
깊이 우선 탐색(DFS), 너비 우선 탐색(BFS)를 배우기 전에 스택, 큐 자료구조와 재귀 함수에 대해 공부해야 한다.
스택(stack), 큐(queue) 자료구조
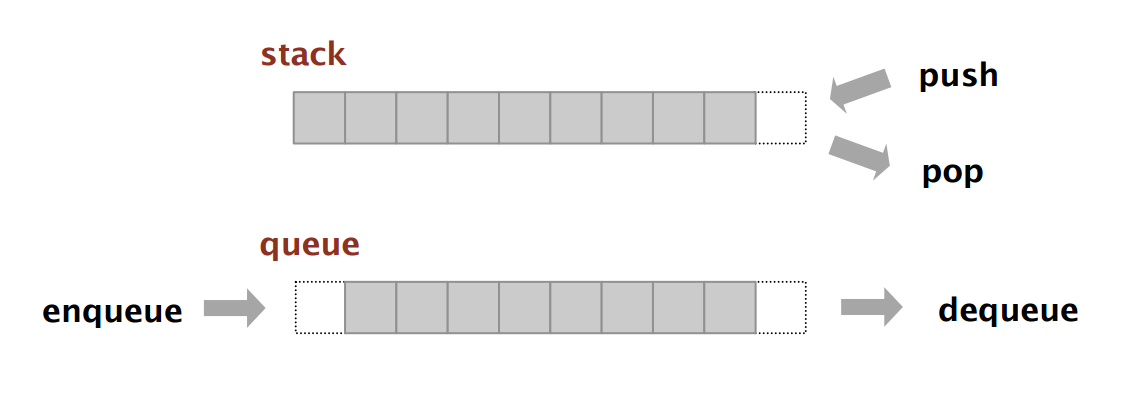
스택(stack)
- 선입후출 : 먼저 들어온 데이터가 나중에 나가는 형식의 자료 구조
- 삽입(insert)과 삭제(delete) 연산이 있는데 삽입하면 제일 끝에 쌓이고, 삭제하면 제일 뒤에 있는 데이터부터 삭제된다.
스택 코드 예시:
stack = ["Amar", "Akbar", "Anthony"]
stack.append("Ram")
stack.append("Iqbal")
print(stack)
# Removes the last item
print(stack.pop())
print(stack)
# Removes the last item
print(stack.pop())
print(stack)출력:
['Amar', 'Akbar', 'Anthony', 'Ram', 'Iqbal']
Iqbal
['Amar', 'Akbar', 'Anthony', 'Ram']
Ram
# 최종 리스트
['Amar', 'Akbar', 'Anthony']이와 같이 스택은 àppend()으로 자료를 리스트 마지막에 추가할 수도 있고, .pop()으로 마지막 항목을 삭제할 수도 있다.
큐(queue)
- 선입선출 : 먼저 들어 온 데이터가 먼저 나가는 형식의 자료 구조
- 큐도 삽입(insert)과 삭제(delete) 연산이 있다. 삽입하면 제일 끝에 쌓이고, 삭제하면 제일 앞에 있는 데이터부터 삭제된다.
- 파이썬에서는 리스트보다 deque를 이용하는게 (시간 복잡도로 봐도)효율적이기 때문에 deque를 쓰는게 좋다.
큐 코드 예시(리스트):
queue = ["Amar", "Akbar", "Anthony"]
queue.append("Ram")
queue.append("Iqbal")
print(queue)
# Removes the first item
print(queue.pop(0))
print(queue)
# Removes the first item
print(queue.pop(0))
print(queue) 출력:
['Amar', 'Akbar', 'Anthony', 'Ram', 'Iqbal']
Amar
['Akbar', 'Anthony', 'Ram', 'Iqbal']
Akbar
['Anthony', 'Ram', 'Iqbal']큐 코드 예시(deque):
from collections import deque
queue = deque(["Ram", "Tarun", "Asif", "John"])
print(queue)
queue.append("Akbar")
print(queue)
queue.append("Birbal")
print(queue)
print(queue.popleft())
print(queue.popleft())
print(queue) 출력:
deque(['Ram', 'Tarun', 'Asif', 'John'])
deque(['Ram', 'Tarun', 'Asif', 'John', 'Akbar'])
deque(['Ram', 'Tarun', 'Asif', 'John', 'Akbar', 'Birbal'])
Ram
Tarun
deque(['Asif', 'John', 'Akbar', 'Birbal'])큐 또한 append()로 자료를 리스트 마지막에 추가하고, .popleft()으로 맨 앞에 있는 항목부터 지울 수 있다.
