비절차적 언어로 유저가 원하는 데이터만 지정한다. 처리 순서가 중하지 않다.
SQL은 natural language 같은 문장을 사용해 쿼리를 표현할 수 있다.
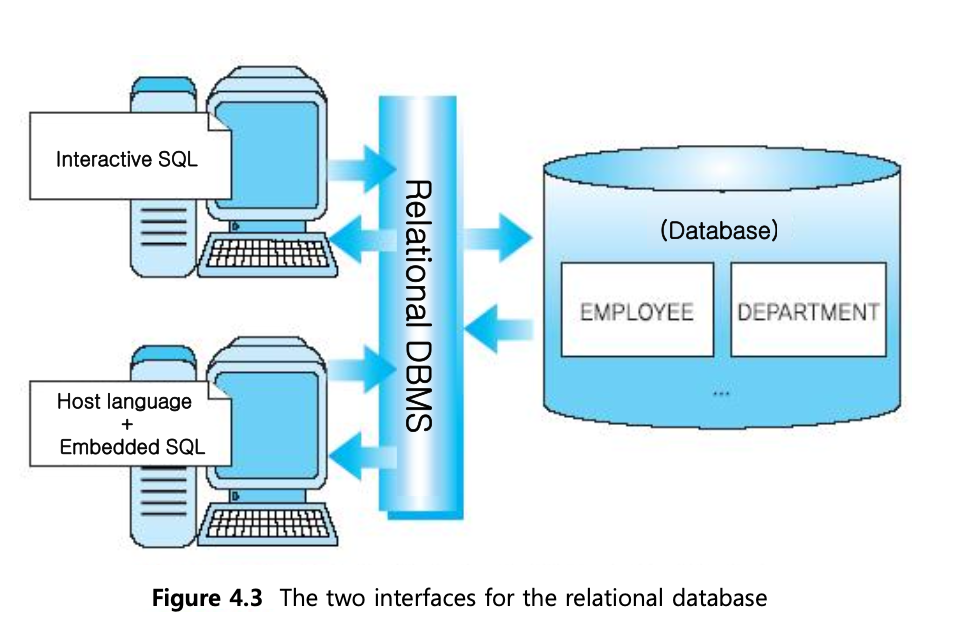
Interactive SQL / Embedded SQL로 나뉜다.
DDL과 무결성 제한조건
Definition
DDL : Data Definition Language

스키마 생성(CREATE) 및 삭제(DROP)

끝날 땐 세미콜론, 외래키는 references, 괄호 여닫는 부분 등등
pk들은 NOT NULL.(entity integrity constraint)
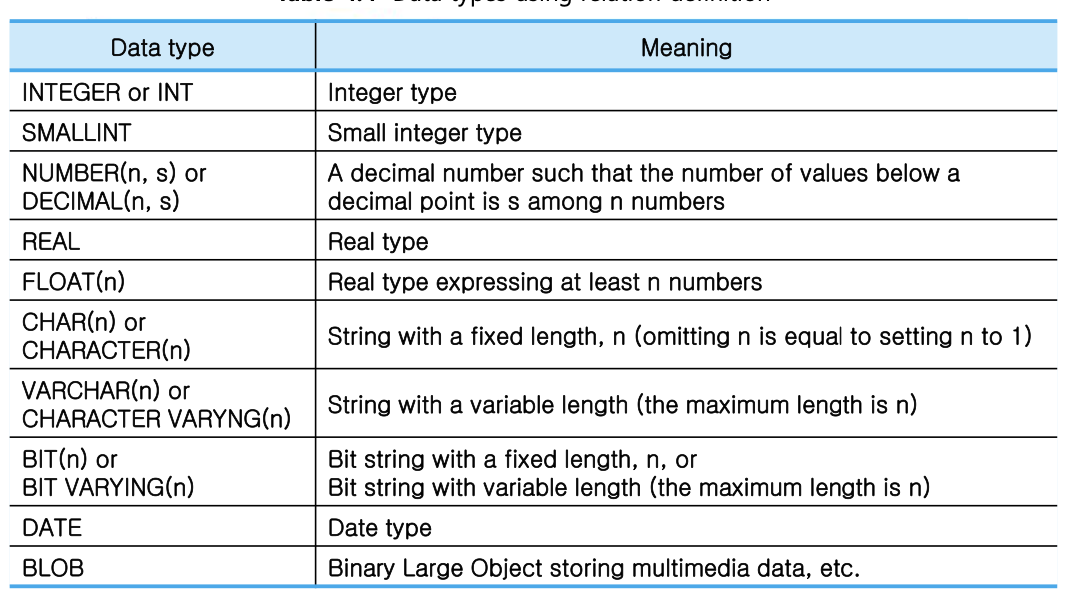
데이터 타입.
BLOB: 멀티미디어 타입. (예: 사진?)
Constraints

