03. 시스템 학습 및 확장 가이드
🎯 학습 목표
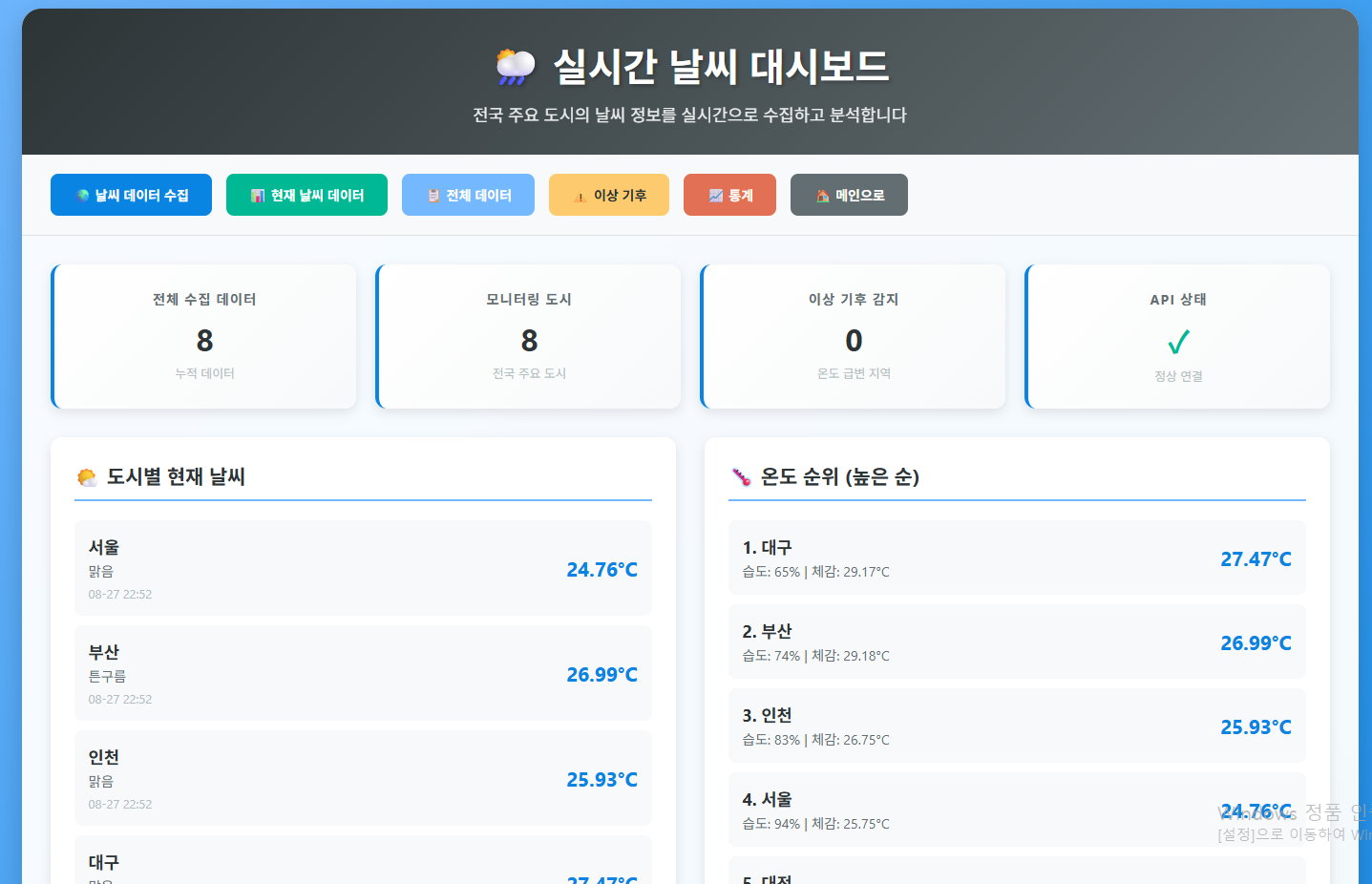
이 문서는 현재 Spring Batch 시스템을 어떻게 공부하고, 어떻게 확장할 수 있는지 상세하게 안내합니다.
