
VPC
VPC 생성
IP 대역을 10.0.0.0/16으로 설정하여 VPC를 아래 그림과 같이 구축한다.
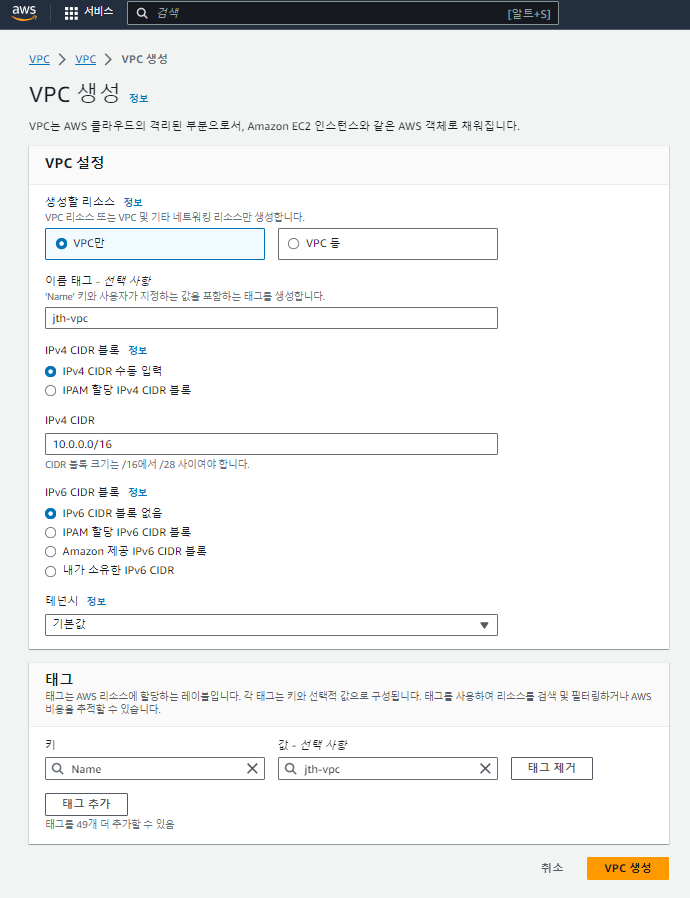
서브넷 생성
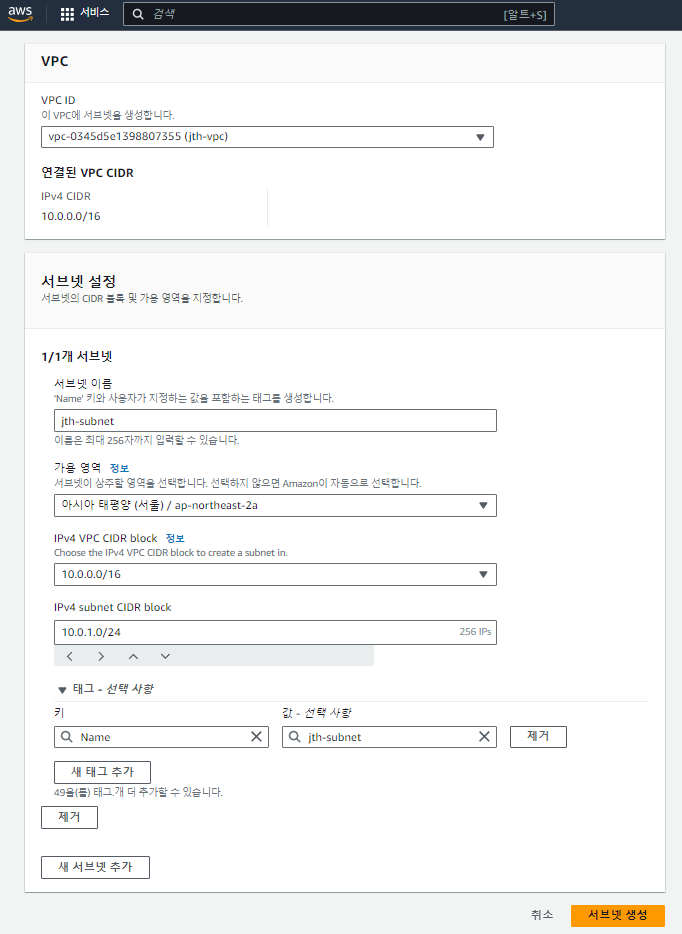
이전에 만든 VPC를 선택하고 의미 있는 이름으로 서브넷을 설정한다.
CIDR은 10.0.1.0/24로 하며, 서브넷을 이어서 만들 경우 10.0.2.0/24,
10.0.3.0/24 ... 이렇게 설정해주어야 한다.
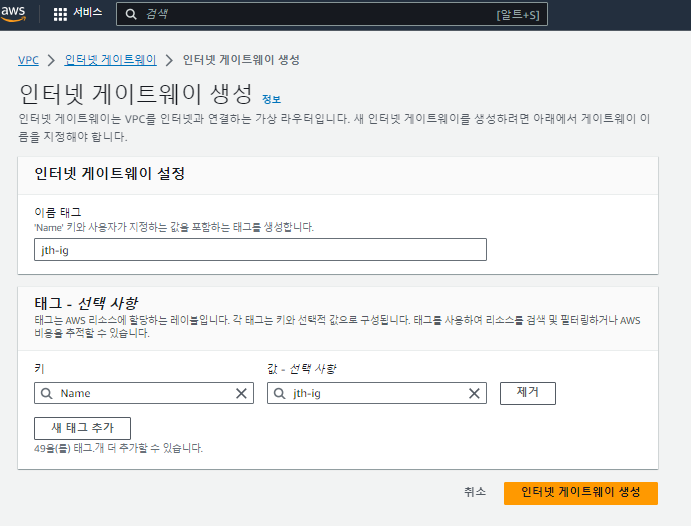
인터넷 게이트웨이(IG) 설정
게이트웨이는 이름만 정해주면 된다.
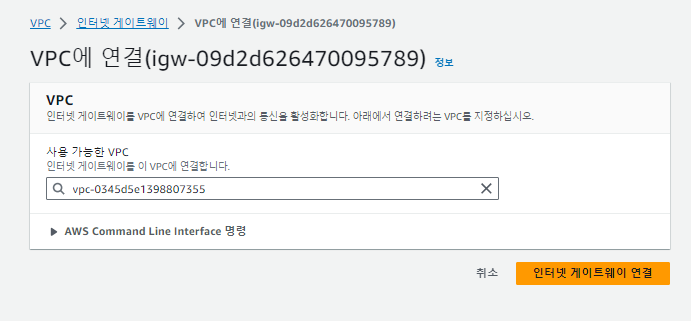
만든 게이트웨이를 VPC에 연결해준다.
