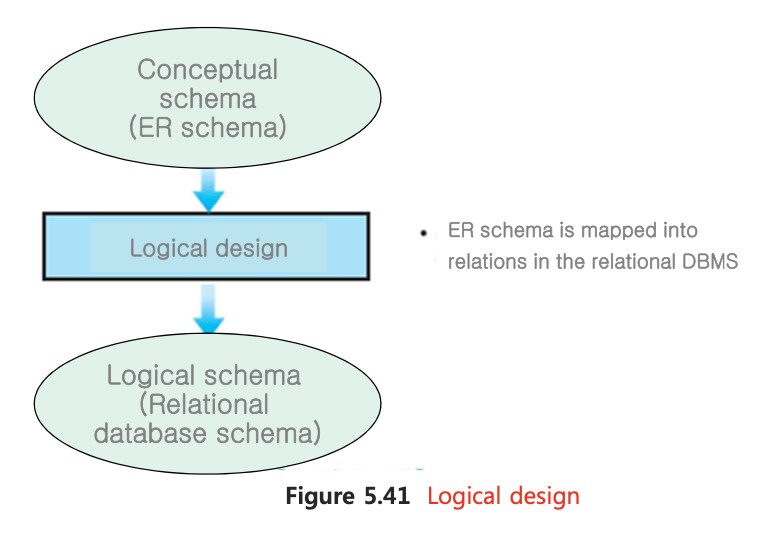
논리적 디자인 단계에서 ER model은 데이터베이스 스키마로 매핑된다.
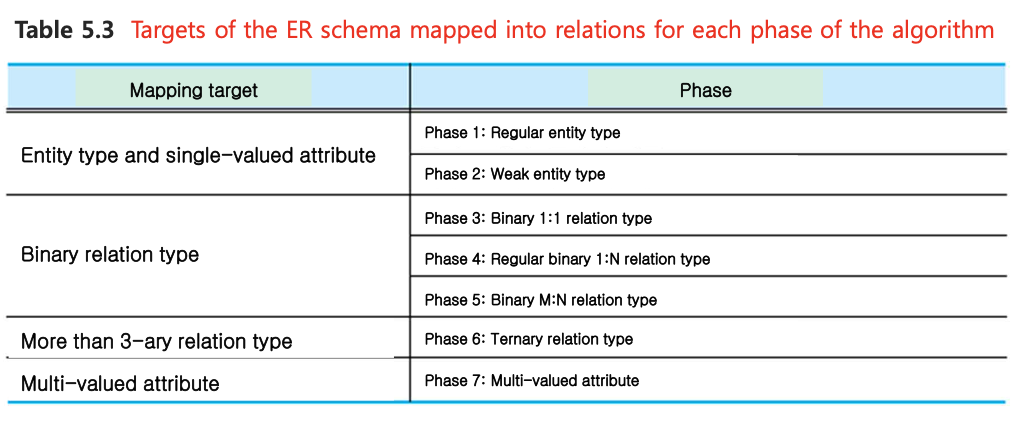
논리적 디자인 매핑에 7단계가 있다.
1. 일반 엔티티 타입(SVA)
2. Weak 엔티티 타입(SVA)
3. 1:1 관계 타입
4. 1:N 관계 타입
5. M:N 관계 타입
6. Degree가 3이상의 관계 타입
7. MVA 타입
📌 1. Regular entity type
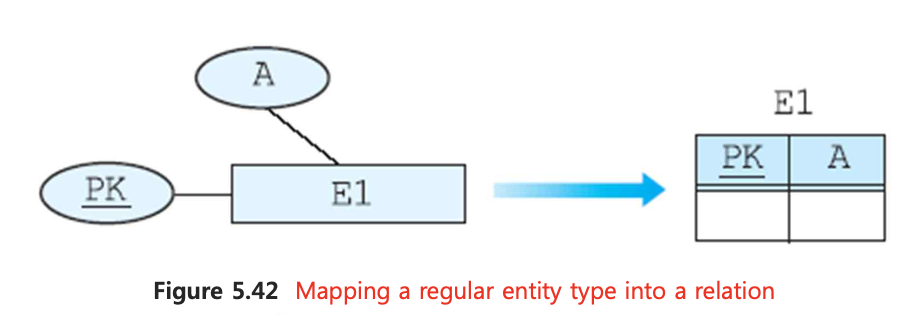
엔티티의 simple attribute들을 테이블에 포함한다. composite attribute 내 simple attribute도 매핑한다.
