오늘은 지난번 포스팅에서 예고한 GC에 대해서 좀더 살펴보고자 한다.
GC : Garbage Collection
JVM상에서 더 이상 사용되지 않는 데이터가 할당되어 있는 메모리를 해제시키는 것으로 주로 Heap 영역 내의 참조되지 않은 객체를 수거하거나 metaspace내에 할당되어 있으나 더 이상 사용되지 않는 클래스 혹은 메소드의 메타데이터를 수거하는 역할을 한다.
어떻게 그런게 가능한 거냐???
GC는 크게 2가지 동작을 수행한다.
(1) Stop The World
GC가 동작하면 GC를 담당하는 쓰레드 외에 모든 쓰레드의 작동을 중단하는데 이를 Stop-The-World라 한다. 이 때문에 GC가 빈번하게 발생할 경우 성능이 저하된다. GC를 튜닝하거나 Heap size를 튜닝하는 것의 목표는 OOME로부터 안전하면서 STW로 인한 성능저하를 최대한 줄이기 위한 것이다.
(2) Mark, Sweep, Compact
사용되고 있는 객체를 mark하고 사용되지 않는(mark가 안된) 객체를 삭제(sweep)한다. 이렇게 삭제하게 되면 메모리 외부 단편화가 발생하기 때문에 메모리를 정리(compact)하기도 한다. GC의 종류에 따라 compact를 안하는 GC도 있다.
당연히 궁금한 것들이 생긴다.(나만 궁금한 거일 수 있다.... ㅠ ㅠ)
STW 없이 Mark, Sweep, Compact를 수행하면 안되나? STW가 없이 GC가 수행될 때를 생각해 보자.
-
GC가 reachable하다고 판단하고 mark를 완료한 뒤, 바로 unreachable 상태가 될 경우
- 비효율적이긴 하지만, 큰 문제가 없다. 다음 GC가 동작할 때 해당 garbage를 수거해 갈것이다.
-
GC가 mark단계를 완료 한 뒤, 새로운 객체가 할당되고 sweep을 실행할 경우
- 이 경우 새로 할당된 객체는 mark가 되지 않아 쓰레기로 분류될 것이고 GC가 수거해 간다.
- 이 경우는 확실히 문제가 있다. 객체를 생성한 쓰레드에서는 여전히 유효한 참조라고 판단하지만 실제로는 메모리가 해제되어 잘못된 메모리에 접근하게 될 것이다.
-
그럼 사용되지 않는 객체를 mark하지 않고 사용되는 객체를 mark하는 이유는 뭔가? 사용되지 않는 객체를 mark한다면 문제가 발생하지 않을 텐데???
-
이전 포스팅과 그 전 포스팅의 stack에 대한 내용을 기억해보면 stack은 stack frame을 저장한다. 이 stack frame은 3가지로 구성되는데, local variable array, operand stack, reference to constant pool이 그 3가지다. 그 중 local variable array는 매개 변수와 지역 변수가 저장된다. 그리고 여기에서 변수가 Heap에 동적으로 할당된 객체의 reference임을 저장하게 되는데 해당 reference를 통해 mark를 진행한다.
-
또한 이전 포스팅의 metaspace 부분을 보면 class space에는 OOPMAP이라는 것이 있어 stack에서 해당 클래스 객체를 참조하는 경우를 저장하고 이를 mark 과정을 위한 root로 쓴다는 것을 알 수 있다.
-
결론적으로 참조되는 객체를 찾는 것은 빠르다. 그러나 참조되지 않는 객체를 찾는 것은 훨씬 느리다. 이러한 이유로 GC는 참조되는 객체를 mark하는 것이다.
-
게다가 참조되지 않는 객체를 찾는다 하더라도 Old/Young Generation을 compact 과정에서는 STW가 꼭 필요하다. 메모리에 외부 단편화가 생기지 않도록 정리하는 과정에서 객체가 수정된다면 당연히 문제가 생길것이다.(빈 공간을 찾아 복사본을 할당하고 원래 있던 메모리 공간을 해제해야한다. 근데, 복사까지 완료하고 원본 공간에 수정사항이 생긴 뒤 해당 공간을 해제한다면 그 수정사항이 반영되지 않은 결과를 마주할 것이다.)