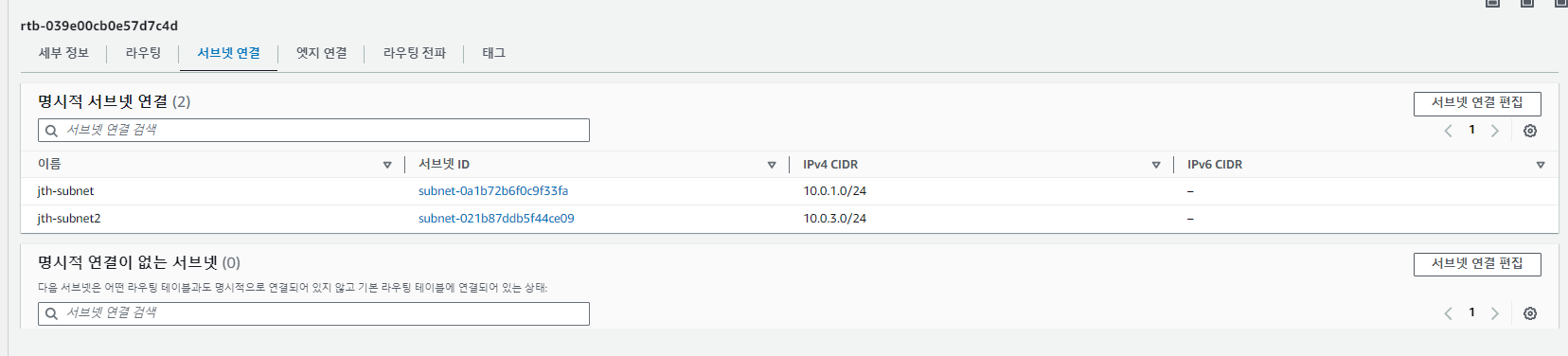
라우팅 테이블 수정
라우팅 테이블은 VPC를 만들면 자동으로 만들어진다. 아래 사진에서 라우팅 테이블에
외부로 나가는 설정이 없는 것을 확인할 수 있다.
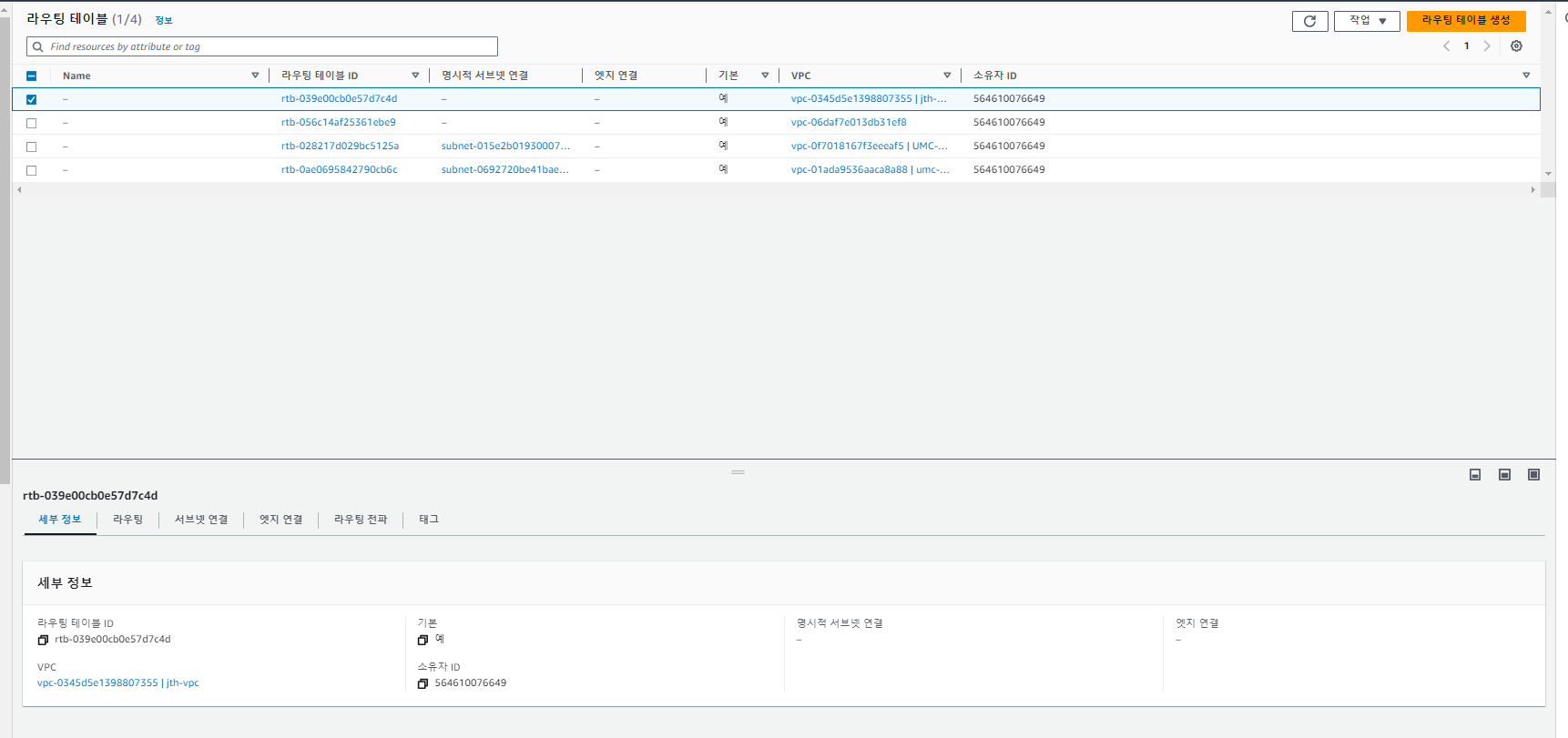


라우팅 편집을 통해 0.0.0.0/0(외부 IP 대역)이 목적지일 때, IG로 나가도록
설정을 해준다.
이제 외부로 나가도록(외부와 통신이 가능하도록) 설정이 된 라우팅을 서브넷에
연결해주면, 해당 서브넷은 퍼블릭 서브넷이 된다!
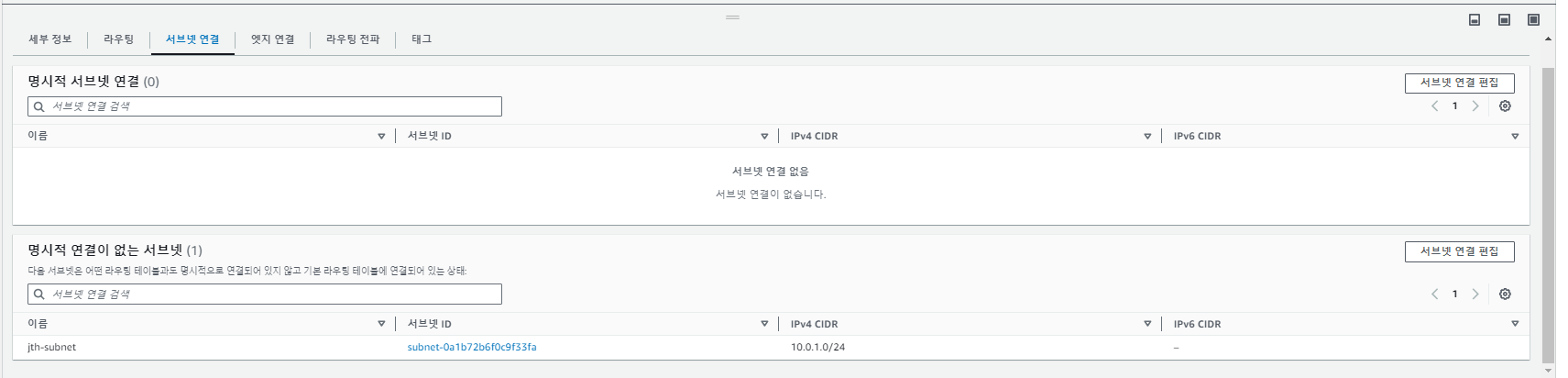
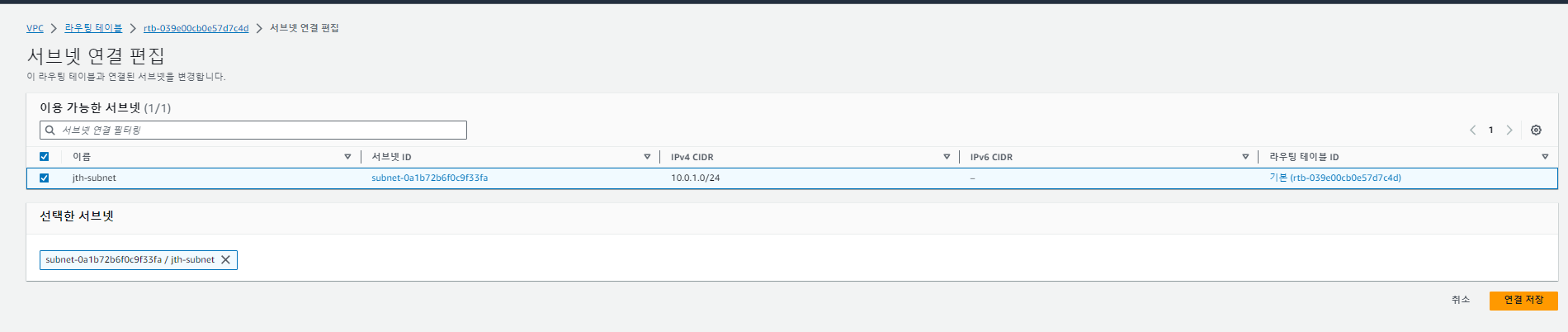
해당 라우팅 테이블을 원하는 서브넷에 연결해준다.