엔티티의 pk는 테이블의 pk로 고대로 매핑한다.
📌 2. Weak entity type
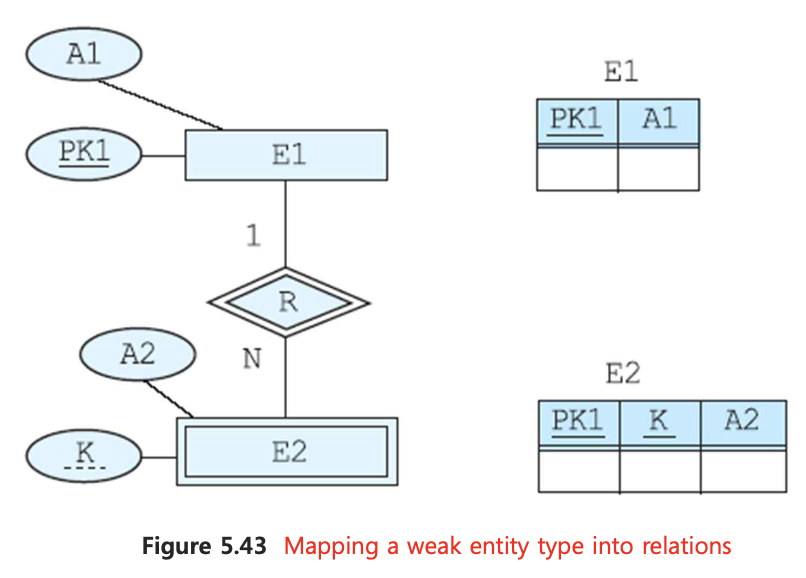
weak 엔티티의 simple attribute들을 테이블에 포함한다.
owner 엔티티의 pk를 weak 엔티티의 fk로 매핑한다.
생성된 테이블의 pk는 weak 엔티티의 partial key + owner 엔티티의 foreign key로 구성한다.
📌 3. 1:1 관계
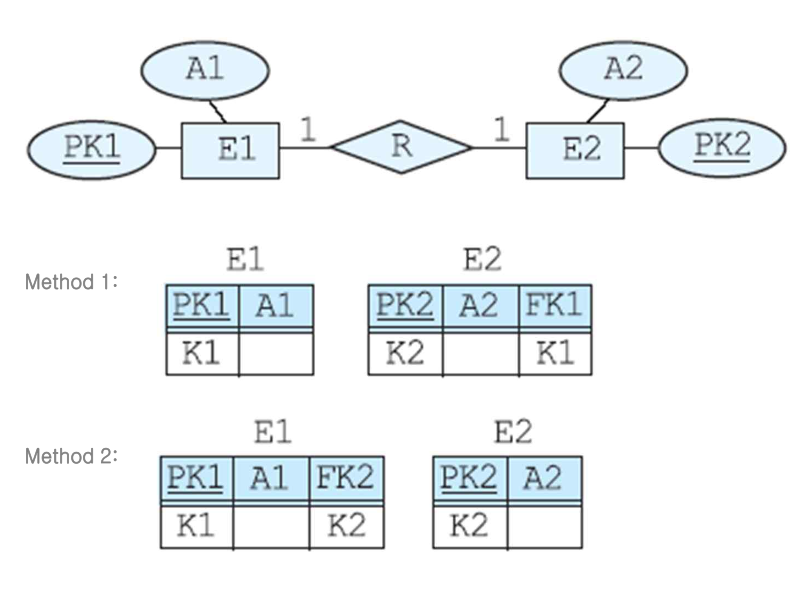
E1, E2 중 어떤 테이블에 외래키를 포함시킬지 고민해야 한다.
relation 상에서 전체 참여인 테이블에 외래키를 주는 게 좋다.
