
논문 링크 : PIRLNav: Pretraining with Imitation and RL Finetuning for OBJECTNAV
저자 : Ram Ramrakhya, Dhruv Batra, Erik Wijmans, Abhishek Das
제출일 : 2023년 1월 18일
핵심 키워드 : PIRLNav(Pretraining with Imitation and RL Finetuning for OBJECTNAV), ObjectGoal Navigation(OBJECTNAV), Imitation learning, Behavior cloning, Reinforcement learning, Human demonstrations, Shortest paths(SP), Frontier exploration(FE), HM3D-Semantics
PIRLNav: Pretraining with Imitation and RL Finetuning for OBJECTNAV
- 이 논문은 ObjectGoal Navigation(OBJECTNAV) task를 효과적으로 수행하기 위한 PIRLNav라는 학습 방식을 제안한다
- OBJECTNAV는 가상 로봇이 새로운 환경에서 특정 객체를 찾아 이동하는 task이다. 기존 연구에서는 Imitation Learning의 한 종류인 행동 복제(Behavior Cloning, BC)를 통해 좋은 결과를 얻었지만, 학습 데이터에 없는 상태(out-of-distribution states)에 대한 일반화 능력이 떨어지고, human demonstrations 데이터를 수집하는 데 비용이 많이 든다는 한계가 존재하는 반면, 강화 학습은 확장성이 뛰어나지만, 바람직한 행동을 유도하기 위해 정교한 보상 함수 설계(reward engineering)가 필요하다는 단점이 있다
- 이 논문(PIRLNav)은 이러한 한계를 극복하기 위해 BC 사전 학습(pretraining)과 RL 미세 조정(finetuning)을 결합한 2단계 학습 방식을 제안한다. 이 방식은 OBJECTNAV에서 기존 최고 성능(60.0% 성공률) 대비 5.0%p 향상된 65.0%의 성공률을 달성했다
기존 방식의 한계
- OBJECTNAV는 언어 명령의 객체 토큰을 환경 내의 물리적 객체에 grounding하고 탐색을 돕는 사전지식을 활용하며, 탐색 이력을 내부 메모리에 기록하여 중복 탐색을 피하는 등 여러 복합적인 인지 능력을 요구한다
- 기존 연구 방향
- 모방 학습(Imitation Learning, IL) : 특히 Behavior Cloning(BC)은 human demonstrations 데이터셋을 활용하여 좋은 결과를 보여준다. 그러나 BC는 훈련 시 보지 못한 새로운 상태에 대한 일반화 능력이 떨어지고(행동 자체를 모방하며 결과는 고려하지 않음), human demonstrations 데이터의 수집 비용이 매우 비싸다
- 강화 학습(Reinforcement Learning, RL) : RL은 일단 3D 스캔 데이터가 확보되면 확장성 측면에서 유리하지만, 바람직한 행동을 유도하기 위한 신중한 보상 설계(reward engineering)가 필요하며, 기존 RL 정책은 제한된 수의 환경에 과적합되는 경향이 있다. 특히 OBJECTNAV처럼 탐색이 필수적인 task에서 일반적인 보상 함수는 오히려 탐색에 페널티를 줄 수도 있음
- 모방 학습(Imitation Learning, IL) : 특히 Behavior Cloning(BC)은 human demonstrations 데이터셋을 활용하여 좋은 결과를 보여준다. 그러나 BC는 훈련 시 보지 못한 새로운 상태에 대한 일반화 능력이 떨어지고(행동 자체를 모방하며 결과는 고려하지 않음), human demonstrations 데이터의 수집 비용이 매우 비싸다
- 즉, 실제 ObjectNav 과제는 단순한 navigation task가 아닌 종합 과제라 RL·IL 단독 접근만으로는 한계가 뚜렷하다. 특히 로보틱스 실환경에서 보면, 센서 노이즈나 지도화 불완전성 때문에 RL의 reward engineering의 난이도가 더 커진다. 따라서 이 논문은 hybrid로 접근하였다
핵심 기술 및 아이디어
- PIRLNav의 아이디어는 BC로 미리 학습된 정책이 RL 훈련의 좋은 reasonable starting point을 제공하여, 처음부터 학습하는 것보다 최적화를 쉽게 만든다. 특히, 이는 일반적으로 학습하기 어려운 Sparse Reward 환경에서도 RL을 가능하게 한다
- Sparse Reward는 보상 엔지니어링이 필요 없고 의도치 않은 결과가 적다는 장점이 있지만, 초기 무작위 탐색으로는 긍정적인 보상을 거의 얻을 수 없어 순수 RL로는 학습하기 어렵다
- Sparse Reward는 보상 엔지니어링이 필요 없고 의도치 않은 결과가 적다는 장점이 있지만, 초기 무작위 탐색으로는 긍정적인 보상을 거의 얻을 수 없어 순수 RL로는 학습하기 어렵다
- 하지만 IL과 RL을 결합할때 문제가 있는데, BC는 정책()의 가중치만 학습시키며, Actor-Critic 기반의 RL 알고리즘에 필수적인 가치 함수(value function, 또는 critic)는 학습하지 않는다. 따라서 BC 사전 학습된 정책의 가중치로 actor를 초기화하고, critic을 무작위로 초기화하여 바로 RL을 시작하면, 초기 critic의 부정확한 가치 추정 때문에 actor의 학습이 불안정해지고 성능이 급격히 저하되는 문제가 발생할 수 있다.
