시작은 인덱싱
- 이전부터 DB에 인덱싱 작업이 더 빠르고 효율적인 검색을 가져온다는 것은 들어왔었고 한번도 진행한 경험이 없어서 이번 기회를 통해 진행해보고 싶어서 관련 내용을 찾아봄
- 영상도 많이 보고 실제 진행도 했을 때 우선 인덱싱은 변화가 많이 없는 테이블에 적합하다는 결론 -> 현재 회사 내 오더 테이블은 매분 DML이 일어나고 있기 때문에 적합할 것인가 라는 생각 -- 근데 생각해보니 진행해도 brin(datatime)으로 만들어서 해볼려고 했음. created 자체는 거의 불변이라고 봐도 무방함 그럼 괜찮은거 아닌가..?? modified 같은 경우에는 진행했다가는 아예 그냥 망할 것 같고 .... 개발에서 진행해봐야 겠음
==> 개발 서버에서 진행해보니 확실히 인덱스를 지정해주니 where절에서 훨씬 빠르게 작용하는 것 확인함 오늘 6시 이후에 운영서버에 적용시켜야 할듯
Vacuum
- 다른 database에 있는지 없는지는 잘 모르겟는데 우선 postgresql에는 존재하는 내용 쉽게 말해 디스크조각 모음과 같은 작업
- 공간 재 사용, 트랙잭션 ID 관리, 통계정보 갱신, 인덱스 검색 성능 향상
크게 표준 Vacuum과 Vacuum Full로 나눌 수 있다.
- 표준 Vacuum
- 우선 Vacuum 수행 중에도 SELECT, DML 작업이 가능하다.
또한 단순히 사용가능한 공간을 Free Space Map에 반환
이전 vacuum 작업 이후부터 변경된 페이지들만을 대상으로 vacuum 진행
표준 vacuum 명령이라도 가장 뒤쪽의 페이지부터 연속된 빈 페이지가 존재 할 경우, 해당 페이지를 삭제 하여 Disk의 공간을 확보 한다.
- 우선 Vacuum 수행 중에도 SELECT, DML 작업이 가능하다.
- Vacuum Full
- create as select 작업이라고 생각하면 됨. 그래서 공간이 두 배 필요하고, 기존의 테이블 사이즈보다 작아짐. (디스크 상의 여유 공간이 있어야 작업이 가능 함)
이로 인하여 시간도 오래 걸리며, 수행되는 테이블에 대한 exclusive Lock이 발생 됨.
디스크 상의 여유 공간이 확보 됨.
- create as select 작업이라고 생각하면 됨. 그래서 공간이 두 배 필요하고, 기존의 테이블 사이즈보다 작아짐. (디스크 상의 여유 공간이 있어야 작업이 가능 함)
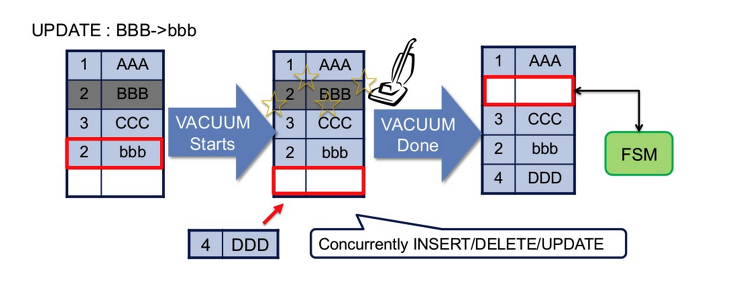
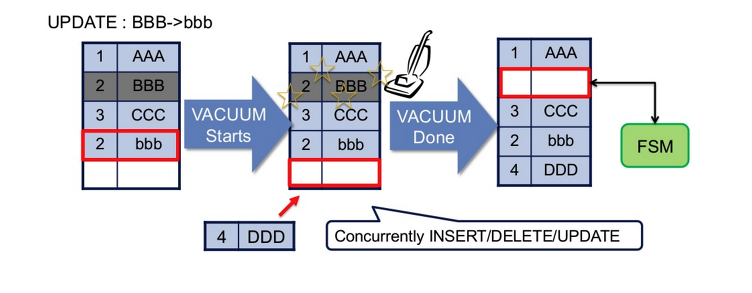
- Postgresql은 위의 방식으로 update를 진행시킨다. 기존의 row를 변경하는 것이 아니라 새로운 데이터를 insert하는 방식이다.