보안 그룹
보안 그룹의 개념
보안 그룹은 인스턴스 각각에 보안 설정을 할 수 있는 서비스로 방화벽과
유사하다고 볼 수 있다.
보안 그룹 생성
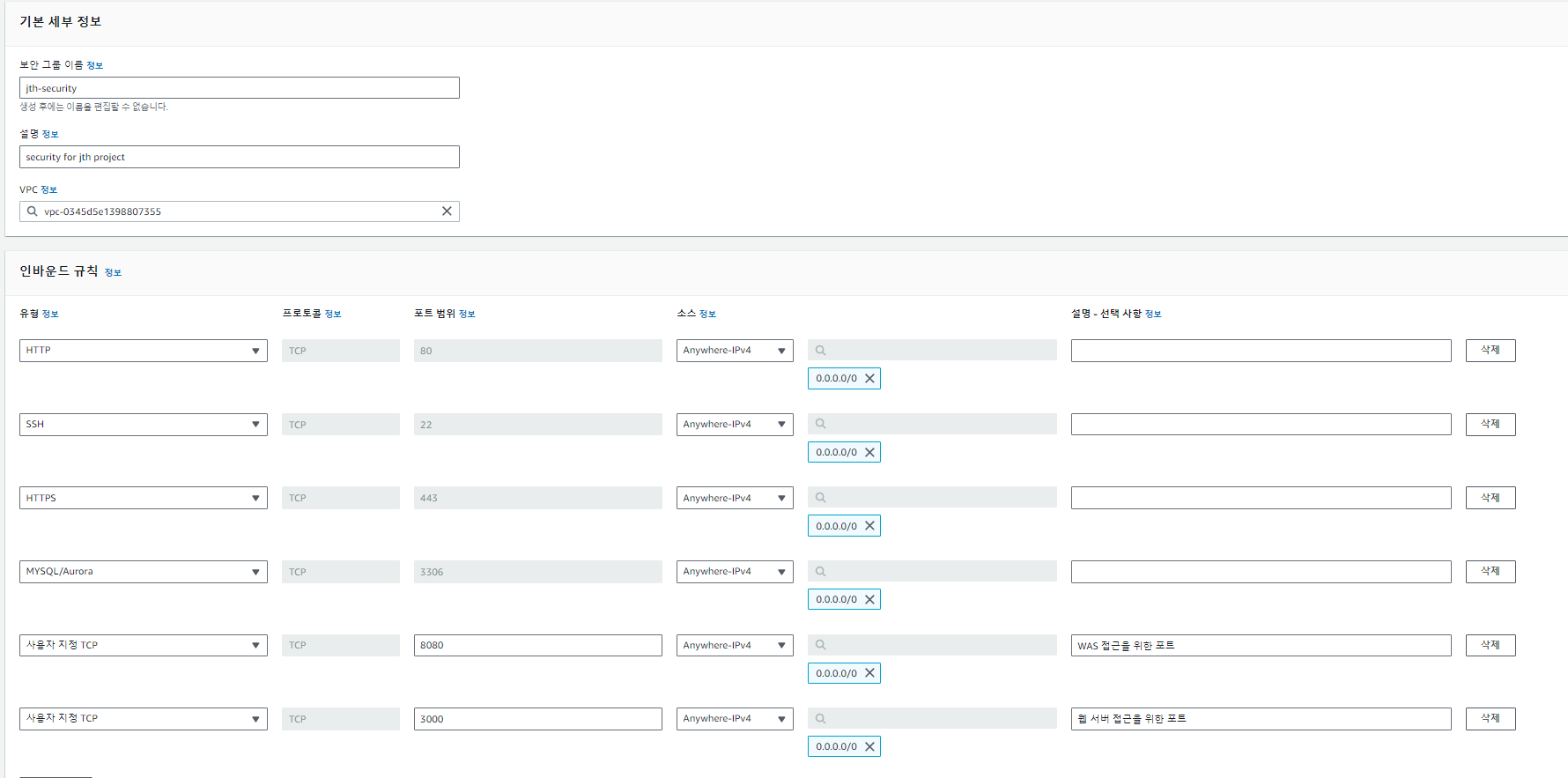
위 사진과 같이 기존에 만들어 두었던 VPC를 선택하고 외부에서 접근이 가능하도록
인바운드 규칙을 설정해준다.
EC2 생성
서울 리전인 것을 확인하고, 새 인스턴스 시작을 통해 EC2를 생성한다.
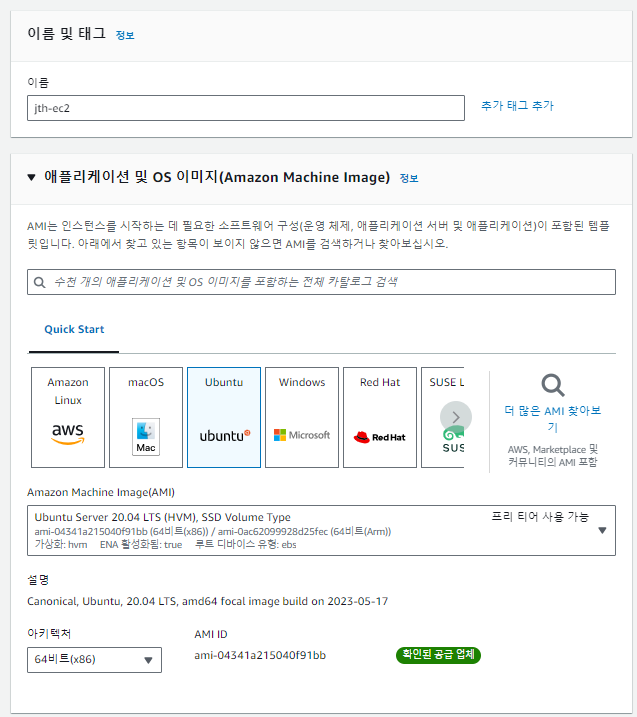
이름을 정하고 OS를 선택한다. Ubuntu 18.04 혹은 20.04가 정보가 많다.
인스턴스 유형의 경우 micro 유형이 프리티어가 되니 해당 유형을 채택한다.

기존에 사용하던 키 페어를 쓸 경우 해당 키 페어를 선택하고, 새로 만들어도 된다.