Minor GC와 Major GC
지난 포스팅에서 Heap의 구조에 대해 자세히 다루었다. Young Generation에서 발생하는 GC를 Minor GC, Old Generation에서 발생하는 GC를 Major GC라 한다는 것만 설명했다. 오늘은 좀 더 자세히 파보자
1. Minor GC
Young Generation에서 발생하는 GC이다. Young Generation에 위치한 각 영역이 가득 차게되어 더 이상 새로운 객체를 생성할 수 없을 때 발생한다.
Young Generation은 크게 3영역(Eden, Survivor0, Survivor1)으로 나뉘는데 새로 생성된 객체는 Eden에 할당된다. Eden 영역이 가득차 GC가 발생하여 unreachable객체가 수거되고 살아남은 객체는 Survivor 영역 중 하나로 이동된다. 이 과정이 반복되어 Survivor 영역이 가득 차면 GC를 통해 해당 Survivor 영역의 가비지를 수거하고 해당 Survivor영역에서도 살아남은 객체를 다른 Survivor영역으로 이동시킨다. 이 과정을 마치게 되면 GC가 발생한 Survivor 영역은 비워지게 된다. 위와 같은 과정이 계속 반복되었을 때 계속 살아남은 객체는 Old 영역으로 이동하게 된다.
이해를 위해 예시를 보자
출처 : https://www.perfmatrix.com/how-does-garbage-collector-work/
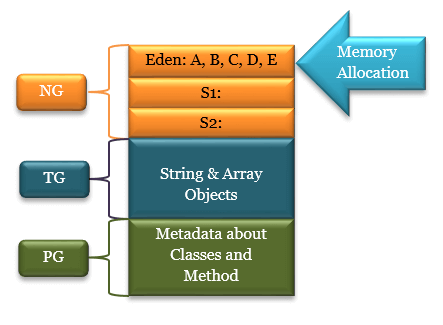
Eden에 5개 까지의 객체가 저장될 수 있다고 가정하자 객체 A, B, C, D, E가 새로 할당되어 Eden이 가득차 GC가 발생 하였다.
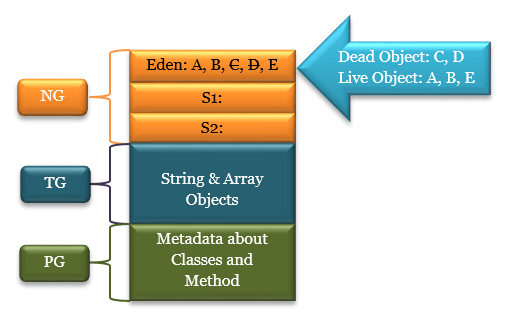
C와 D 객체는 더 이상 참조되지 않는 객체이고 A, B, E가 살아남았을 때 살아남은 객체는 survivor1 영역으로 옮겨진다. survivor 영역은 6개 까지 객체가 저장될 수 있다고 가정하자
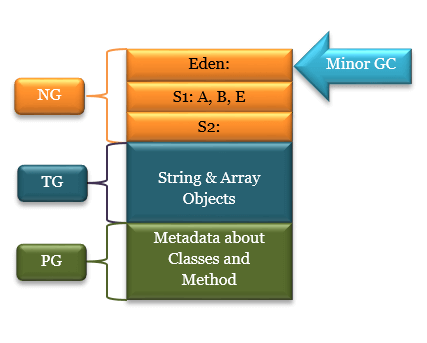
다시 새로운 객체들이(F, G, H, I, J) 할당되어 Eden이 가득 찼을 때 GC가 발생한다.
B와 I가 더 이상 참조되지 않는 객체로 삭제되고 F, G, H, J가 suvivor1영역으로 이동될 것이다.
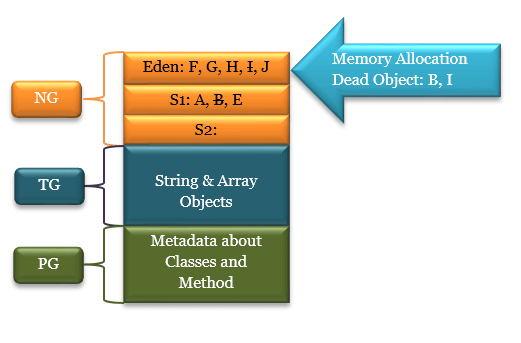
이동 된 뒤 survivor1 영역이 가득 차기 때문에 survivor1영역에서 unreachable 객체를 찾고 survivor2로 살아남은 객체를 이동시킬 것이다. A, E, F, G, H, J 모두 reachable이면 다음의 그림과 같을 것이다.