📌 4. 1:N 관계
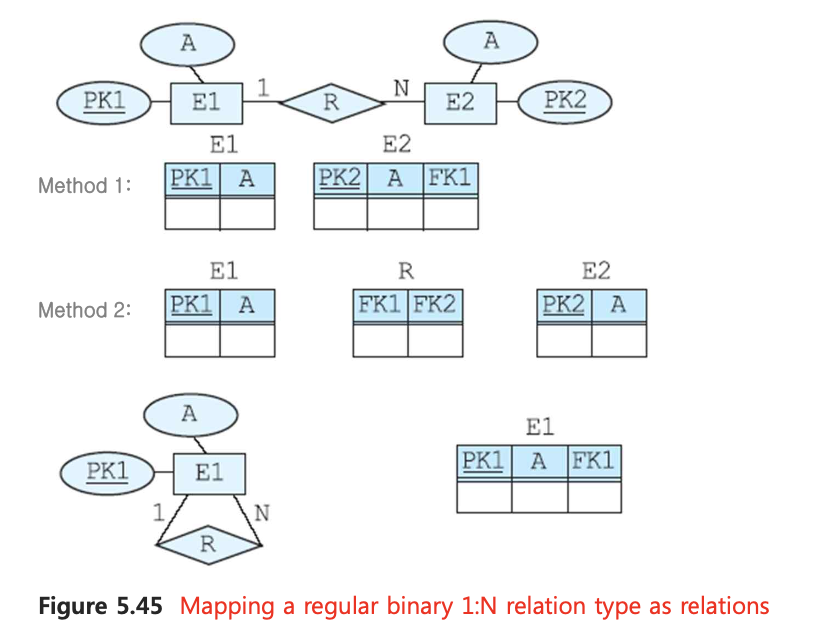
1:N 관계에서 1에 해당하는 E1, N에 해당하는 E2가 있을 때, E1의 pk가 E2의 외래키에 들어간다.
E2에 외래키를 넣을 경우, 상당한 중복이 발생한다. 직원과 부서 테이블이 있다고 가정할 때, 부서와 직원은 N:1관계일 것이다. 부서 테이블에 직원의 pk를 참조한다면, 부서에 속한 직원의 수만큼씩 중복이 발생할 것이다.
📌 5. M:N 관계
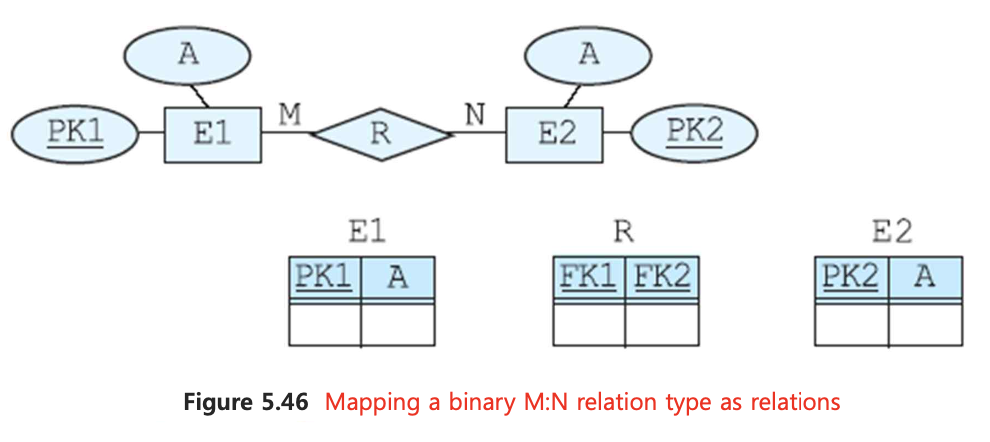
M:N일 경우, 어느 테이블에 외래키를 주더라도 중복을 피할 수 없다.
join을 한 번 더 하더라도 ER schema 상에서 relation을 새로운 테이블로 만들어 양 측 pk를 모두 받아온다.