📚 코드 분석을 통한 학습 방법
1. 핵심 클래스 분석 순서
1단계: 기본 구조 이해
// 1. 메인 애플리케이션 클래스 분석
SpringBatchApplication.java
→ @SpringBootApplication 어노테이션의 의미
→ main() 메서드의 역할
→ Spring Boot 자동 설정 메커니즘
// 2. 설정 클래스 분석
BatchConfig.java, WeatherBatchConfig.java
→ @Configuration 어노테이션
→ @Bean 메서드들의 의존성 주입
→ Job, Step, ItemReader/Processor/Writer 관계2단계: 배치 컴포넌트 상세 분석
Job 분석 (작업 단위):
@Bean
public Job importUserJob(Step step1) {
return new JobBuilder("importUserJob", jobRepository)
.start(step1) // 시작 Step 지정
.build();
}
// 학습 포인트:
// - Job은 여러 Step을 포함할 수 있음
// - JobRepository는 배치 실행 메타데이터 관리
// - JobBuilder 패턴 사용법Step 분석 (처리 단계):
@Bean
public Step step1(ItemReader<Person> reader,
ItemProcessor<Person, Person> processor,
ItemWriter<Person> writer) {
return new StepBuilder("step1", jobRepository)
.<Person, Person>chunk(3, transactionManager) // 청크 크기 = 3
.reader(reader) // 데이터 읽기
.processor(processor) // 데이터 처리
.writer(writer) // 데이터 쓰기
.build();
}
// 학습 포인트:
// - 청크 기반 처리: 3개씩 묶어서 트랜잭션 처리
// - Reader → Processor → Writer 파이프라인
// - 각 컴포넌트의 독립성과 재사용성3단계: 각 컴포넌트 심화 분석
ItemReader 분석:
// CSV 파일 읽기
@Bean
public FlatFileItemReader<Person> reader() {
return new FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(new ClassPathResource("sample-data.csv"))
.delimited() // CSV 구분자 설정
.names(new String[]{"firstName", "lastName", "email"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Person>() {{
setTargetType(Person.class); // 매핑 대상 클래스
}})
.build();
}
// 학습 해볼 점:
// 1. 다른 데이터 소스는? (Database, JSON, XML)
// 2. 파일 경로 동적 설정 방법은?
// 3. 에러 발생 시 처리 방법은?ItemProcessor 분석:
// 날씨 데이터 처리 예시
@Bean
public ItemProcessor<String, WeatherData> weatherProcessor() {
return cityCode -> {
try {
// 1. 외부 API 호출
WeatherApiResponse response = weatherApiService
.getCurrentWeather(cityCode).block();
// 2. 데이터 변환
WeatherData weatherData = convertToWeatherData(response, cityCode);
// 3. 비즈니스 로직 (이상 기후 탐지)
detectAbnormalWeather(weatherData);
return weatherData;
} catch (Exception e) {
log.error("Processing failed for {}: {}", cityCode, e.getMessage());
return null; // null 반환 시 해당 아이템 스킵
}
};
}
// 학습 해볼 점:
// 1. 복잡한 변환 로직 구현 방법
// 2. 외부 API 호출 시 에러 처리
// 3. 조건부 처리 (특정 조건에서만 처리)
// 4. 병렬 처리를 위한 멀티스레드 적용2. 실전 코드 실습 방법
디버깅을 통한 학습:
// 1. IDE에서 브레이크포인트 설정
@Bean
public ItemProcessor<Person, Person> processor() {
return (item) -> {
// ↓ 여기에 브레이크포인트 설정
log.info("Processing person: {}", item);
// 데이터 변환 로직 실행 과정 관찰
String upperFirstName = item.getFirstName().toUpperCase();
item.setFirstName(upperFirstName);
return item; // ← 반환값 확인
};
}로그 분석:
# 애플리케이션 실행 후 로그 확인
./gradlew bootRun
# 주요 확인 포인트:
# - Job 실행 시작/종료 로그
# - Step 실행 과정
# - 청크 단위 처리 로그
# - 에러 발생 시 스택 트레이스🛠️ 시스템 확장 방법
1. 새로운 배치 Job 추가
예시: 주식 데이터 배치 추가
@Configuration
public class StockBatchConfig {
@Autowired
private JobRepository jobRepository;
@Autowired
private PlatformTransactionManager transactionManager;
// 1. 새로운 Job 정의
@Bean
public Job collectStockDataJob(Step stockCollectionStep) {
return new JobBuilder("collectStockDataJob", jobRepository)
.start(stockCollectionStep)
.build();
}
// 2. Step 정의