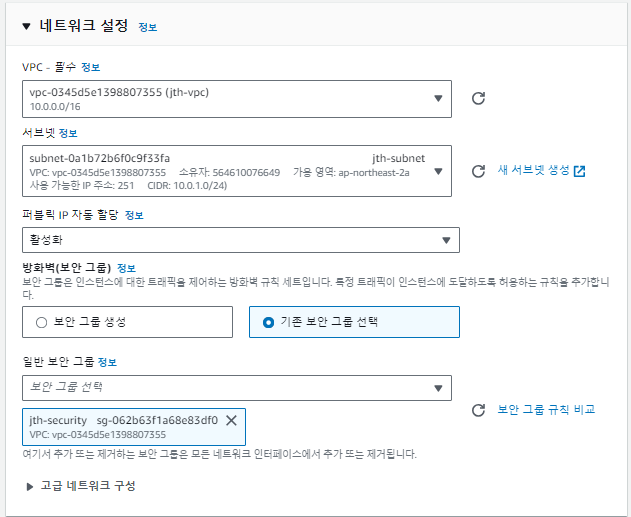
네트워크 설정에 만들어놨던 VPC와 보안그룹을 EC2에 설정해준다.
EC2 생성을 완료한다.
EC2 JDK 설치
인텔리제이나 콘솔에서 EC2에 접속한뒤
# EC2 인스턴스
$ sudo apt-get update
$ sudo apt-get install openjdk-11-jdk탄력적 IP 설정
탄력적 IP
탄력적 IP는 인스턴스의 IG를 거쳐 통신시 부여받을 IP 주소를 고정시켜 인스턴스가
종료된 후 다시 실행될 때 IP 주소가 바뀌지 않게 해준다.
앞선 설정에서 public IP를 자동 할당했기 때문에 EC2를 중지 후 재실행하면
IP주소 바뀐다.
따라서 EC2가 꺼지더라도 IP주소가 바뀌지 않도록 탄력적 IP를 연결해주는 것이
필요하다.
탄력적 IP 설정
EC2 좌측 메뉴에서 탄력적 IP를 찾아 이동한다.
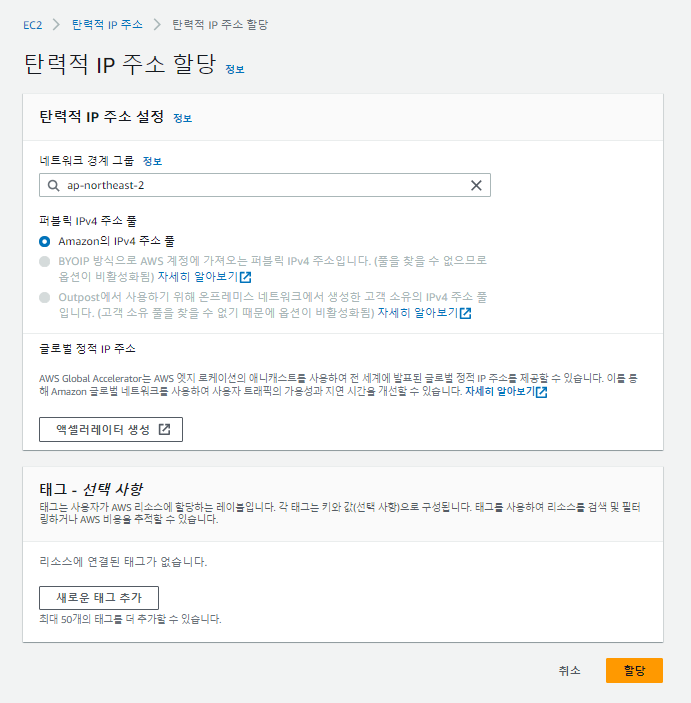
위 사진과 같이 기본으로 할당해준다.
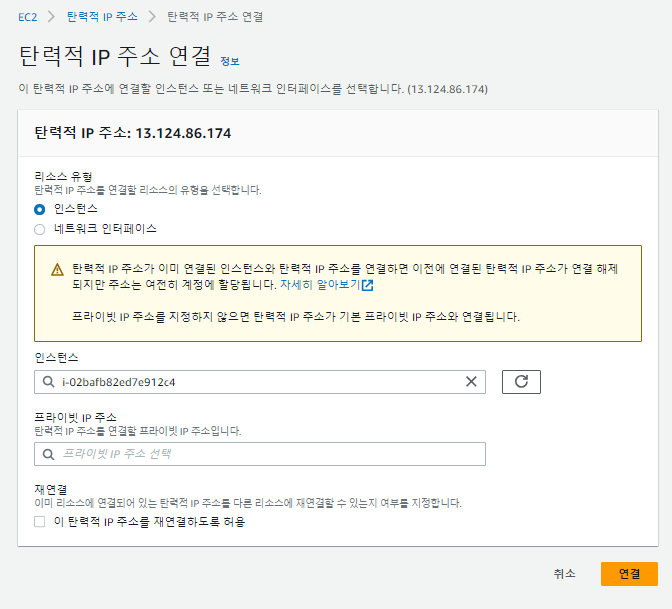
원하는 인스턴스에 탄력적 IP를 연결한다.
인텔리제이를 이용한 원격 접속 & 확인
도구 > 배포 > 원격 호스트 찾아보기로 들어간다.