- 이 논문은 이러한 문제를 해결하기 위해 2단계 학습 방법론을 제안했다
- Sparse reward 환경에서 강화 학습이 어려운 주된 이유는 에이전트가 학습에 필요한 유의미한 피드백을 거의 받지 못하기 때문이다. PIRLNav 논문에서도 이 점을 언급하며, 초기부터 sparse reward로만 학습을 시작하는 것이 "typically out of reach"라고 설명한다
- 특히, ObjectGoal Navigation과 같은 많은 실제 문제들은 목표 달성까지 여러 단계의 행동이 필요한 "긴 시간 스케일(long horizon)" Task이기 때문에, Sparse reward는 에이전트가 성공적인 결과에 기여한 초기 행동들을 식별하기 어렵게 만드는 "Credit Assignment Problem"을 심화시킨다. 즉, 보상이 주어졌을 때, 어떤 과거 행동들이 이 보상을 얻는 데 결정적이었는지 알기 힘들다
Phase 1 : Critic Learning
- BC로 사전 학습된 정책()의 가중치로 Actor를 초기화하고, 이 Actor는 고정(frozen)시킨다
- 고정된 BC 정책을 사용하여 rollout을 수행하며 궤적(trajectory)을 수집하고, 이 데이터를 바탕으로 Critic만을 학습한다. 이때 행동은 BC 정책에서 확률적으로 샘플링()하여 RL 훈련과의 일관성을 유지한다
- 학습의 안정성을 위해 critic의 최종 선형 레이어 가중치는 0에 가깝게 초기화한다. 이 단계는 critic의 손실(loss)이 평탄해질 때까지 진행한다
Phase 2: Interactive Learning
- Critic 학습이 완료된 후, Actor의 Recurrent Neural Network(RNN) 부분(CNN과 non-visual observation embedding layers는 여전히 고정)과 Critic의 가중치를 모두 unfreeze하고 학습을 진행한다 (Actor와 critic의 가중치를 모두 미세 조정)
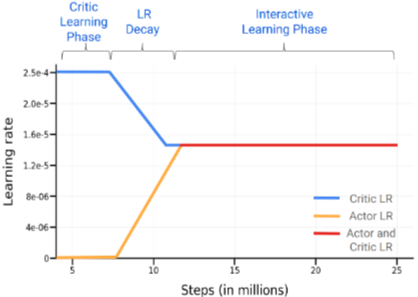
- 이 단계에서는 학습률 스케줄(learning rate schedule)이 중요하다. Critic의 학습률은 2.5 에서 1.5 로 점진적으로 감소시키고, Actor의 학습률은 0에서 1.5 로 점진적으로 증가시키는 warmup을 적용하고(8M에서 12M 스텝 사이), 이후 두 학습률을 1.5 로 유지한다
- RL 알고리즘으로는 DD-PPO를 사용
- 목적함수 :
- : 현재 정책과 이전 정책에서의 액션 확률 비율
- : advantage estimate
- : 현재 정책과 이전 정책에서의 액션 확률 비율
- 목적함수 :
PIRLNav 방법론 요약
- 먼저 IL로 사전 학습된 정책으로 정책 네트워크의 가중치를 초기화하고, critic 가중치를 0에 가깝게 초기화 > actor와 공유 가중치를 고정 (학습 가능한 파라미터는 critic에만 있음)
- 다음으로 사전 학습된 고정 정책에서 수집된 rollout에 대해 critic 가중치를 학습
- critic을 학습한 후 정책 학습률을 높이고 critic 학습률을 낮춤.