@Bean
public Step stockCollectionStep() {
return new StepBuilder("stockCollectionStep", jobRepository)
.<String, StockData>chunk(5, transactionManager)
.reader(stockSymbolReader()) // 주식 심볼 리더
.processor(stockDataProcessor()) // 주식 API 호출
.writer(stockDataWriter()) // DB 저장
.build();
}
// 3. 주식 심볼 읽기
@Bean
public ItemReader<String> stockSymbolReader() {
List<String> symbols = List.of("AAPL", "GOOGL", "MSFT", "AMZN");
return new ItemReader<String>() {
private int index = 0;
@Override
public String read() {
if (index < symbols.size()) {
return symbols.get(index++);
}
return null;
}
};
}
// 4. 주식 데이터 처리
@Bean
public ItemProcessor<String, StockData> stockDataProcessor() {
return symbol -> {
// Yahoo Finance API 또는 Alpha Vantage API 호출
// JSON 응답을 StockData 엔티티로 변환
return stockApiService.getStockData(symbol);
};
}
// 5. DB 저장
@Bean
public ItemWriter<StockData> stockDataWriter() {
return chunk -> {
List<? extends StockData> stockDataList = chunk.getItems();
stockDataRepository.saveAll(stockDataList);
};
}
}필요한 추가 클래스들:
// StockData 엔티티
@Entity
@Table(name = "stock_data")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class StockData {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String symbol; // 주식 심볼
private String companyName; // 회사명
private Double currentPrice; // 현재 가격
private Double openPrice; // 시가
private Double highPrice; // 고가
private Double lowPrice; // 저가
private Long volume; // 거래량
private LocalDateTime collectedAt;
}
// StockDataRepository
@Repository
public interface StockDataRepository extends JpaRepository<StockData, Long> {
List<StockData> findBySymbolOrderByCollectedAtDesc(String symbol);
List<StockData> findTop10ByOrderByCollectedAtDesc();
}
// StockApiService
@Service
public class StockApiService {
private final WebClient webClient;
public StockApiService() {
this.webClient = WebClient.builder()
.baseUrl("https://api.example.com/stock")
.build();
}
public StockData getStockData(String symbol) {
// 실제 API 호출 로직 구현
return webClient.get()
.uri("/quote/{symbol}", symbol)
.retrieve()
.bodyToMono(StockData.class)
.block();
}
}2. 스케줄링 추가
Cron 표현식으로 자동 실행:
@Component
@EnableScheduling
public class BatchScheduler {
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job collectWeatherDataJob;
@Autowired
private Job collectStockDataJob;
// 매시간 정각에 날씨 데이터 수집
@Scheduled(cron = "0 0 * * * *")
public void runWeatherBatch() {
try {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(collectWeatherDataJob, params);
} catch (Exception e) {
log.error("Weather batch scheduling failed", e);
}
}
// 평일 오전 9시에 주식 데이터 수집
@Scheduled(cron = "0 0 9 * * MON-FRI")
public void runStockBatch() {
try {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(collectStockDataJob, params);
} catch (Exception e) {
log.error("Stock batch scheduling failed", e);
}
}
}3. 에러 처리 및 재시도 로직 추가
재시도 정책 설정:
@Bean
public Step resilientWeatherStep() {
return new StepBuilder("resilientWeatherStep", jobRepository)
.<String, WeatherData>chunk(3, transactionManager)
.reader(cityReader())
.processor(weatherProcessor())