- 현재 회사 내에선 거의 매 분마다 update문이 이루어지고 있는데 이를 생각하면 vacuum은 필수적
SELECT name, setting FROM pg_settings WHERE name='autovacuum'; 명령어로 확인해보니 현재 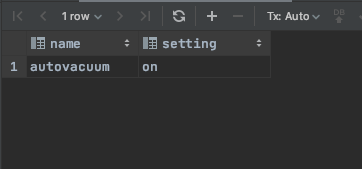 autovacuum 되고 있음을 확인할 수 있다.
autovacuum 되고 있음을 확인할 수 있다.
근데
SELECT relname, n_dead_tup FROM pg_stat_user_tables; 명령어를 통해 확인해보면 dead_tuble이 엄청 많은 것을 알 수 있다. 특히 update, delete, insert가 빈번한 테이블에 경우 더 많음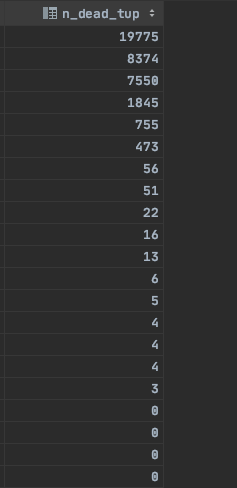
SELECT relname AS "orders_order", pg_size_pretty(pg_table_size(pgc.oid)) AS "space_used" FROM pg_class AS pgc LEFT JOIN pg_namespace AS pgns ON (pgns.oid = pgc.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') AND nspname !~ '^pg_toast' AND relkind IN ('r') ORDER BY pg_table_size(pgc.oid) DESC LIMIT 1;
명령어로 확인한 결고 dead tuple이 많이 쌓여있음을 확인할 수 있었다. 아마 몇몇 table은 내가 직접 vacuum analyze 명령어를 통해 삭제를 해줘서 그런지 작게 나오는 것으로 확인된다. --> 해당 부분은 직접 명령어 입력을 통해 확인하였음! vacuum analyze tabel_name으로 진행 가능
인덱싱 주의사항
-
인덱스가 테이블 동작 속도를 높여준다는 사실은 모두가 알고 있을 것이다. 하짐나 이 역시도 지나치게 많거나 제대로 설정되지 않는다면 오히려 속도를 더 낮추게 될 것이다.
인덱스는 where 절에서 효과가 있으며 단일 컬럼, 여러 컬럼을 묶어 복합 인덱스를 설정할 수 도 있음!
하지만 조회시 자주 사용하고 고유한 값을 위주로 해야 효과적임 -
DML에선 당연히 select에서 가장 효과가 좋음!
update, insert, delete에선 row를 찾을때나 빠르지 각각의 동작이 빨라지지는 않으며 무엇보다 insert에선 기존 인덱스를 수정해줘야하기 때문에 오히려 동작이 느려질수도 있다.
인덱스 고려사항
- 카디널리티, 활용도, 중복도, 선택도
- 카디널리티
각 컬럼이 가지고 있는 중복도를 나타내는 것으로 중복도가 낮을수록 카디널리티는 높다.(PK의 경우 굉장히 높을 것) - 활용도
where 절에서 많이 사용될수록 효과적 - 중복도
중복 인덱스 여부에 대한 값. - 선택도
선택도가 낮을수록 좋은 인덱스 컬럼
근데 이말도 결국 카디널리티와 동일한 의미인 것 같음
예를 들어 100개의 row를 가지는 table에서 1,2,3,4 컬럼이 있다고 가정.
1번은 100개가 다 다르고 2번은 2개씩 같고 3번은 20개씩 같고 4번은 50개씩 같다고 할때 1번의 선택도는 1/100*100으로 1%를 가지고 2,3,4는 각각 2%, 20%, 50%를 가진다 (결국 카디널리티로 모두 설명할 수 있는 내용 아닌가???)
