Database
1.MySQL CHAR, VARCHAR, TEXT 비교 & 정리

개요 Untitled 프로젝트 ERD 전반을 1차적으로 구성하고 팀원에게 피드백을 받던 와중, 위와 같이 VARCHAR 타입을 남발하는 설계에 대해 재고해보라는 의견을 들었다. 개인적으로 CHAR 는 고정 길이, VARCHAR 는 가변 길이로 데이터를 저장한다고
2.MySQL 기본

특정 범위로 데이터를 필터링하여 조회할 때 사용정해진 임의 값들에 해당하는 경우의 데이터 조회시 사용문자열 내용 검색을 위해 사용, % 은 어떤 것이든 \_ 는 한 글자 의미쿼리 내에 또 다른 쿼리를 사용서브쿼리의 여러 결과중 한 가지만 만족해도 가능SOME 은 ANY
3.MySQL 내장함수 정리
전달받은 문자열을 모두 결합하여 한 문자열로 반환하나라도 NULL이 존재하면 NULL 반환문자열 내에서 찾는 문자열이 처음 나타나는 위치를 찾아 위치 반환찾는 문자열 존재하지 않을 시 0 반환MySQL에서는 문자열 시작 인덱스가 1임에 유의정해진 방향에서 지정 개수만큼
4.MySQL 고급
똑같은 테이블을 SELECT 기반으로 생성테이블 수정시 사용인덱스는 빠른 데이터 검색을 위해 사용하고, 인덱스가 있는 테이블은 처리속도가 느려질 수 있으므로 수정보다는 검색이 자주 사용되는 테이블에서 사용하는 것이 좋다.PK는 기본적으로 인덱스가 생성되어 있다.중복값이
5.About FULLTEXT Index
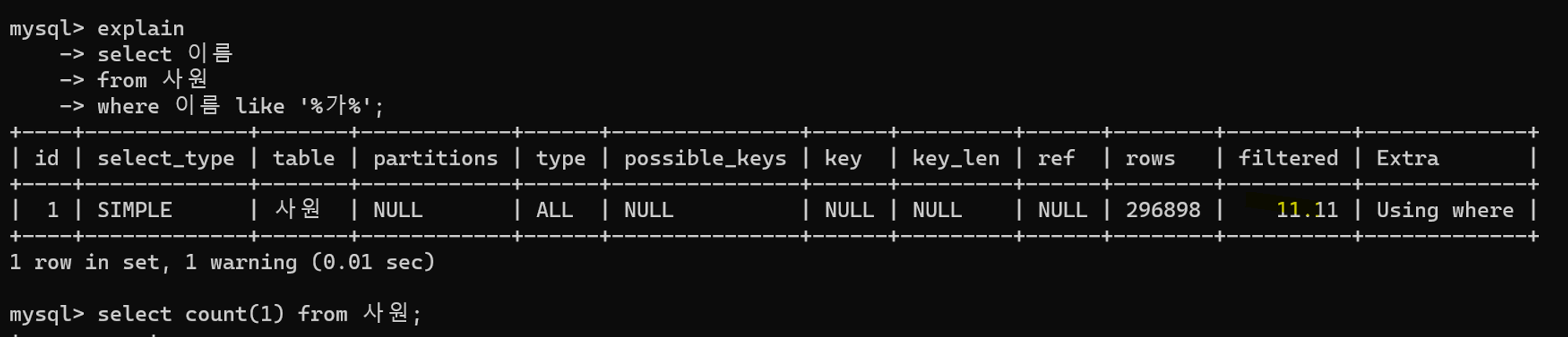
MySQL에서 문자열 검색시 LIKE 와 같은 연산자를 통해 원하는 텍스트를 필터링하여 조회한다.그러나 검색할 텍스트 건수가 많을 경우 과부하, 응답시간 증가 등의 성능 저하를 유발할 수 있다. 이 문제는 전체 텍스트 검색 기능을 통해 해결할 수 있다. 전체 텍스트 검