.writer(weatherWriter())
// 재시도 설정
.faultTolerant()
.retry(Exception.class) // 모든 예외에 대해 재시도
.retryLimit(3) // 최대 3번 재시도
// 특정 예외는 건너뛰기
.skip(IllegalArgumentException.class)
.skipLimit(5) // 최대 5개까지 건너뛰기
.build();
}실패한 아이템 별도 처리:
@Bean
public Step stepWithFailureHandling() {
return new StepBuilder("stepWithFailureHandling", jobRepository)
.<String, WeatherData>chunk(3, transactionManager)
.reader(cityReader())
.processor(weatherProcessor())
.writer(weatherWriter())
.faultTolerant()
// 실패한 아이템을 별도 파일로 저장
.skipListener(new SkipListener<String, WeatherData>() {
@Override
public void onSkipInProcessing(String item, Throwable t) {
log.error("Skipped processing for city: {}, Error: {}",
item, t.getMessage());
// 실패 로그를 파일이나 별도 테이블에 저장
saveFailedItem(item, t.getMessage());
}
})
.build();
}4. 성능 최적화
멀티스레드 처리:
@Bean
public Step parallelWeatherStep() {
return new StepBuilder("parallelWeatherStep", jobRepository)
.<String, WeatherData>chunk(3, transactionManager)
.reader(cityReader())
.processor(weatherProcessor())
.writer(weatherWriter())
// 멀티스레드 설정
.taskExecutor(taskExecutor())
.throttleLimit(4) // 동시 실행 스레드 수
.build();
}
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setQueueCapacity(25);
executor.setThreadNamePrefix("batch-thread-");
executor.initialize();
return executor;
}파티션 처리 (대용량 데이터):
@Bean
public Step partitionStep() {
return new StepBuilder("partitionStep", jobRepository)
.partitioner("slaveStep", partitioner())
.step(slaveStep())
.gridSize(4) // 4개 파티션으로 분할
.taskExecutor(taskExecutor())
.build();
}
@Bean
public Partitioner partitioner() {
return new Partitioner() {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> result = new HashMap<>();
// 도시 목록을 4개 그룹으로 분할
List<String> cities = List.of("Seoul", "Busan", "Incheon",
"Daegu", "Daejeon", "Gwangju",
"Ulsan", "Suwon");
int partitionSize = cities.size() / gridSize;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
int start = i * partitionSize;
int end = (i == gridSize - 1) ? cities.size() : (i + 1) * partitionSize;
context.put("cities", cities.subList(start, end));
result.put("partition" + i, context);
}
return result;
}
};
}🔍 고급 학습 방향
1. Spring Batch Admin 연동
- 배치 작업 모니터링 웹 UI
- 실행 이력 및 상태 관리
- 실패한 Job 재시작 기능
2. 메시지 큐 연동 (RabbitMQ, Kafka)
// Kafka를 통한 배치 트리거
@KafkaListener(topics = "weather-batch-trigger")
public void handleBatchTrigger(String message) {
// 메시지 수신 시 배치 실행
jobLauncher.run(collectWeatherDataJob, createJobParameters());
}3. 클라우드 환경 배포
- AWS Batch, Google Cloud Dataflow
- Kubernetes CronJob
- Docker 컨테이너화
4. 데이터베이스 최적화
// 대용량 처리를 위한 JPA 배치 설정
@Bean
public JpaItemWriter<WeatherData> optimizedWriter() {
JpaItemWriter<WeatherData> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
// 배치 삽입 최적화
return writer;
}📖 추천 학습 리소스
공식 문서:
- Spring Batch Reference Documentation
- Spring Boot Batch 가이드
실습 프로젝트 아이디어:
- 로그 파일 분석 배치: 웹 서버 로그 파싱 및 통계 생성
- 데이터 마이그레이션 배치: Legacy 시스템에서 신규 시스템으로 데이터 이전
- 리포트 생성 배치: 일간/주간/월간 리포트 자동 생성
- 데이터 정제 배치: 중복 데이터 제거, 데이터 품질 향상
이 가이드를 통해 현재 시스템을 완전히 이해하고 자신만의 배치 시스템으로 확장할 수 있습니다.
..