트랜잭션을 수행하다 system이 down된 경우 어떻게 하면 트랜잭션의 atomicity(all or nothing)을 지킬 수 있을까? 만약 트랜잭션이 완료된 직후에 system이 dowm되었다면 메인 메모리에 저장된 update 내용들이 아직 disk로 저장되지 않았을 텐데 어떻게 트랜잭션의 durability(지속성)을 지킬 수 있을까?
📌 overview
데이터베이스의 성능을 향상시키기 위해 update 내용이 메인 메모리 버퍼에서 disk로 반영이 되었는지 아닌지를 기록하는 것은 중요하다. 일반적으로 트랜잭션이 완료되었다면 disk로 반영이 되겠지만, 메인 메모리 버퍼를 거쳐 disk에 반영이 되는 것이기 때문에 버퍼가 disk에 반영되기 직전에 system이 down되는 등 문제가 발생할 수 있다.
📙 redo, undo
REDO
- system failure 전에 트랜잭션이 완료된 경우, recovery module은 트랜잭션의 durability를 보장하기 위해 redo 작업을 진행해야 한다.
- e.g., 트랜잭션 T1이 완료된 후 log에 commit이 찍혀 있는 경우, T1을 redo해야 한다.
UNDO
- system failure 전에 트랜잭션이 완료되지 않은 경우, recovery module은 트랜잭션의 atomicity를 보장하기 위해 undo 작업을 진행해야 한다.
(e.g., 트랜잭션 T2가 완료되지 않아 log에 commit이 찍혀 있지 않은 경우, T2를 undo해야 한다.)
📙 volatile, non-volatile
메인 메모리같은 휘발성 데이터 타입은 system이 down되면 데이터가 즉시 사라진다.
disk같은 비휘발성 데이터 타입은 저장 장치가 데미지를 받지 않는 한 데이터는 유지된다.
📌 Log
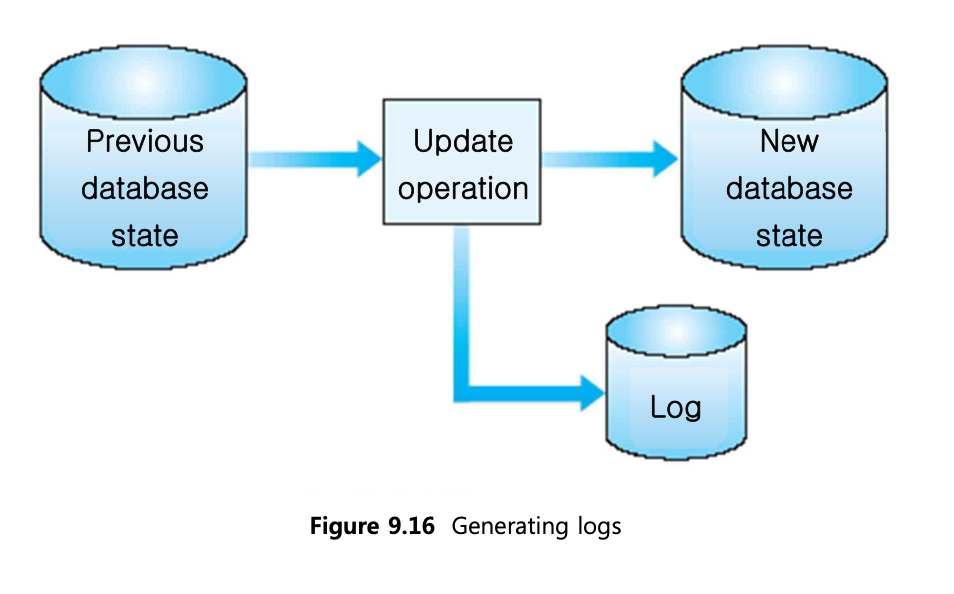
로그는 데이터베이스에 영향을 미치는 모든 트랜잭션 작업을 기록한다.
완료된 트랜잭션 뿐만 아니라 aborted transaction도 기록을 하기 때문에 recovery에 유용하다. redo와 undo 역시 log를 보고 결정하게 된다.
📙 log record 타입
[Transaction ID, start]
[Transaction ID, old value, new value]
[Transaction ID, commit]
[Transaction ID, abort]
📙 log record 예시

두 개의 트랜잭션을 가정하자. T1은 T2 이후에 수행한다. A,B,C,D,E의 초기값은 100, 300, 5, 60, 80이다.
log record는 다음과 같다.

각 log record는 LSN(Log Sequence Number)로 식별된다.