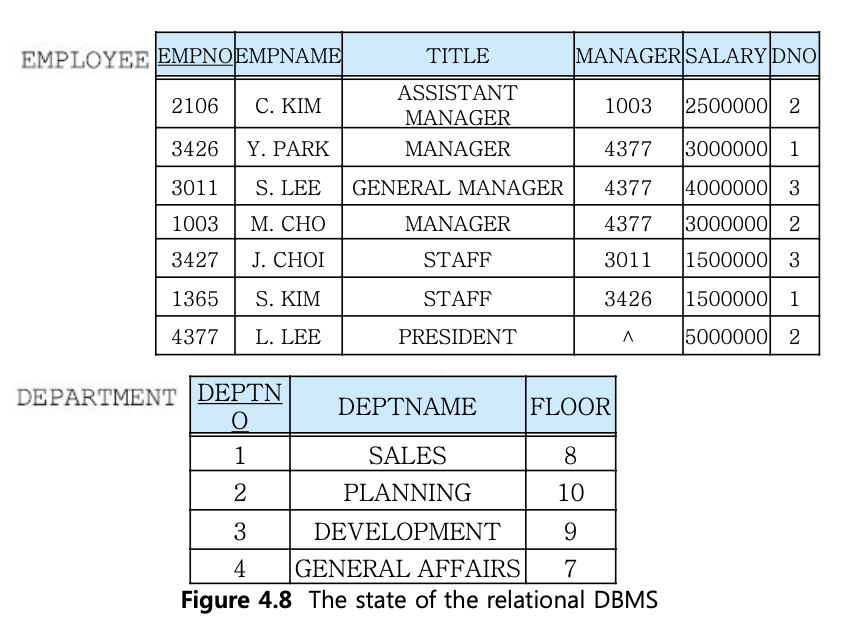
DNO: 1~4 중에 있는지. 디폴트는 1. 삭제시 디폴트로 set. 수정시 cascade.

참조 무결성 제한조건. 삭제 수정시 액션이 없거나, 캐스케이드거나, 널로 세팅하거나, 디폴트로 세팅하거나 등
Cascade


3번 부서를 6번으로 업데이트할 때, 직원테이블에서 3번 부서에서 일하는 모든 직원들의 부서 번호를 자동으로 6번으로 수정한다.
SELECT
관계형 DBMS에서 가장 많이 쓰임.

SELECT: 애트리뷰트를 선택.
FROM: 어떤 테이블로부터.
WHERE: 조건.
distinct: 중복제거 키워드. select로 DB에서 컬럼을 조회할 떄, 중복값을 추린다.
nested query: 중첩 질의. where에 또다른 select/from/where가 올 수 있다.
GROUP BY: 테이블 튜플들을 grouping하기 위해 사용. 해당 절은 각 그룹에 대해 하나의 행을 만드는데 이 과정을 aggregation이라 함. GROUP BY는 주로 aggregate function(COUNT, MAX, MIN, SUM, AVG)와 쓰임.
HAVING: group by에 대한 조건절.
ORDER BY: 정렬. 디폴트는 ascending(오름차순).
1) Seaching for attribute

select * from DEPARTMENT;*: 모든 attribute를 셀렉한다는 의미.

select DEPTNO, DEPTNAME from DEPARTMENT;2) DISTINCT

중복제거 키워드 안 쓸 경우.
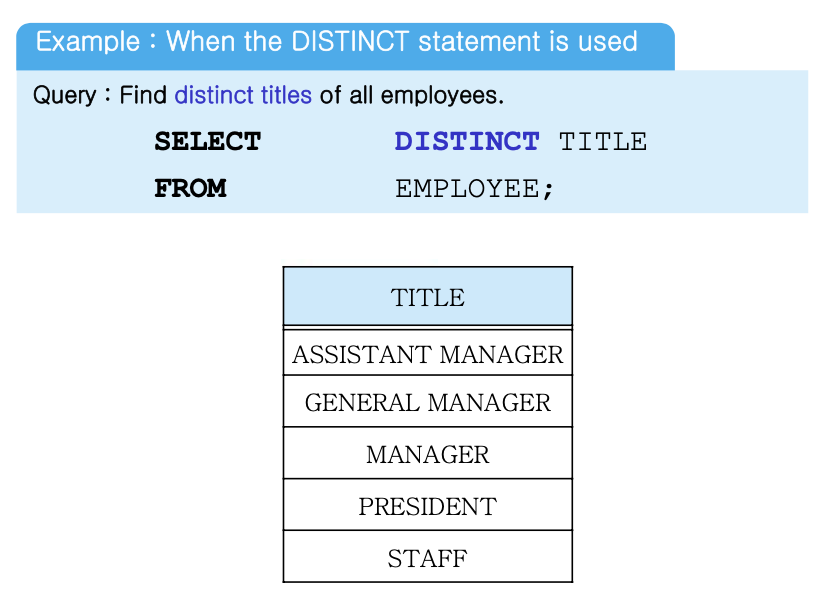
중복 없이(distinct) title 애트리뷰트를 검색.
3) WHERE statement

select *
from EMPLOYEE
where DNO = 2;4) String comparison

select EMPNAME, TITLE, DNO
from EMPLOYEE
where EMPNAME like '%LEE';5) Multiple search

