<수업내용>
베이즈안 정리를 활용한 스팸메일 구분
import pandas as pd
table=pd.DataFrame(index=['Spam','Ham'])
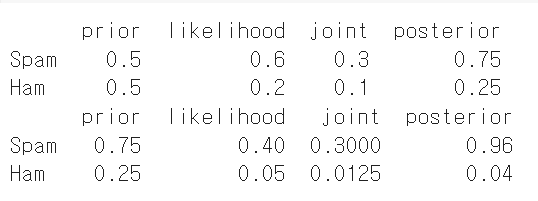
table['prior']=0.5
table['likelihood']=0.6, 0.2
table['joint']=table['prior']*table['likelihood']
norm_contant=table['joint'].sum()
table['posterior']= table['joint']/norm_contant
print(table)
table_=pd.DataFrame(index=['Spam','Ham'])
table_['prior']=table['posterior']
table_['likelihood']=0.40, 0.05
table_['joint']=table_['prior']*table_['likelihood']
norm_contant_=table_['joint'].sum()
table_['posterior']= table_['joint']/norm_contant_
print(table_)

함수로 작성
table = pd.DataFrame(index=['Spam', 'Ham'])
def bayesian_table(table, prior, likelihood):
if len(table.columns) >=1:
table['prior']=table['posterior']
else:
table['prior']=prior
table['likelihood']=likelihood
table['joint']=table['prior']*table['likelihood']
norm_contant=table['joint'].sum()
table['posterior']= table['joint']/norm_contant
return table
prior = 0.5
likelihood = [0.6, 0.2]
table = bayesian_table(table, prior, likelihood)
print(table)
likelihood = [0.4, 0.05]
table = bayesian_table(table, prior, likelihood)
print(table)
연습문제

import pandas as pd
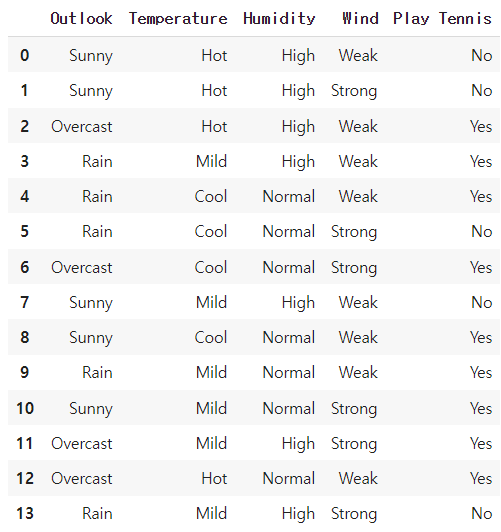
df=pd.read_csv('./PlaybTennis.csv')
df
prior_yes=len(df[df['Play Tennis']=='Yes'])/len(df)
prior_no=len(df[df['Play Tennis']=='No'])/len(df)
print(prior_yes)
print(prior_no)
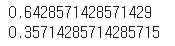
df['Wind'].unique()
likelihood_yes_weak=len(df[(df['Play Tennis']=='Yes') & (df['Wind']=='Weak')])/len(df[df['Play Tennis']=='Yes'])
likelihood_yes_strong=len(df[(df['Play Tennis']=='Yes') & (df['Wind']=='Strong')])/len(df[df['Play Tennis']=='Yes'])
print(likelihood_yes_weak)
print(likelihood_yes_strong)

likelihood_no_weak=len(df[(df['Play Tennis']=='No') & (df['Wind']=='Weak')])/len(df[df['Play Tennis']=='No'])
likelihood_no_strong=len(df[(df['Play Tennis']=='No') & (df['Wind']=='Strong')])/len(df[df['Play Tennis']=='No'])
print(likelihood_no_weak)
print(likelihood_no_strong)

df['Outlook'].unique()
likelihood_yes_sunny=len(df[(df['Play Tennis']=='Yes') & (df['Outlook']=='Sunny')])/len(df[df['Play Tennis']=='Yes'])
likelihood_yes_overcast=len(df[(df['Play Tennis']=='Yes') & (df['Outlook']=='Overcast')])/len(df[df['Play Tennis']=='Yes'])
likelihood_yes_rain=len(df[(df['Play Tennis']=='Yes') & (df['Outlook']=='Rain')])/len(df[df['Play Tennis']=='Yes'])
print(likelihood_yes_sunny)
print(likelihood_yes_overcast)
print(likelihood_yes_rain)