📙 commit log 처리
트랜잭션의 작업이 완료되면 log에 commit을 찍는다.
DBMS recovery module이 log를 체크하며 redo, undo를 결정한다.
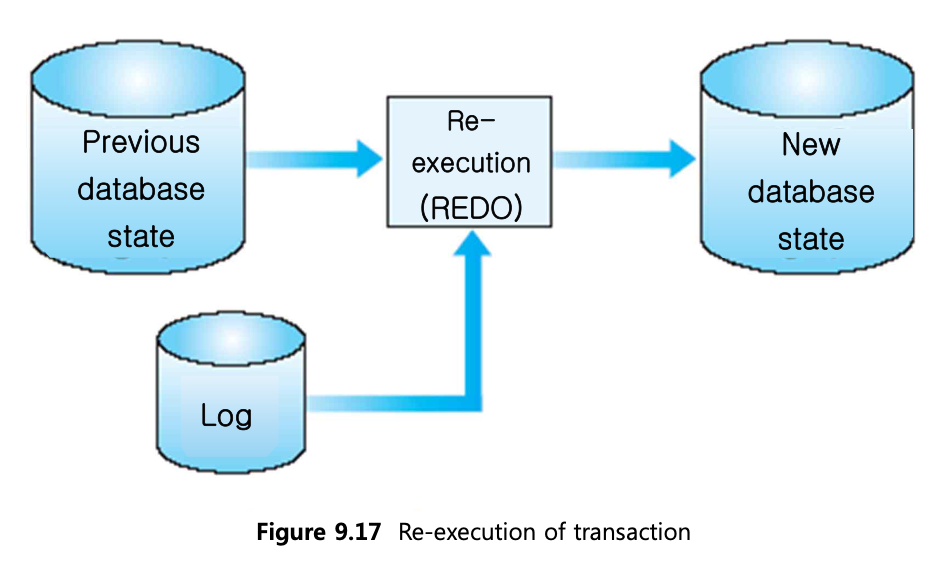
트랜잭션의 start, commit이 모두 있는 경우: redo
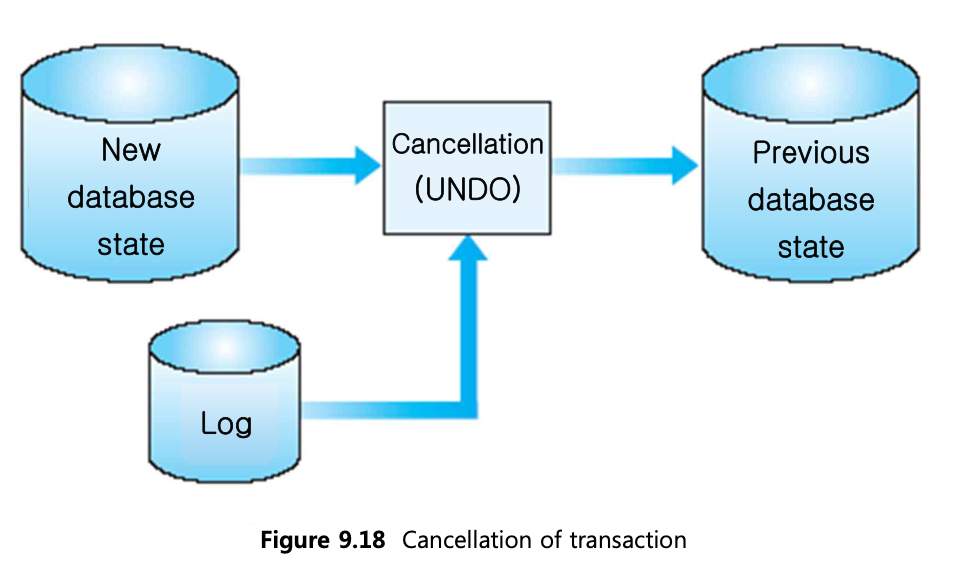
트랜잭션의 start만 있는 경우: undo
위 log를 예시로 redo, undo를 결정해보자.
LSN = 0
- T1, T2의 start도 없기 때문에 redo, undo는 필요 없다.
1 <= LSN <= 4
- T1의 commit이 없다.
- T1을 undo한다.
5 <= LSN <= 9
- T1은 commit이, T2는 start만 있다.
- T1은 redo, T2는 undo한다.
LSN = 10
- T1, T2에 commit이 있다.
- T1, T2를 redo한다.
📙 WAL (Write-Ahead Logging)
트랜잭션이 데이터베이스를 update하는 경우, log record를 log 버퍼에 먼저 write한 후 메인 메모리 데이터베이스 버퍼에 update 내용을 write해야 한다.