재귀함수(Recursive functions)
자기 자신을 다시 호출하는 함수를 의미한다. 재귀함수는 함수 안에서 함수 본인을 실행하여 반복하는 방법이며 파이썬 함수는 자기 자신을 함수 안에서 호출할 수 있다.
탐색 알고리즘은 스택 대신 재귀함수를 이용해서 구현하는 경우가 많다. 파이썬에서는 재귀함수 호출의 깊이 제한이 있기 때문에 신경써서 코드를 짜야한다. 재귀함수 사용 시 종료 조건을 반드시 명시해야 하나 다른 사람이 이해하기 어려운 형태의 코드가 될 수 있으므로 신중하게 사용해야 한다.
error 예시:
함수 실행
함수 실행
...
함수 실행
RecursionError: maximum recursion depth exceeded while calling a Python object탐색 알고리즘
자료 탐색은 많은 양의 데이터 틈에서 우리가 원하는 자료를 찾는 작업을 말한다.이와 같은 자료 탐색이 더 효율적으로, 효과적으로 이루어지기 위해 우리는 잘 설계된 '탐색 알고리즘'을 적용해야 한다.
탐색 알고리즘의 가장 원초적인 방법으로 깊이 우선 탐색(DFS), 너비 우선 탐색(BFS)이 있다. 둘은 자료 하나하나 다 확인하기 때문에 효율적이지 않다. 자료 하나씩 확인하는 작업은 무식하고 효과적이지 않기 때문에 현실에서는 쓰이지 않는다.
그래프
그래프는 정점(vertex)아 간선(Edge)으로 이루어져 있다. 간선을 통해 모든 정점을 방문하는 것을 그래프 탐색이라고 한다.
인접 행렬과 인접 리스트
-
인접 리스트 : 그래프 상태를 나타내는 정사각행렬, 그래프의 정점이 n개 일 때, 그래프의 표현은 n * n의 이차원 배열로 나타낼 수 있음
-
