVE = 부모 모델이 삭제되면 연관된 하위 모델 모두가 삭제된다.

아이디 기반으로 하나의 객체를 얻어오는 것. entity 객체 즉, 한 row를 얻어오는 것.
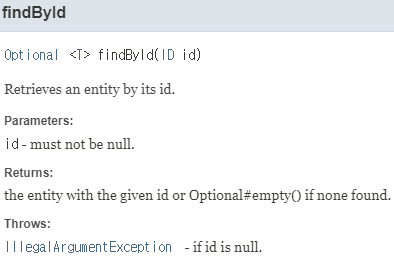
자바보다 조금 더 진화한 코틀린은 findByIdOrNull 함수를 주로 사용할 것이다.
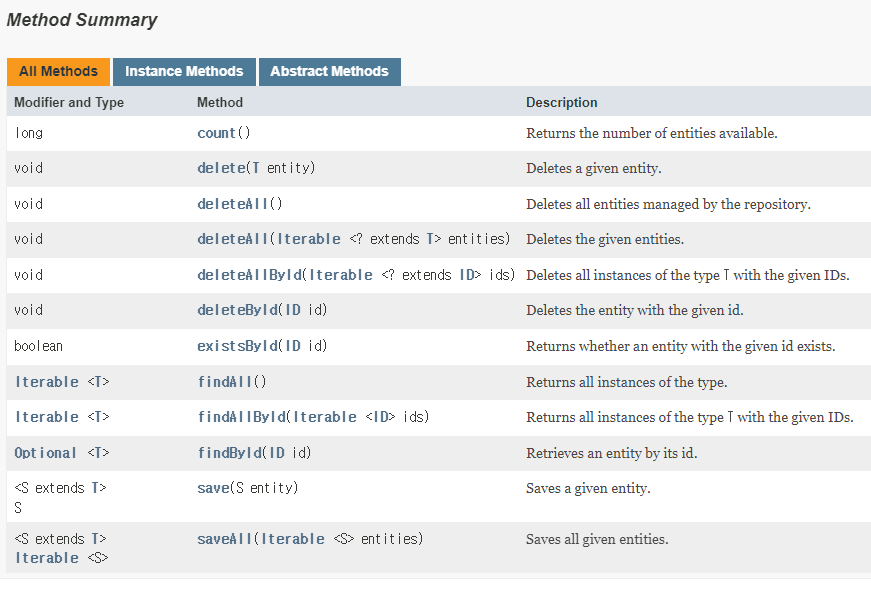
사용할 메소드 모음:
확장함수로 findByIdOrNull을 정의
fun <T, ID> CrudRepository<T, ID>.findByIdOrNull(id: ID): T? = findByIdOrNull(id!!).orElse(null)먼저 id를 넘겨줄 때 이 id는 null이 아니라는 것을 (id!!) 느낌표 두개로 표기하고 만약 .orElse(값이 실제로 없다) id가 없으면 T? 객체 T 자체를 리턴하거나 null을 리턴한다.