📌 6. Degree가 3이상 relation type
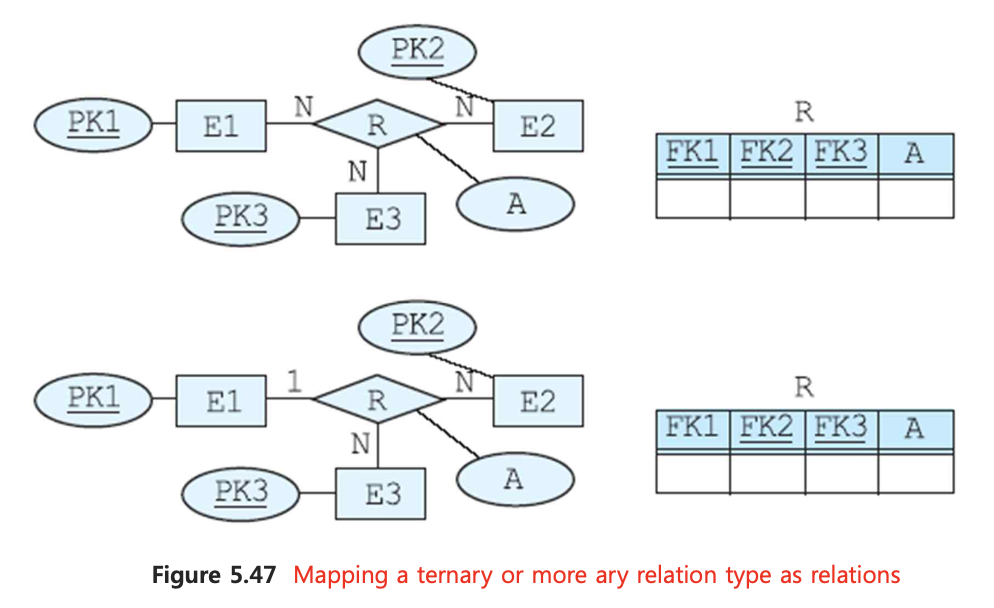
R에 참여하는 엔티티의 모든 기본키를 R테이블의 외래키로 포함한다.
R이 애트리뷰트를 가지고 있다면 그 애트리뷰트는 R테이블에 포함한다.
R테이블의 기본키는 외래키의 집합이다.
1:N:N의 관계라면, N측에 속한 외래키만을 집합으로 하여 기본키를 구성한다.
- E1 엔티티 타입의 엔티티가 관계에 참여할 경우 N가지의 E2, N가지의 E3 경우의 수가 있다.
- E2 엔티티 타입의 엔티티가 관계에 참여할 경우 1가지의 E1, N가지의 E3 경우의 수가 있다.
- E3 엔티티 타입의 엔티티가 관계에 참여할 경우 1가지의 E1, N가지의 E2 경우의 수가 있다.
E2와 E3가 결정되면 E1은 결정되기 때문이다.
📌 7. Multi-valued attribute
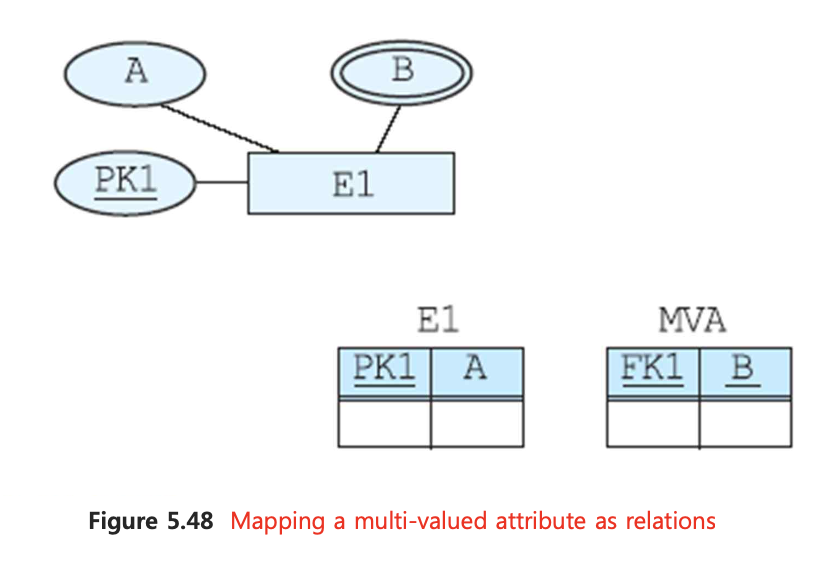
MVA에 대한 테이블을 생성한다.
테이블은 MVA에 해당하는 애트리뷰트들을 포함하고 MVA를 갖고 있던 엔티티 타입의 pk를 테이블의 외래키로 들인다.
테이블의 pk는 MVA와 외래키의 집합이다.