인접 행렬 : 한 정점과 연결되어 있는 모든 정점들을 하나의 연결리스트로 표현하는 방식이다. 그래프의 각 정점마다 해당 정점에서 나가는 간선의 목록을 저장하려 표현한다. 인접 행렬에 비해 변이 적은 그래프에 유용하다.
DFS, BFS?
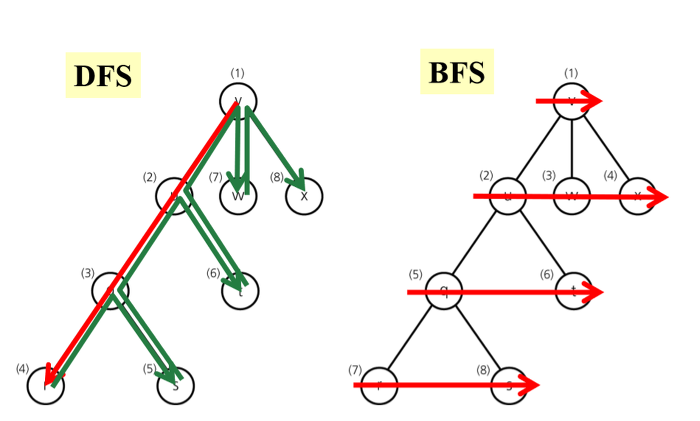
DFS(깊이 우선 탐색)
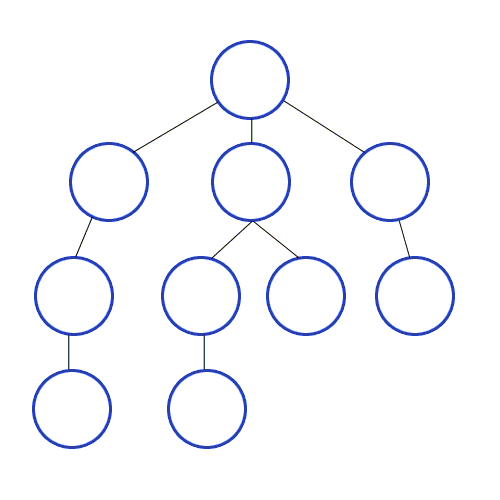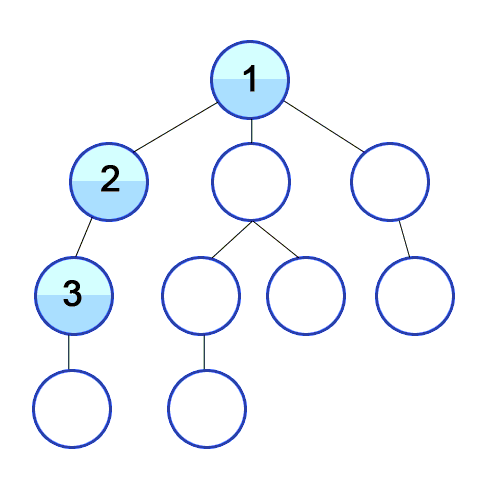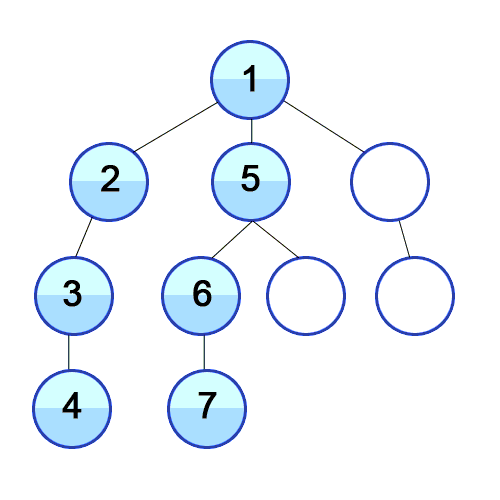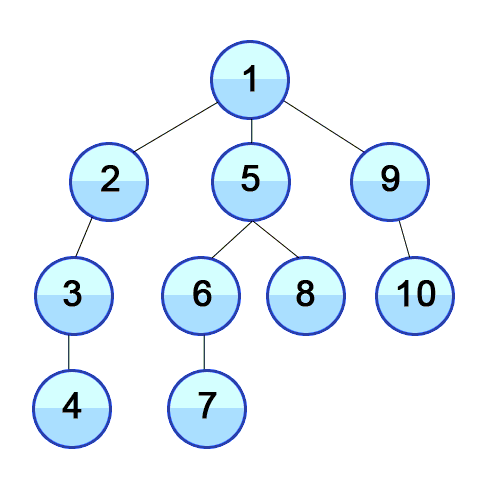
루트 노드(또는 다른 임의의 노드)에서 시작해서 다음 branch로 넘어가기 전에 해당 분기를 완벽히 탐색하는 방식이다. 스택 배열 혹은 재귀 호출로 구현하며 모든 노드를 방문하는 경우 이 방법을 택한다.
한 우물만 깊게 파서 끝을 보는 탐색이라고 보면 편하다. DFS는 한단계에서 pop과 expand 두가지 일을 동시에 처리한다.
- pop : 스택의 맨 위 노드를 꺼내는 일
- expand : pop으로 노드를 지우면서 그 노드의 자식을 모두 스택에 넣는 일. 자식이 없다면 아무것도 안 넣는다.
장점:
- 현 경로상의 노드만 기억하면 되므로 저장 공간들 적게 차지한다
- 목표 노드가 깊은 단계에 있으면 답을 빨리 구할 수 있다
단점:
- 답이 없는 경로에 깊이 빠질 수 있다. 깊이제한(Depth Bound)를 지정해 해당 깊이까지만 탐색하고, 목표 노드를 발견하지 못하면 다음 경로에 따라 탐색하는 방식이 좋다
- 얻은 답이 최단 경로가 아닐 수 있다. 목표까지의 경로가 다수인 경우 탐색이 답을 찾으면 탐색을 끝내기 때문이다.