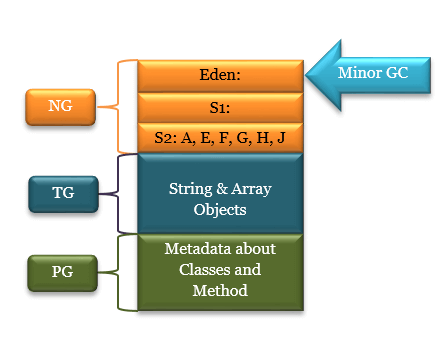
위와 같은 minor GC가 특정한 임계값 만큼 발생했음에도 살아남은 객체는 Old Generation 영역으로 이동하게 되는데 이를 Promotion이라고 한다.
Minor GC에서도 여전히 STW는 발생하지만 이 시간이 무시할 수 있을 정도로 짧게 이루어지기 때문에 STW가 발생하지 않는다고 간주하기도 한다. 또한 minor GC는 major GC에 비해 상대적으로 발생 빈도가 높다.
2. Major GC
Old Generation 영역에서 발생하는 GC이다. 상당히 긴 시간 STW가 이루어지며, 이로 인한 성능저하를 최소화 하기 위해 여러방식의 GC가 있다.
어떤 사람은 Old 영역에서 발생하는 Major GC가 Full GC와 같다고 소개하기도 하고 또 어떤 사람은 Major GC와 Full GC는 다른 것이라 말하는 경우도 있다.
java 8이전의 Permanent(PermGen)영역이 있었을 때는 이 Permanent가 Heap영역 안에 포함되어 있었기 때문에 Permanent + Old + Young(모든 Heap 영역)을 청소하는게 Full GC라 설명하는 사람도 있다.
Major GC == Full GC라는 주장은 맞기도 하고 틀리기도 하다. 엄연히 Major GC와 Full GC는 다르다. Major GC는 Old영역에서 발생하는 GC이고 Full GC는 Old + Young 영역의 쓰레기를 모두 수거하는 것이다.
그러나 예외의 경우도 존재한다. 아래에서 설명할 G1 GC의 경우 Major GC가 수행될 때 Minor GC의 일부과정을 수행한 뒤 Major GC가 수행되기 때문에 Major GC == Full GC라는게 완전히 틀린말은 아니다.
여러 종류의 GC
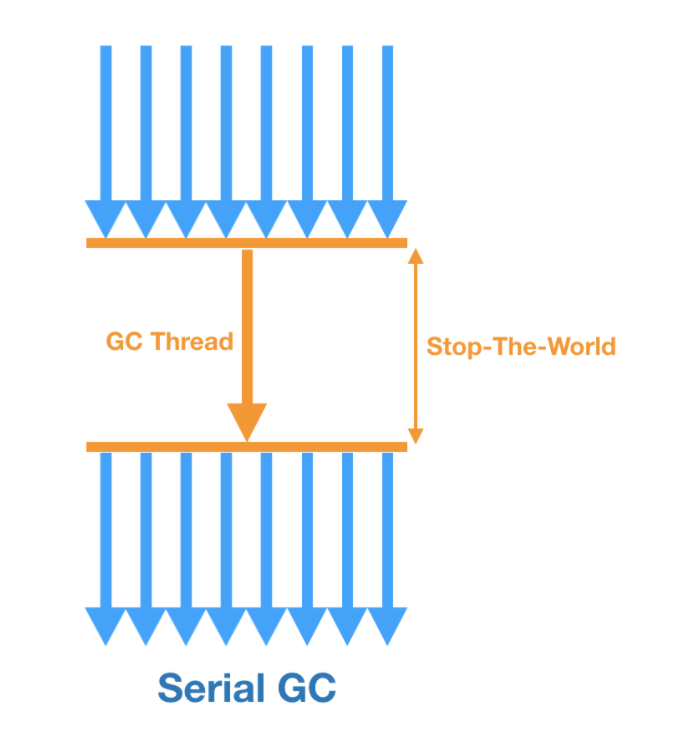
1. Serial GC
가장 단순한 방식의 GC로 싱글 쓰레드로 동작한다. 이 때문에 느리고 STW시간이 다른 GC에 비해 길다.
mark & sweep & compact을 수행한다. 성능이 좋지 않기 때문에 멀티 쓰레드를 이용할 수 있는 환경에서는 Serial GC를 사용하지 않아야 한다.