select EMPNAME, SALARY
from EMPLOYEE
where DNO = 1 and TITLE = 'MANAGER';
select EMPNAME,
from EMPLOYEE
where DNO <> 1 and TITLE = 'MANAGER';
select EMPNAME, TITLE, SALARY
from EMPLOYEE
where SALARY between 3000000 and 4500000;select EMPNAME, TITLE, SALARY
from EMPLOYEE
where SALARY >= 3000000 and SALARY <= 4500000;Between and: 마찬가지로 multiple condition이다.
Wrong case
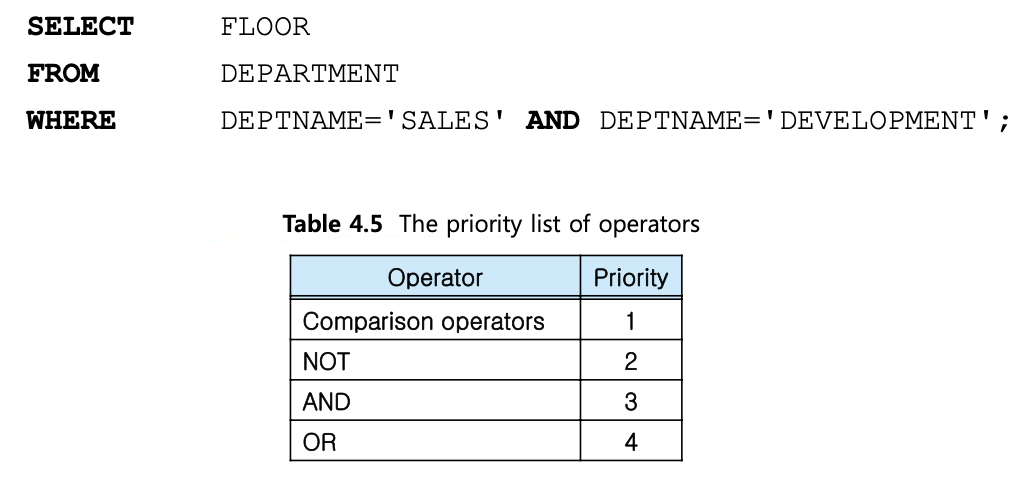
판매 부서이면서 개발 부서일 수 없다.
AND -> OR
6) list

select *
from EMPLOYEE
where DNO in (1, 3);in 명령어.
OR 대신 사용한다.
7) Arithmetic oprators in SELECT

select EMPNAME, SALARY, SALARY*1.1 as NEWSAL
from EMPLOYEE
where TITLE = 'MANAGER';셀렉에서 연산 가능함.
8) NULL value
- NULL과 다른 값들 간의 연산 결과는 NULL이다.
- Aggregate fuction은 COUNT, MAX, SUM 등 다양하다. 널은 무시한다.
- 단 한 가지 예외.
COUNT(*)는 NULL을 카운트한다.
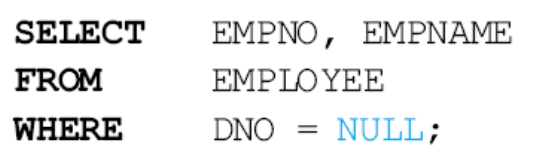
이렇게 어떤 애트리뷰트가 NULL인지 아닌지 검색하면 안 된다.

NULL = NULL 이것도 틀림. NULL != NULL(NULL <> NULL) 이것도 틀림.

쓸 거면 이렇게 쓰자.
=이 아니라 is
9) ORDER BY

select SALARY, TITLE, EMPNAME
from EMPLOYEE
where DNO = 2
group by SALARY;디폴트는 ASC다.
NULL은 정렬에서만큼은 어떤 수보다 큰 수로 생각하면 편하다. ASC에서는 가장 끝에. DESC에서는 가장 앞에 정렬된다.
10) Aggregate function

select AVG(SALARY) AVGSAL, MAX(SALARY) MAXSAL
from EMPLOYEE;11) Grouping
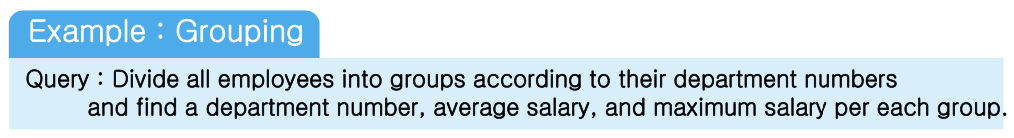
select DNO, AVG(SALARY) AVGSAL, MAX(SALARY) MAXSAL
from EMPLOYEE
group by DNO;wrong query

EMPLOYEE 테이블의 모든 직원 급여에 대한 평균을 찾는다. 그런데 GROUP BY 없이 찾고 있다.
12) HAVING
Group by에 대한 조건.
(SELECT에 대한 조건은 WHERE)

select DNO, AVG(SALARY) AVGSAL, MAX(SALARY) MAXSAL
from EMPLOYEE
group by DNO
having AVG(SALARY) > 2500000;13) Set operation
집합 연산. ex) union, intersect

(select DNO
from EMPLOYEE
where EMPNAME = 'C.KIM');
union
(select DEPTNO
from DEPARTMENT
where DEPTNAME = 'DEVELOPMENT');