데이터베이스의 버퍼가 log 버퍼보다 먼저 disk에 write한 상황에서 log 버퍼에 write하기 전에 system이 down된 상황을 가정하자. 시스템을 다시 켰을 때, 메인 메모리 버퍼는 휘발성이기 때문에 update 기록이 없고 log에도 변경 작업 log가 없는 상황이 발생한다. log record가 없기 때문에 이전 값도 알 수가 없고 트랜잭션을 취소하지 못하게 된다.
📙 Check point
DBMS는 log를 쓰지만, disk에 update되는 것과 main memory에만 남아있는 것을 구별하지 못한다. 따라서, DBMS는 recovery 해야할 트랜잭션의 수를 줄이기 위해 체크포인트를 수행하게 된다.
체크포인트 시점에 main memory 버퍼의 내용은 강제적으로 disk에 옮겨지게 된다. 그래서 만약 체크포인트가 있다면, 거기까지는 disk까지 옮겨진 것이라고 판단할 수 있다. 체크포인트는 log record에 [checkpoint]라고 작성된다.
📚 Check point가 없는 예시
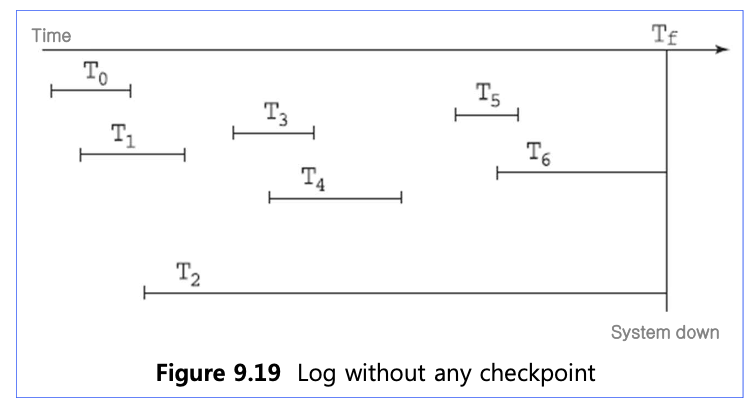
체크포인트 없이 Tf에 서버가 죽었다면 recovery 과정에서 T0, T1, T3, T4, T5는 redo 작업을, T2, T6는 undo 작업을 해야한다.
📚 Check point recovery
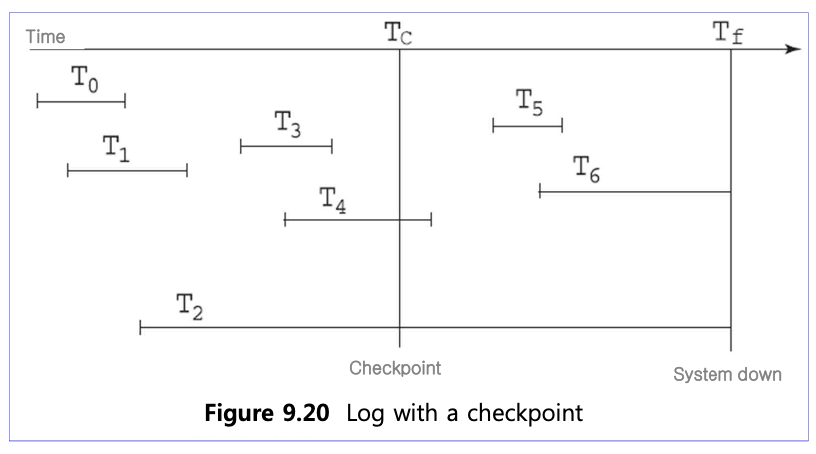
Tc 시점에 체크포인트가 있고 Tf 시점에 서버가 죽었다면 recovery 과정에서 T4, T5는 redo를 T2, T6는 undo 작업을 하면 된다. 체크포인트 시점에 T0, T1, T3의 트랜잭션 작업은 disk에 옮겨 갔기 때문에 고려 대상이 아니다.
📙 Incremental backup
Disk의 구성 요소 오류(Disk head fault와 같은)로 데이터베이스 오류가 극히 드물지만, 이러한 경우 데이터베이스를 복구하는 방법은 DB와 log를 주기적으로 별도의 공간에 백업하는 것이다. 전체 DB를 백업하는 것은 시간이 매우 많이 들기 때문에, 이전 내용에서 update된 내용만 백업하는 incremental backup을 하는 것이 좋다.
