
[SQLD 시험 대비] 2과목. SQL 기본 및 활용 : 3장. SQL 최적화 기본 원리 - 2. 인덱스 기본
인덱스 특징과 종류
- 인덱스는 테이블을 기반으로 선택적으로 생성할 수 있는 구조이다.
- 테이블에 인덱스를 생성 하지 않아도 되고 여러 개를 생성해도 된다.
- 인덱스의 기본적인 목적은 검색 성능의 최적화 이다.
- 즉, 검색 조건을 만족하는 데이터를 인덱스를 통해 효과적으로 찾을 수 있도록 돕는다.
- 하지만 Insert, Update, Delete 등과 같은 DML 작업은 테이블과 인덱스를 함께 변경 해야 하기 때문에 오히려 느려질 수 있다는 단점이 존재한다.
트리 기반 인덱스
- DBMS에서 가장 일반적인 인덱스는 B-트리 인덱스이다.
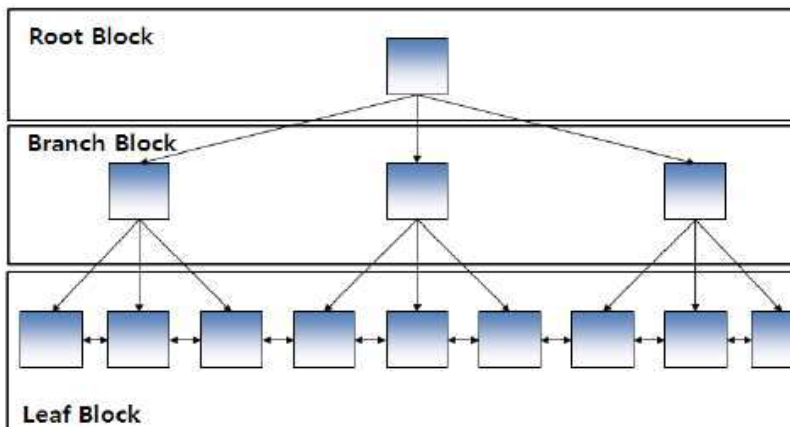
- B-트리 인덱스는 브랜치 블록(Branch Block)과 리프 블록(Leaf Block)으로 구성된다.
- 브랜치 블록은 분기를 목적으로 하는 블록이다.
- 브랜치 블록은 다음 단계의 블록을 가리키는 포인터를 가지고 있다.
- 브랜치 블록 중에서 가장 상위에서 있는 블록을 루트 블록(Root Block)이라고 한다.
- 리프 블록은 트리의 가장 아래 단계에 존재한다.
- 브랜치 블록은 분기를 목적으로 하는 블록이다.
- 리프 블록은 인덱스를 구성하는 칼럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자(RID, Record Identifier/Rowid)로 구성되어 있다.
- 인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬된다.
- 만약 인덱스 데이터의 값이 동일하면 레코드 식별자의 순서로 저장된다.
- 리프 블록은 양방향 링크(Double Link)를 가지고 있다. 이것을 통해서 오름 차순(Ascending Order)과 내림 차순(Descending Order) 검색을 쉽게 할 수 있다.
- B-트리 인덱스는 ‘=’로 검색하는 일치(Exact Match) 검색과 ‘BETWEEN’, ‘>’ 등과 같은 연산자로 검색하는 범위(Range) 검색 모두에 적합한 구조이다.
- 인덱스를 생성할 때 동일 칼럼으로 구성된 인덱스를 중복해서 생성할 수 없다.
- 인덱스 구성 칼럼은 동일하지만 칼럼의 순서가 다르면 서로 다른 인덱스로 생성할 수 있다.
- Oracle에서 트리 기반 인덱스에는 B-트리 인덱스 외에도 비트맵 인덱스(Bitmap Index), 리버스 키 인덱스(Reverse Key Index), 함수기반 인덱스(FBI, Function-Based Index) 등 이 존재한다.
SQL Server의 클러스터형 인덱스
- SQL Server의 인덱스 종류는 저장 구조에 따라 클러스터형(clustered) 인덱스와 비클러 스터형(nonclustered) 인덱스로 나뉜다.
- 클러스터형 인덱스는 두 가지 중요한 특징이 있다.
- 인덱스의 리프 페이지가 곧 데이터 페이지다.
- 테이블 탐색에 필요한 레코드 식별자가 리프 페이지에 없다
- 클러스터형 인덱스의 리프 페이지를 탐색 하면 해당 테이블의 모든 칼럼 값을 곧바로 얻을 수 있다.
- 리프 페이지의 모든 로우(=데이터)는 인덱스 키 칼럼 순으로 물리적으로 정렬되어 저장된다.
- 테이블 로우는 물리적으로 한 가지 순서로만 정렬될 수 있다.
- 인덱스의 리프 페이지가 곧 데이터 페이지다.
전체 테이블 스캔과 인덱스 스캔
전체 테이블 스캔
- 테이블에 존재하는 모든 데이터를 읽 어 가면서 조건에 맞으면 결과로서 추출하고 조건에 맞지 않으면 버리는 방식으로 검색한 다.