- critic과 정책 학습률이 모두 고정 학습률에 도달하면 정책이 수렴될 때까지 학습
Critic-only pretraining 전략은 사실상 “actor-free rollouts”를 통해 value function을 안정화시키는 과정이다. 이는 RL-Games 같은 최신 프레임워크에서 사용하는 “critic warm-up”과 유사하다. 이 논문은 이를 명시적으로 분리하여, 재현성과 안정성을 보여주었다
사실 이 논문에서 제시한 방법 외에도 Sparse reward 문제 해결할 수 있는 방법이 있다고 생각하는데, 이 논문에서는 Sparse reward 문제 해결을 위해 복잡한 reward engineering이나 대규모 데이터 및 RNN을 다루기 힘든 IRL/Off-policy RL 기법들을 채택하기보다는, Human Demonstrations를 활용한 Behavior Cloning Pretraining이라는 상대적으로 단순하면서도 효과적인 방법을 생각했다. 이 방법은 RL finetuning이 sparse reward 환경에서도 충분한 초기 정책을 사용해서 다른 기법들이 가진 이슈들을 회피하고 높은 성능을 달성하는 데 초점을 맞춘 것 같다
결론
PIRLNav는 Behavior Cloning을 통한 사전 학습과 Reinforcement Learning 파인튜닝을 성공적으로 결합한 OBJECTNAV 접근 방식이며, 77,000개의 인간 시연 데이터로 BC 사전 학습을 진행하고 RL로 파인튜닝하여 65.0%의 성공률을 달성, 이전 SOTA를 5% 향상시켰다. 또한, human demonstrations 데이터가 SP또는 FE보다 RL fine-tuning의 일반화에 더 유리하며, BC 사전 학습 데이터셋 크기가 커질수록 RL fine-tuning을 통한 성능 개선 폭이 감소한다는 점을 경험적으로 확인했다. 마지막으로 실패 모드 분석을 통해 데이터셋 어노테이션 문제, 층간 이동, 그리고 목표 객체 인식이 주요 개선점임을 확인하였다
용어정리
- SP (Shortest Paths, 최단 경로)
- 에이전트의 시작 위치에서 가장 가까운 목표 객체 인스턴스까지의 최단경로(Shortest Paths)를 따라 행동을 탐욕적으로 샘플링하여 자동 생성된 데모를 의미
- 환경의 실제 맵 정보(ground-truth map)에 접근하여 계산되므로, 탐색 과정은 포함하지 않고 가장 효율적인 방식으로 OBJECTNAV 작업을 진행
- 에이전트의 시작 위치에서 가장 가까운 목표 객체 인스턴스까지의 최단경로(Shortest Paths)를 따라 행동을 탐욕적으로 샘플링하여 자동 생성된 데모를 의미
- FE (Frontier Exploration, 프론티어 탐색)
- FE(Frontier Exploration)은 두 단계 접근 방식으로 생성된 데모를 의미
- 1단계 (탐색) : 환경의 탐색 범위를 최대화하고 위에서 아래로 보는(top-down) 의미론적 맵을 구축하기 위해 작업에 구애받지 않는(task-agnostic) 전략 사용
- 2단계 (목표 탐색) : 의미론적 예측기(semantic predictor)가 목표 객체를 감지하면, 개발된 맵을 사용하여 최단 경로를 따라 목표에 도달함
- OBJECTNAV 작업 자체에 특화되지 않은 일반적인 탐색 전략을 반영함
- FE(Frontier Exploration)은 두 단계 접근 방식으로 생성된 데모를 의미
- VAL (Validation Split, 검증 세트)
- sparse rewards (희소 보상) ←→ dense rewards(밀집 보상)
- Sparse rewards는 에이전트가 특정 목표를 달성했을 때만 보상이 주어지고, 그 외의 대부분의 상황에서는 보상이 0인 형태
- ex) ObjectGoal Navigation(OBJECTNAV) 작업에서 에이전트가 목표 객체를 찾고 정지했을 때만 긍정적인 보상을 받고, 이동하는 동안에는 보상이 없는 경우
- ex) ObjectGoal Navigation(OBJECTNAV) 작업에서 에이전트가 목표 객체를 찾고 정지했을 때만 긍정적인 보상을 받고, 이동하는 동안에는 보상이 없는 경우
- reward engineering(보상 설계)이 단순함. 보상 함수를 복잡하게 설계할 필요 없이, 단순히 성공 시 보상을 주는 방식으로 구현