(영문의 경우 Browse Remote Host)
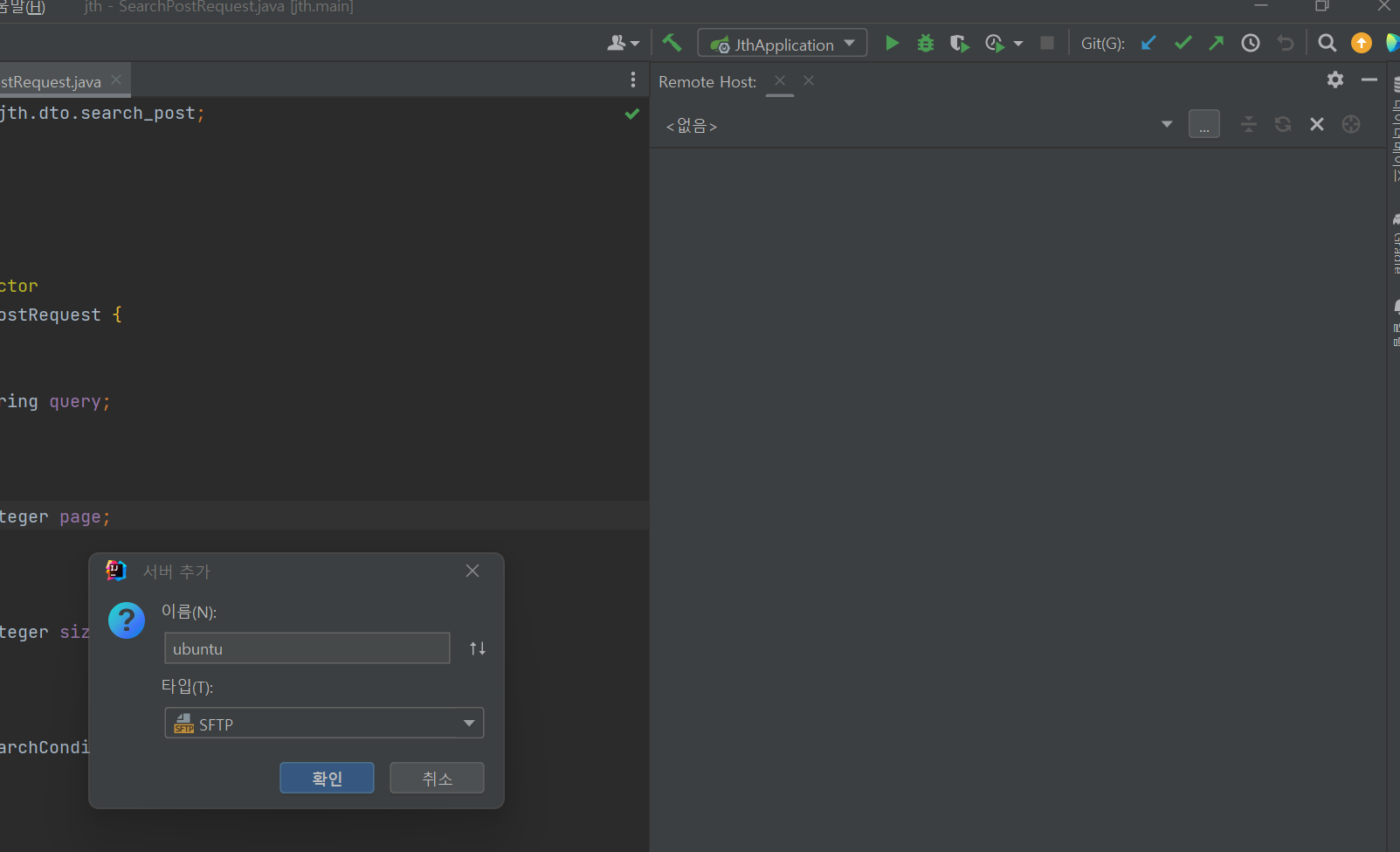
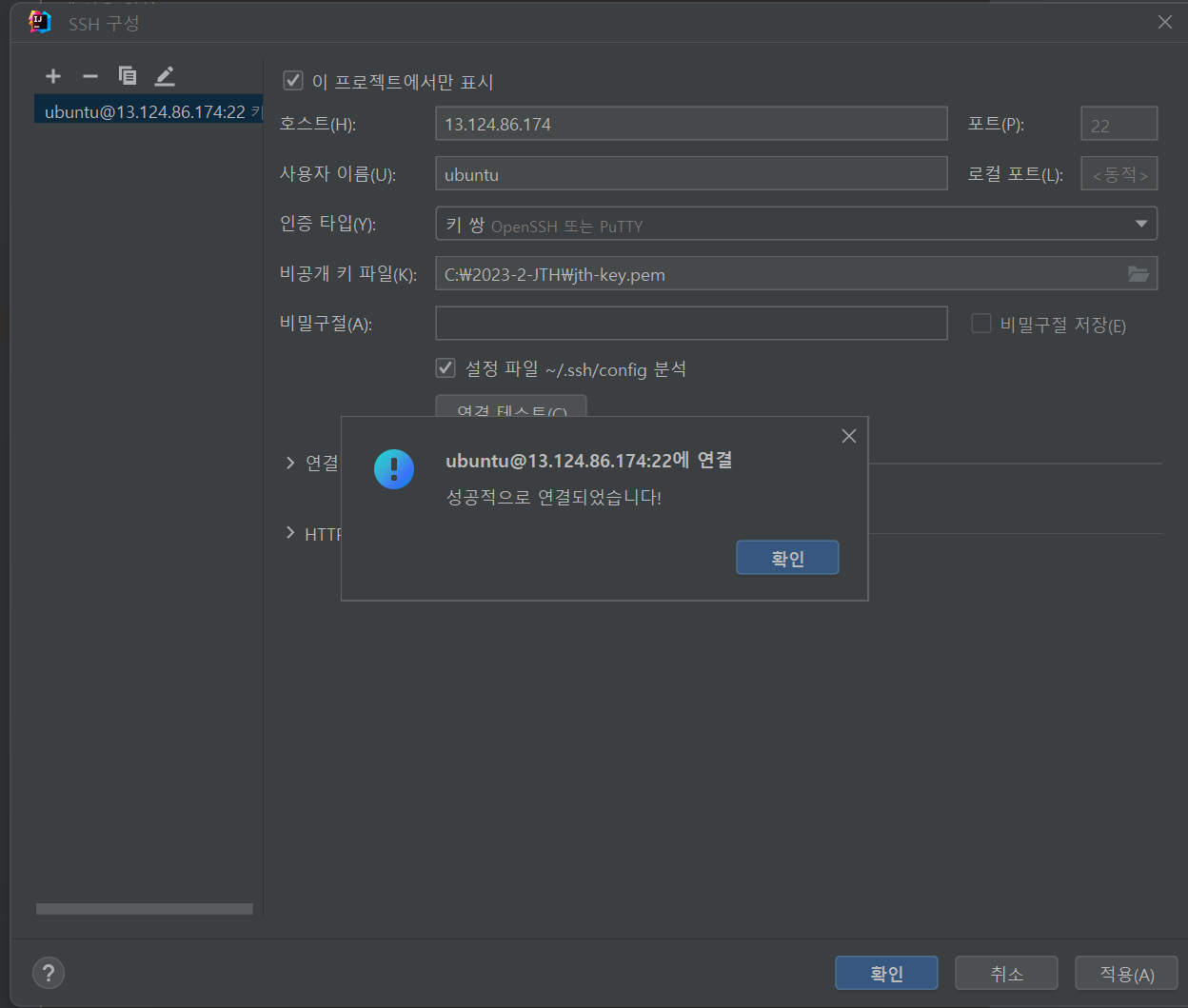
위 사진처럼 서버 이름을 구성한 뒤 호스트에 연결할 EC2의 public IP, 사용자 이름에
ubuntu를 입력하고 아까 생성했던 키 페어의 위치를 지정하여 테스트를 수행하여
연결 설정을 마친다.
RDS 설정
데이터베이스를 로컬에 두는 것은 좋지 않다. 로컬 컴퓨터가 다운되면 데이터베이스
접속이 안될 수 있고, 로컬에 접속한다는 것은 해당 컴퓨터에 데이터베이스에
접속이 되도록 포트포워딩을 수행해야 한다는 의미도 띈다.
따라서 데이터베이스도 EC2처럼 외부 컴퓨터를 빌려서 사용하는 것이 좋다.
EC2에 데이터베이스를 설치해서 사용해도 좋으나, RDS가 더 유연하게 데이터베이스를
사용할 수 있게 해준다.
서브넷 추가 생성
RDS를 VPC의 서브넷에 배치하기 위해서는 2개의 서브넷을 지정해줘야 한다. RDS는
만약을 대비해 2개의 서브넷을 요구하기 때문이다.
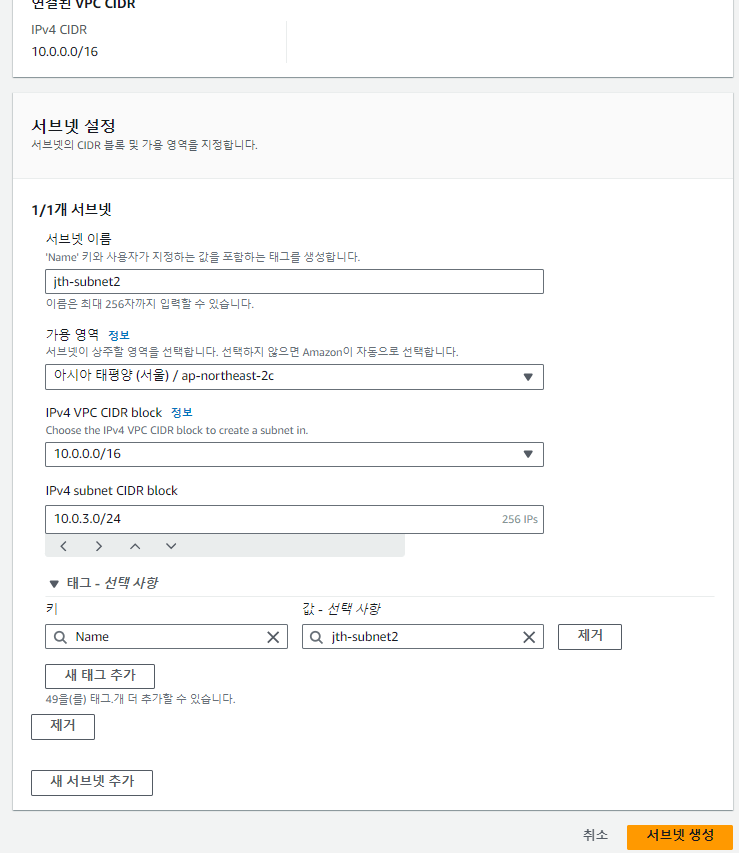
서브넷을 퍼블릭 서브넷으로 만들기 위해 외부와 연결이 된 라우팅 테이블에
연결을 해준다.