시간 복잡도(접점(V), 간선(E)):
- 인접 리스트 : O(V + E)
- 인접 행렬 : O(V^2)
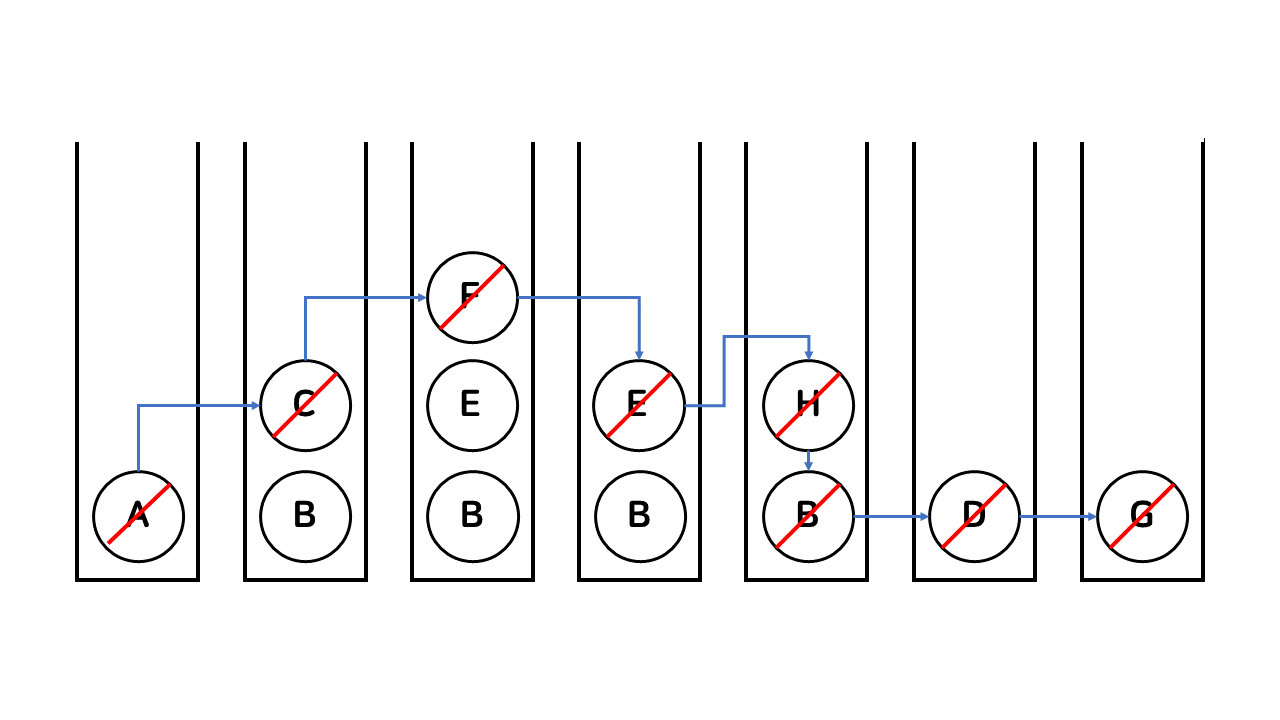
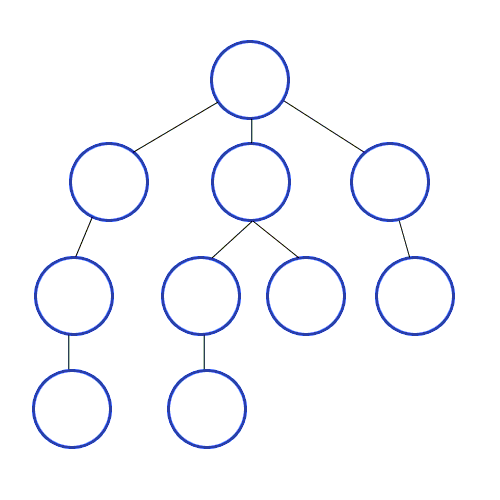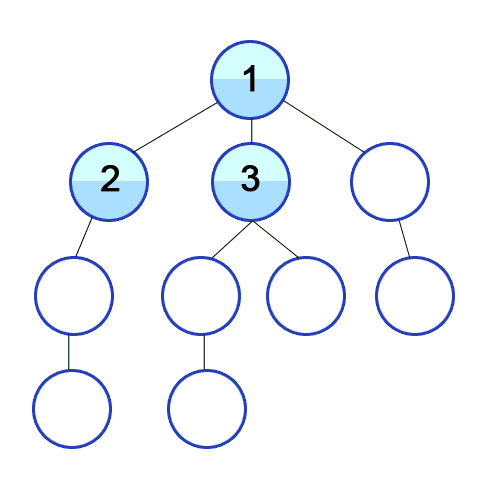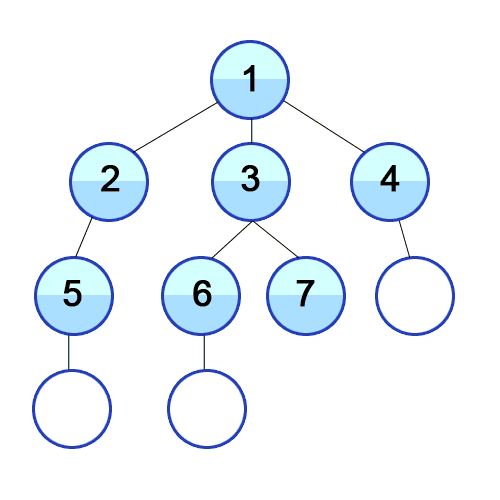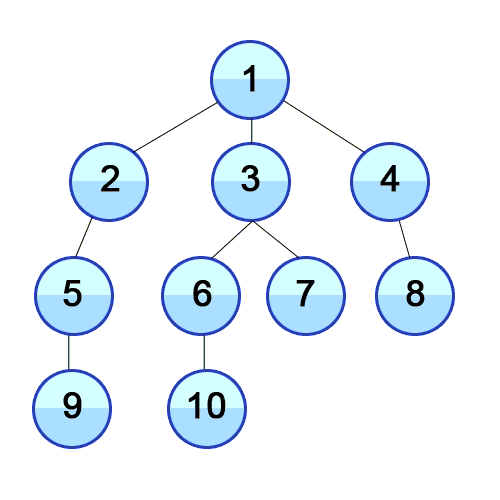
- 루트 노드인 A를 스택에서 push하고 visited으로 표시
- A를 pop하고 A의 자식노드인 B,C를 순서대로 스택에 push
- 스택은 선입후출이기 때문에 그림과 같이 top의 위치에 있는 노드들이 우선적으로 탐색되게 함
- 따라서 DFS는 시작 노드를 시작으로 인접 노드를 스택에 가져와 선입후출을 처리한다
graph_list = {1: set([3, 4]),
2: set([3, 4, 5]),
3: set([1, 5]),
4: set([1]),
5: set([2, 6]),
6: set([3, 5])}
root_node = 1def DFS_with_adj_list(graph, root):
visited = []
stack = [root]
while stack:
n = stack.pop()
if n not in visited:
visited.append(n)
stack += graph[n] - set(visited)
return visited
print(BFS_with_adj_list(graph_list, root_node))BFS(깊이 우선 탐색)
BFS(너비 우선 탐색)은 시작 정점을 방문 --> 시작 정점에 인접한 모든 정점을 방문 --> 시작 정점에 인접한 모든 정점들을 우선 방문하는 방법이다. 첫번째 수에서 가능한 모든 것을 확인하고 주번째 수에서 가능한 모든 것을 확인하고, 이렇게 한 수 한 수 전부 확인하고 천천히 깊어지는 탐색 방식이다. 큐를 이용해 구현한다.
BFS도 pop, expand 과정을 똑같이 한다. 그러나 BFS는 큐 자료구조를 사용하기 때문에 맨 앞에서 꺼내야 한다. 따라서 pop 대신 dequeue라는 용어를 사용한다(노드를 넣는 것은 enqueue 라고 한다)