- 복잡한 dense rewards(밀집 보상)는 때때로 에이전트가 원래 의도와 다른 방식으로 보상을 최대화하도록 학습하게 만들 수도 있음
- Sparse rewards는 에이전트가 특정 목표를 달성했을 때만 보상이 주어지고, 그 외의 대부분의 상황에서는 보상이 0인 형태
- on-policy RL ←→ off-policy RL
- 에이전트가 환경과 상호작용하여 데이터를 수집하는 데 사용하는 정책과 학습하여 개선하려는 정책이 동일하다는 것을 의미
- on-policy RL에서는 현재 학습하고 있는 정책()이 직접 환경과 상호작용하여 경험 데이터(상태, 행동, 보상 등)를 수집하고, 이 데이터를 사용하여 바로 그 정책()을 업데이트하고 개선함
- 정책이 개선됨에 따라 데이터 수집 방식도 계속 변하기 때문에, 학습 과정에서 충분한 탐색을 통해 다양한 경험을 얻는 것이 중요
- ex) 본 논문에서 사용된 PPO(Proximal Policy Optimization)나 A2C(Advantage Actor-Critic)와 같은 알고리즘이 대표적인 on-policy RL 방식임
- ex) 본 논문에서 사용된 PPO(Proximal Policy Optimization)나 A2C(Advantage Actor-Critic)와 같은 알고리즘이 대표적인 on-policy RL 방식임
- 정책이 업데이트될 때마다 새로운 데이터를 수집해야 하므로, 과거에 수집된 데이터는 현재 정책을 평가하거나 개선하는 데 직접 사용하기 어려워 샘플 효율성(sample efficiency)이 비교적 낮음
- 에이전트가 환경과 상호작용하여 데이터를 수집하는 데 사용하는 정책과 학습하여 개선하려는 정책이 동일하다는 것을 의미
- inflection weighting
- Behavior cloning(BC) 훈련 시 손실 함(loss function)를 조정하는 데 사용되는 기법
- 이 기법의 주요 목적은 에이전트의 행동이 변화하는 시점(timesteps where actions change)에 더 높은 가중치(upweight)를 부여하여 손실 함수를 조절하는 것. 즉, 이전 행동()과 현재 행동()이 다를 때() 해당 시점의 손실에 더 큰 중요성을 부여함
- Behavior cloning은 전문가의 Human demonstrations를 모방하여 정책을 학습함. 이때, 전문가가 긴 시간 동안 동일한 행동을 반복하다가 특정 시점에 행동을 바꾸는 경우가 있을 수도 있는데, 단순히 모든 시점에 동일한 가중치를 부여하면 행동이 바뀌는 중요한 전환점들이 긴 동일 행동 시퀀스에 묻혀서 학습이 제대로 되지 않을 수 있음
- inflection weighting을 사용하면 정책이 행동 변화에 더 민감하게 반응하고, 중요한 결정 지점을 더 잘 학습할 수 있음. 이는 특히 ObjectGoal Navigation과 같이 복잡한 환경에서 에이전트가 새로운 상황에 더 잘 일반화하고, 행동 전환을 정확하게 모방하는 데 기여함
- 논문에서 언급된 Behavior cloning의 최적 파라미터를 찾는 목적 함수
- : 최적의 정책 파라미터
- : 손실 함수를 최소화하는 파라미터
- N : Human demonstrations 데이터셋에 포함된 전체 데모 궤적의 수
- : i 번째 데모 궤적
- : t 시점의 관측()과 행동() 쌍
- : 파라미터 를 가진 Behavior cloning 정책이 관측()에서 행동()를 선택할 확률
- : 행동 에 대한 정책의 음의 로그 확률로, 전문가 행동을 얼마나 잘 예측하는지에 대한 손실. 이 값이 작을수록 예측이 정확함
- inflection weighting은 이 손실 함수에 행동이 변화하는 시점에 더 큰 가중치를 곱하는 방식으로 적용되어, 해당 시점의 손실이 전체 합계에 더 큰 영향을 미침
- Behavior cloning(BC) 훈련 시 손실 함(loss function)를 조정하는 데 사용되는 기법
참고자료
PIRLNav기반 학습 모델 GitHub (직접 구현)
Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale
- 이 논문의 저자 중 일부가 참여한 직전 연구로, 대규모 인간 데모를 이용한 행동 복제(BC)만으로 ObjectGoal Navigation에서 SOTA를 달성했지만, PIRLNav 논문에서는 이 연구의 한계(BC의 일반화 문제, 데모 수집 비용)를 해결하려고 하였다