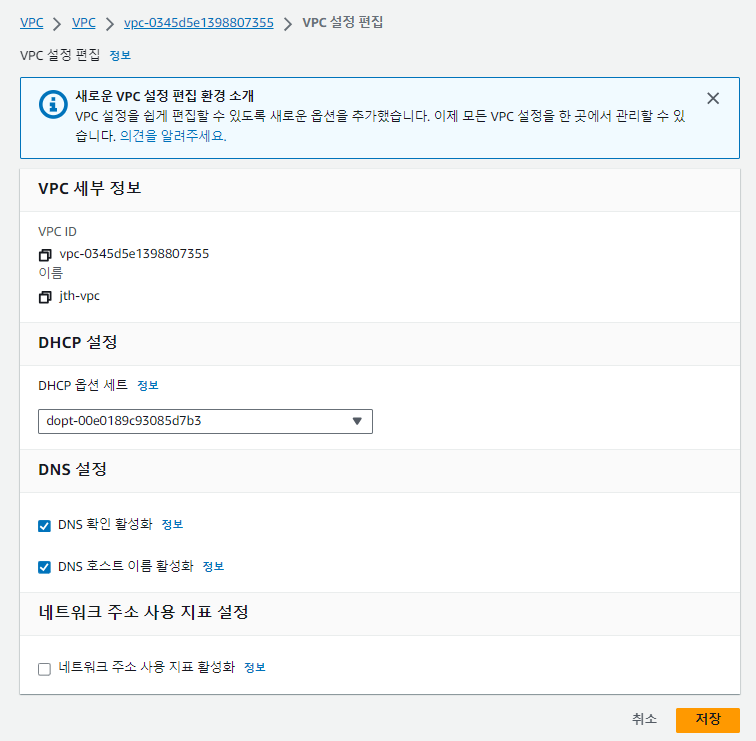
RDS 설정
RDS를 설정하기 전 RDS가 속하는 VPC 구성에서 DNS 설정을 활성화해주어야 한다.
새로 만들 DB를 원하는 VPC의 퍼블릿 서브넷에 배치하기 위한 DB 서브넷을 생성한다.
RDS 좌측 메뉴에서 서브넷 그룹으로 이동하여 DB 서브넷 그룹을 생성,
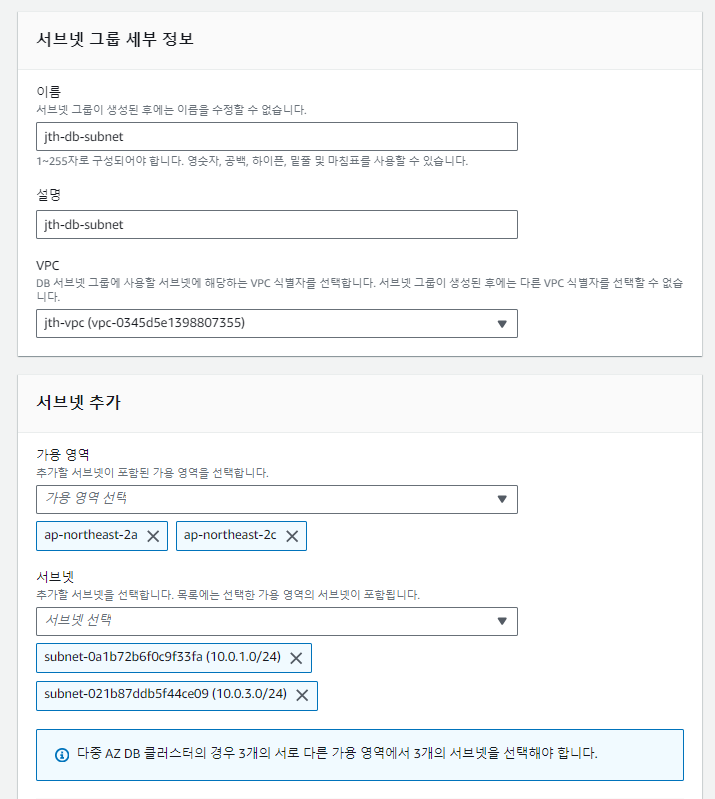
서브넷을 위 사진처럼 VPC를 선택한 후 퍼블릿 서브넷 2개를 선택한다.
(단, 서로 다른 2개의 가용영역으로)
이후 생성을 마무리한다.
RDS의 DB 메뉴로 가 데이터베이스 생성을 선택한다.
원하는 데이터베이스를 선택하고 프리 티어로 설정한다.
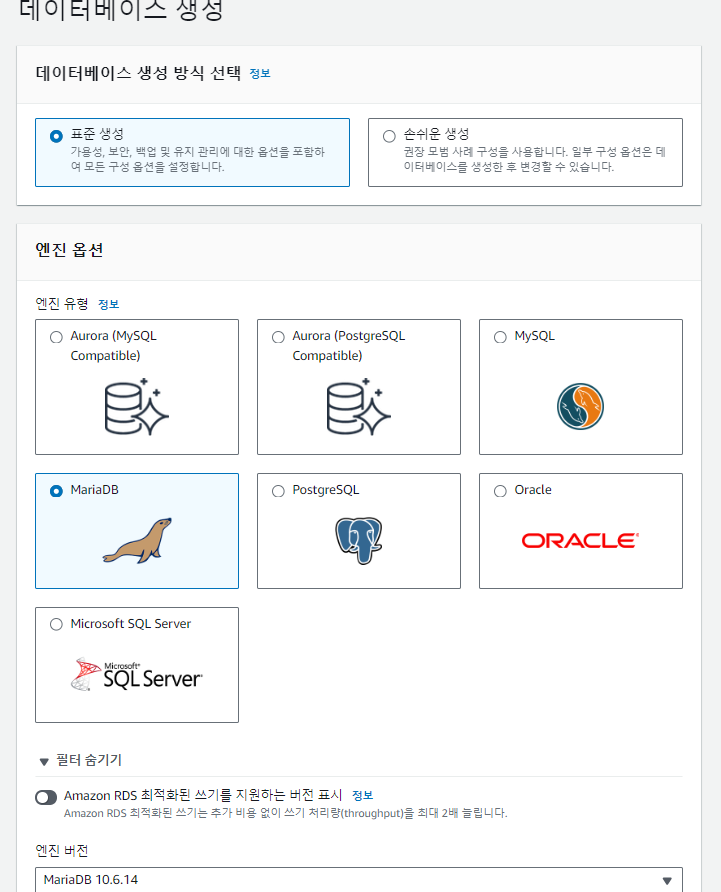
마스터 사용자 이름, 암호는 편한 것으로 쓰되 잊지 않게 주의해야 한다.