- dequeue : 큐에서 맨 앞에 있는 노드 꺼낸다
- expand : dequeue로 노드를 지우면서 그 노드의 자식을 모두 큐에 넣는다. 자식이 없다면 아무것도 넣지 않는다.
장점:
- 출발 노드에서 목표 노드까지의 최단 길이 경로를 보장한다
단점:
- 경로가 매우 길 경우 탐색 가지가 급격히 증가하며 저장 공간이 많이 필요하다
- 답이 존재하지 앟는 그래프는 탐색 후 실패로 끝난다.
- 무한 그래프의 경우 끝낼 수 없다
시간 복잡도(접점(V), 간선(E)):
- 인접 리스트 : O(V + E)
- 인접 행렬 : O(V^2)

graph_list = {1: set([3, 4]),
2: set([3, 4, 5]),
3: set([1, 5]),
4: set([1]),
5: set([2, 6]),
6: set([3, 5])}
root_node = 1from collections import deque
def BFS_with_adj_list(graph, root):
visited = []
queue = deque([root])
while queue:
n = queue.popleft()
if n not in visited:
visited.append(n)
queue += graph[n] - set(visited)
return visited
print(BFS_with_adj_list(graph_list, root_node))Reference:
https://jeinalog.tistory.com/18
https://velog.io/@jiffydev/%EC%9D%B4%EB%A1%A0%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-DFS-BFS
https://boysboy3.tistory.com/157
https://wanna-b.tistory.com/64
https://devuna.tistory.com/32
https://developer-mac.tistory.com/64
https://mygumi.tistory.com/102