📌 매핑 예시
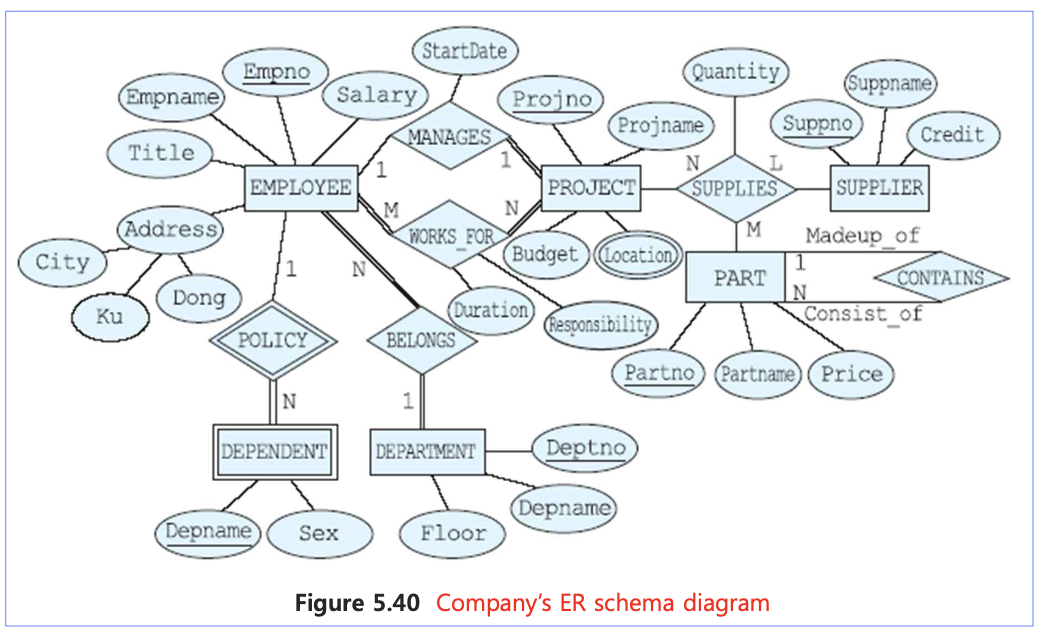
📙 1단계(일반 엔티티)

📙 2단계(위크 엔티티)
weak 엔티티 타입 DEPENDENT를 매핑한다.
owner 엔티티 타입 EMPLOYEE의 pk와 DEPENDENT의 partial key를 조합해 pk를 구성한다.
📙 3단계(1:1 관계)
EMPLOYEE와 PROJECT
- 1:1관계다. 여기서 PROJECT 엔티티 타입이 MANAGES relation에서 전체 참여이기 때문에 PROJECT 테이블에 외래키를 부여한다.
📙 4단계(1:N 관계)

EMPLOYEE & DEPARTMENT
- N:1 관계다. N측인 EMPLOYEE 테이블에 DEPARTMENT의 pk를 외래키로 부여한다.
PART
- 1:N의 순환 관계이다. 자신의 테이블에 외래키를 주입한다.
📙 5단계(M:N)
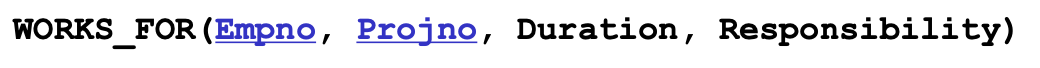
EMPLOYEE & PROJECT
- WORKS_FOR relation에서 M:N의 관계다. WORKS_FOR 테이블을 새로 생성해 양 측 엔티티의 pk 집합을 WORKS_FOR 테이블의 pk로 한다.
- WORKS_FOR의 애트리뷰트 duration, responsibility도 테이블에 포함한다.
📙 6단계

PROJECT & SUPPLIER & PART
- M:N:L 인 Degree가 3의 relation에 참여한다.
- SUPPLY relation을 테이블로 새로 생성해 참여 엔티티의 pk를 모두 받는다. 이들의 조합을 SUPPLY 테이블의 pk로 한다.
- SUPPLIES의 애트리뷰트 Quantity도 SUPPLY 테이블에 포함한다.
📙 7단계

PROJECT의 Location은 MVA다.
PROJ_LOC 테이블을 새로 생성해 Location 애트리뷰트를 갖고 있던 PROJECT 엔티티 타입의 pk를 받아오고 MVA인 Location의 조합을 테이블의 pk로 한다.
📙 최종 매핑