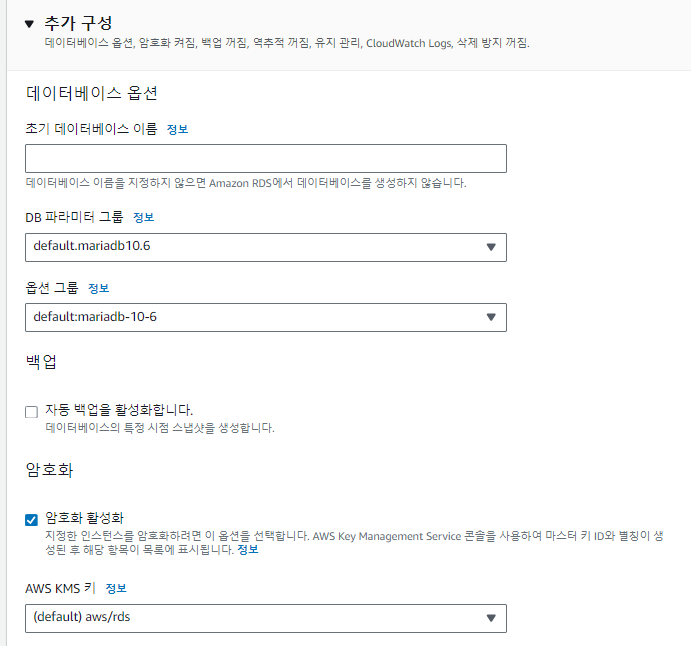
스토리지 자동 조정은 체크 해제한다.
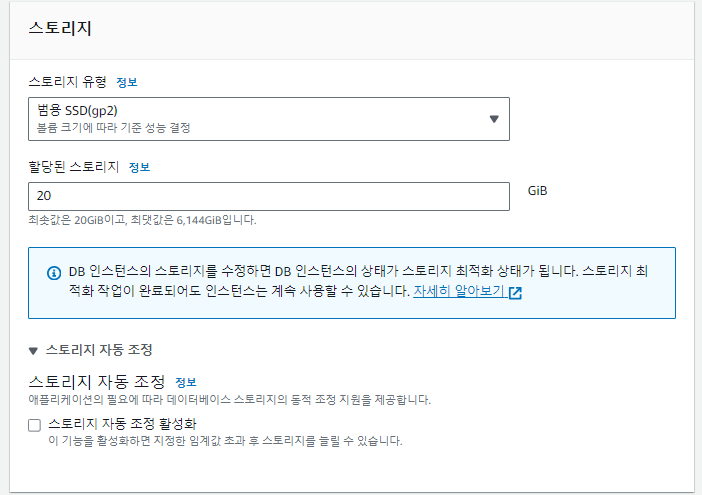
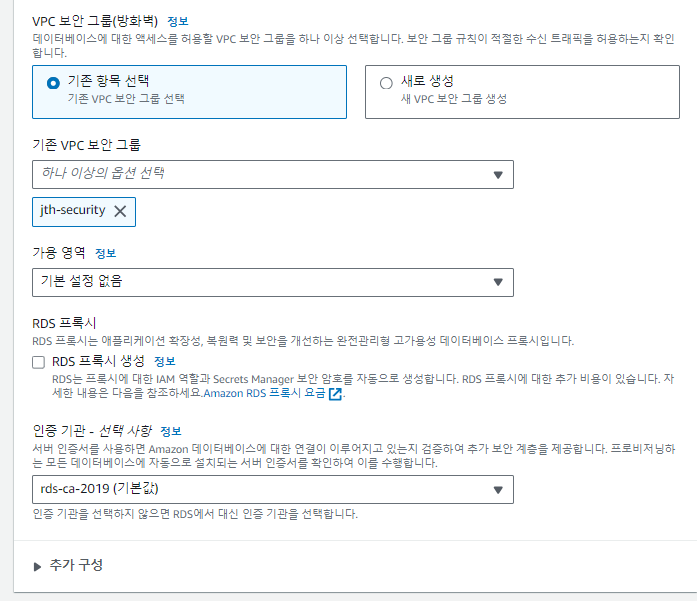
VPC를 기존에 만들어둔 것으로 선택후 앞서 생성한 DB 서브넷 그룹을 선택하고,
퍼블릭 액세스를 yes로 설정한다.
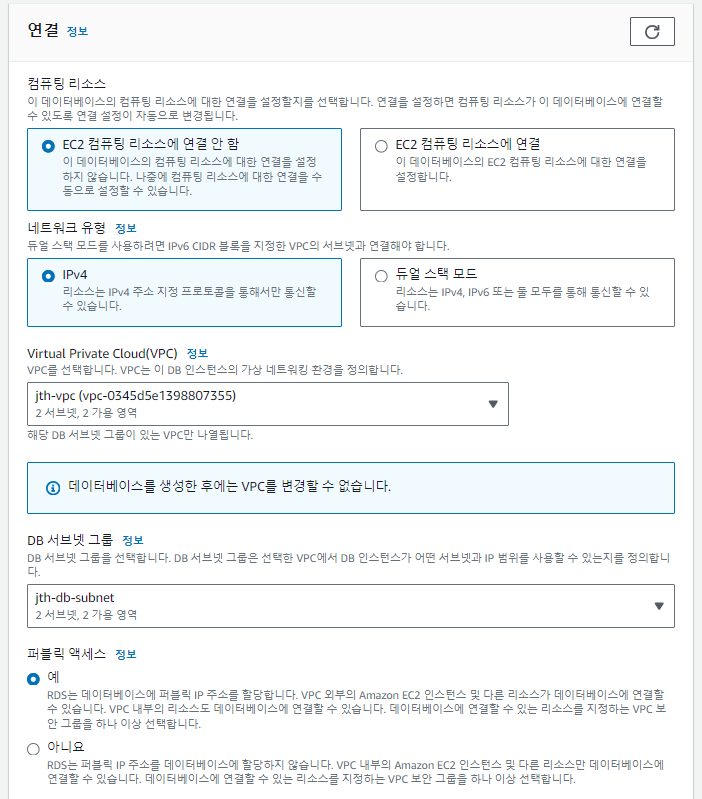
보안그룹은 VPC 설정시 만들었던 보안그룹으로 설정하고, 자동 백업은 체크 해제한다.