- Oracle의 경우 검색 조건에 맞는 데이터를 찾기 위해서 테이블의 고수위 마크(HWM, High Water Mark) 아래의 모든 블록을 읽는다.
- 고수위 마크는 테이블에 데이터가 쓰여졌던 블록 상의 최상위 위치를 의미한다.
- 전체 테이블 스캔 방식으로 데이터를 검색할 때 고수위 마크까지의 블록 내 모든 데이터를 읽어야 하기 때문에 모든 결과를 찾을 때까지 시간이 오래 걸릴 수 있다.
옵티마이저가 연산으로서 전체 테이블 스캔 방식을 선택하는 이유는 일반적으로 다음과 같다.
- SQL문에 조건이 존재하지 않는 경우
- SQL문에 조건이 존재하지 않는다는 것은 테이블에 존재하는 모든 데이터가 답이 된다는 것이다.
- 그렇기 때문에 테이블의 모든 블록을 읽으면서 무조건 결과로서 반환하면 된다.
- SQL문의 주어진 조건에 사용 가능한 인덱스가 존재하는 않는 경우
- 사용 가능한 인덱스가 존재하지 않는다면 데이터를 액세스할 수 있는 방법은 테이블의 모든 데이터를 읽으면서 주어진 조건을 만족하는지를 검사하는 방법뿐이다.
- 또한 주어진 조건에 사용 가능한 인덱스는 존재하나 함수를 사용하여 인덱스 칼럼을 변형한 경우에도 인덱스를 사용할 수 없다.
- 옵티마이저의 취사 선택
- 조건을 만족하는 데이터가 많은 경우, 결과를 추출하기 위해서 테이블의 대부분의 블록을 액세스해야 한다고 옵티마이저가 판단하면 조건에 사용 가능한 인덱스가 존재해도 전체 테이블 스캔 방식으로 읽을 수 있다.
- 그 밖의 경우
- 병렬처리 방식으로 처리하는 경우 또는 전체 테이블 스캔 방식의 힌트를 사용한 경우에 전체 테이블 스캔 방식으로 데이터를 읽을 수 있다.
인덱스 스캔
- 인덱스 스캔은 인덱스를 구성하는 칼럼의 값을 기반으로 데이터를 추출하는 액세스 기법이다.
- 인덱스의 리프 블록은 인덱스 구성하는 칼럼과 레코드 식별자로 구성되어 있다.
- 따라서 검색을 위해 인덱스의 리프 블록을 읽으면 인덱스 구성 칼럼의 값과 테이블의 레코드 식별자를 알 수 있다.
- 인덱스에 존재하지 않는 칼럼의 값이 필요한 경우에는 현재 읽은 레코드 식별자를 이용하여 테이블을 액세스해야 한다.
인덱스 스캔 중에서 자주 사용되는 세가지 스캔 방식을 소개하겠다.
- 인덱스 유일 스캔
- 유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출 하는 방식이다.
- 유일 인덱스는 중복을 허락하지 않는 인덱스이다.
- 유일 인덱스 구성 칼럼 에 모두 '='로 값이 주어지면 결과는 최대 1건이 된다. 인덱스 유일 스캔은 유일 인덱스 구성 칼럼에 대해 모두 ‘=’로 값이 주어진 경우에만 가능한 인덱스 스캔 방식이다.
- 인덱스 범위 스캔
- 인덱스를 이용하여 한 건 이상의 데이터를 추출하는 방식이다.
- 유일 인덱스의 구성 칼럼 모두에 대해 ‘=’로 값이 주어지지 않은 경우와 비유일 인덱스 (Non-Unique Index)를 이용하는 모든 액세스 방식은 인덱스 범위 스캔 방식으로 데이터를 액세스하는 것이다.
- 인덱스 역순 범위 스캔
- 인덱스의 리프 블록의 양방향 링크를 이용하여 내림 차순으로 데이터를 읽는 방식
- 이 방식을 이용하여 최대 값(Max Value)을 쉽게 찾을 수 있다. 이 또한 인덱스 범위 스캔의 일종이다.
- 이외에도 인덱스 전체 스캔(Index Full Scan), 인덱스 고속 전체 스캔(Fast Full Index Scan), 인덱스 스킵 스캔(Index Skip Scan) 등이 존재한다.
전체 테이블 스캔과 인덱스 스캔 방식의 비교

- 인덱스 스캔 방식은 사용 가능한 적절한 인덱스가 존재할 때만 이용할 수 있는 스캔 방식이지만 전체 테이블 스캔 방식은 인덱스의 존재 유무와 상관없이 항상 이용 가능한 스캔 방식이다.
- 인덱스 스캔은 인덱스에 존재하는 레코드 식별자를 이용해서 검색하는 데이터의 정확한 위치를 알고서 데이터를 읽는다.
- 그렇기 때문에 인덱스 스캔 방식에서는 불필요하게 다른 블 록을 더 읽을 필요가 없다. 따라서 한번의 I/O 요청에 한 블록씩 데이터를 읽는다.
- 그러나 전체 테이블 스캔은 데이터를 읽을 때 한번의 I/O 요청으로 여러 블록을 한꺼번에 읽는다.

코드로 꿈을 펼치는 개발자의 이야기, 노력과 열정이 가득한 곳 🌈