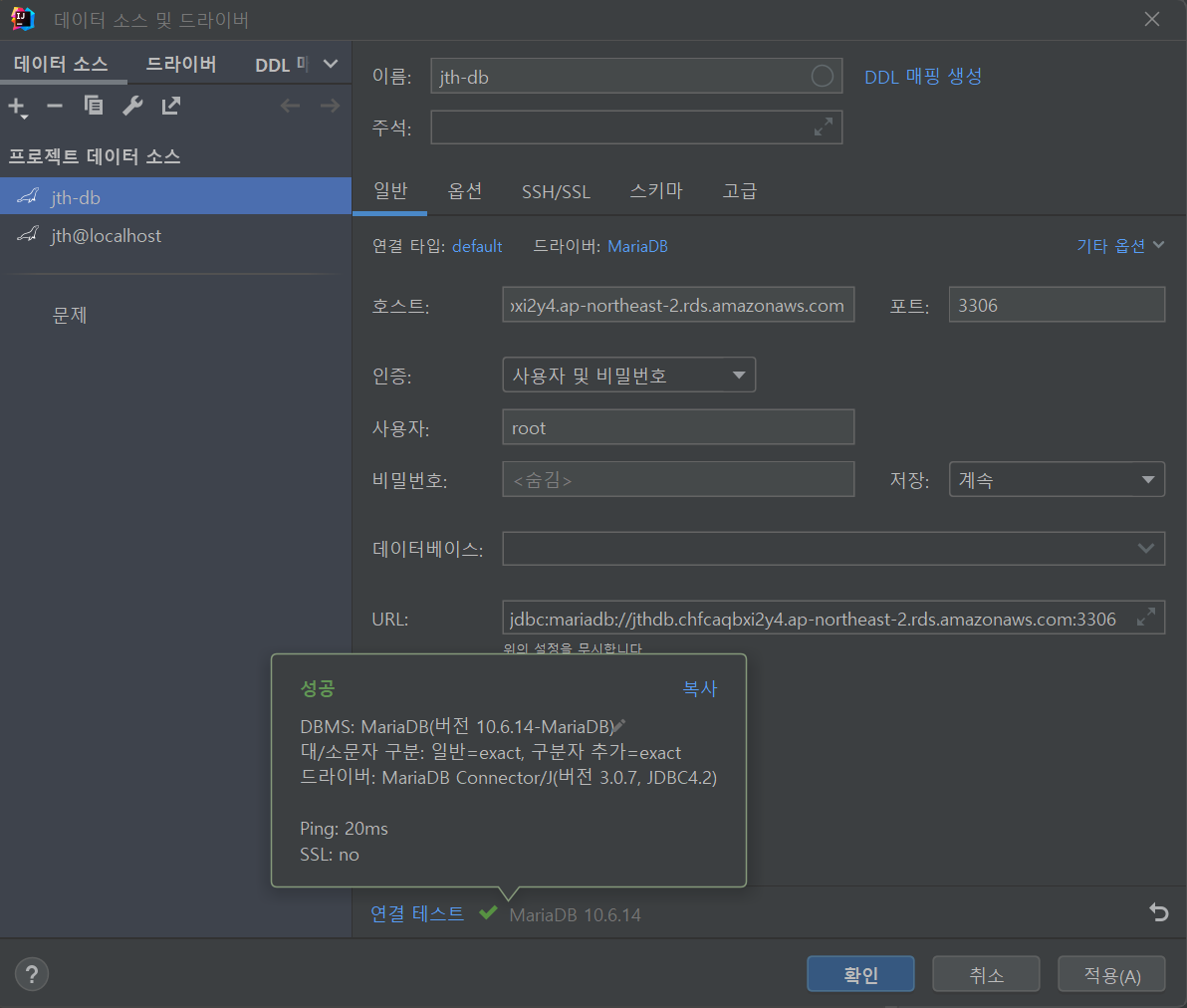
인텔리제이를 통한 원격 접속
인텔리제이 ultimate 버전에서는 데이터베이스와 관련된 기능을 제공한다.
우측 데이터베이스 탭을 들어간 후 원하는 추가 > 원하는 데이터베이스 타입을 선택하고
RDS의 엔드포인트를 복사하여 설정한 사용자 이름과 비밀번호를 입력해준다.
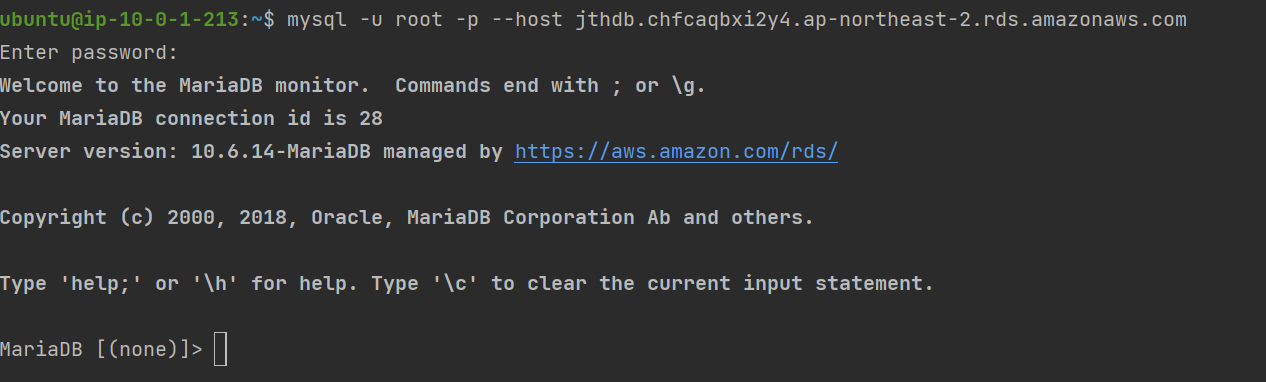
EC2에서 RDS 원격 접속
EC2에 콘솔로 접속한 후 mariaDB를 설치해준다.
sudo apt install mariadb-server정상적으로 접속이 되는지 확인한다.
프로젝트 빌드 & 배포
필자가 배포하려는 프로젝트의 경우 yml 포맷을 이용하여 설정 파일을 구성하였고
개발(dev)과 배포(prod) 환경을 프로필을 구분하여 놓았다.
application.yml
spring:
config:
activate:
on-profile: dev
datasource:
url: jdbc:mariadb://localhost:3306/jth
username: user_jth
password:
driver-class-name: org.mariadb.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
properties:
hibernate:
format_sql: true
logging:
level:
org.hibernate.SQL: debug
---
spring:
config:
activate:
on-profile: prod
datasource: #OS 환경 변수를 통해 주입 받는다.
url: ${DB_URL}
username: ${DB_USERNAME}
password: ${DB_PW}
driver-class-name: org.mariadb.jdbc.Driver
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
format_sql: true
특정 프로필을 이용하여 배포하려면 어떻게 해야할까?
./gradlew bootJar
./gradlew bootJar위 명령을 이용하면 모든 프로필을 통합하여 빌드하는 것이 가능하다.
jar파일 실행시 지정된 프로필 옵션에 따라 설정이 적용된다.
참고 : Windows의 경우 ./gradlew.bat bootJar 을 통해 수행해야 한다.
EC2에 빌드 파일 전송
SCP(Secure Copy Protocol)를 이용하여 배포하고자 하는 서버 머신에
jar 파일을 전송할 수 있다.
빌드 작업을 서버 머신에서 수행할 경우 EC2 프리티어는 램이 1GB밖에 제공되지
않으므로 굉장히 시간이 오래 소요될 수 있다. 따라서 빌드를 개발을 진행했던
로컬에서 진행하고 결과물을 서버로 전송하여 배포하는 것이 효율적이다.
scp -i [pem 파일 경로] [jar 파일 경로] [사용자 이름]@{EC2 public IP]:/[도착 디렉터리 경로]위 명령을 앞서 설정한 EC2에 전송하고자 할 경우 다음과 같이 치환할 수 있다.
주의 : 아래 예시는 .pem과 .jar 파일이 모두 현재 위치에 존재할 경우이다.
scp -i ./jth-key.pem ./jth-0.0.1-SNAPSHOT.jar ubuntu@13.126.86.174:/home/ubuntu서버 실행
콘솔이나 인텔리제이 터미널을 통해 EC2에 원격 접속한 후
java -jar {jar 파일 경로} --spring.profiles.active=prod위 명령을 통해 프로필이 통합된 jar에 프로필을 지정하여 실행할 수 있다.
만약 현재 접속한 세션이 닫혀도 백그라운드에서 서버가 계속 작동하길 원할 경우
nohup java -jar {jar 파일 경로} --spring.profiles.active=prod &nohup 은 Unix 및 Unix 계열 운영체제에서 사용되는 명령어로, 사용자가 로그아웃한 후에도 프로세스를 계속 실행시키는 데 사용된다. "nohup"은 "no hang up"의
약자다.