참조 : https://memostack.tistory.com/229
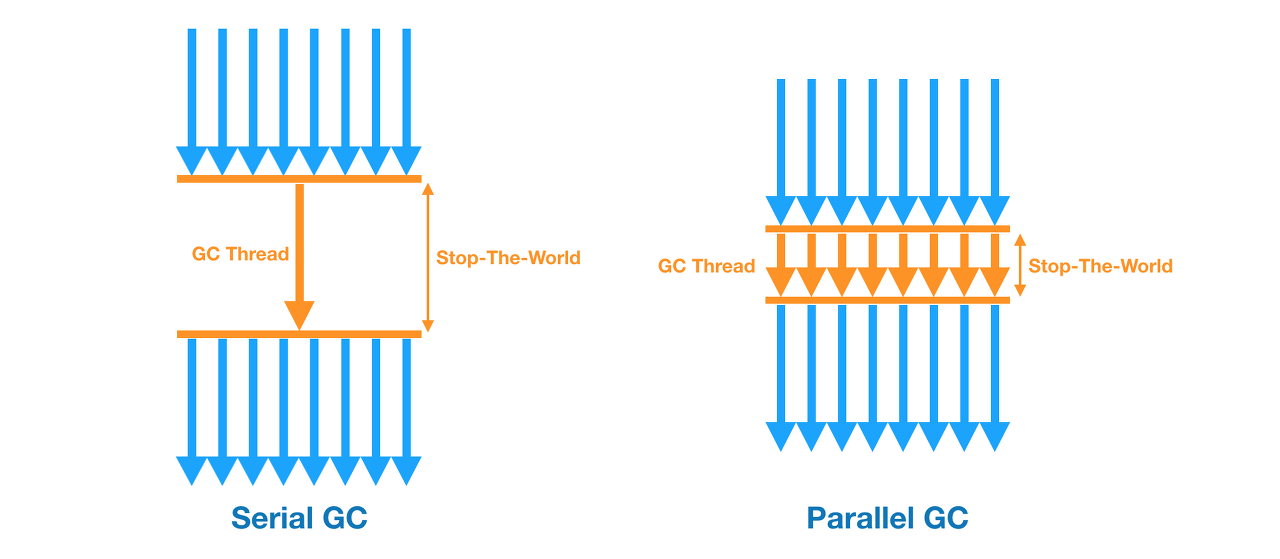
2. Parallel GC
Young Generation 영역의 GC를 멀티 쓰레드 방식으로 수행하기 때문에 Serial GC에 비해 STW가 짧다. 그러나 Old Generation 영역에서는 싱글 쓰레드로 동작한다. 다음의 그림은 Serial GC와 Parallel GC가 Young Generation 에서 작동하는 방식의 차이를 보여준다.
참조 : https://memostack.tistory.com/229
3. Parallel Old GC
Parallel GC가 Young Generaion영역에서만 멀티 쓰레딩 방식으로 GC가 동작했다면, Parallel Old GC는 Old 영역에서도 멀티 쓰리드 방식으로 동작하는 GC이다.
4. CMS GC
STW로 인한 성능 저하를 줄이고자 만든 GC이다. reachable한 객체를 한번에 찾지 않고 나눠서 찾는 방식을 이용한다.
참고사항
Elasticsearch의 default GC가 CMS GC이다.
java 9 이상의 default GC는 G1 GC이고 java 14부터 CMS GC가 jdk에 빠졌는데,
java 14이상을 요구하는 Elasticsearch에서도 CMS GC를 쓸수 있도록 제공 해준다.
참고로 ES에서 G1 GC를 이용할 수도 있다. https://www.elastic.co/guide/en/elasticsearch/reference/current/_g1gc_check.html
JDK 9 이상에서는 문제가 없을 것 같다. 자세한건 다음 포스팅에서....
CMS GC는 Young Generation 영역에서는 Parallel GC처럼 동작한다. Old Generation 영역에서는 도달가능한 객체를 한번에 찾지않고 4가지 단계를 거쳐서 찾는다.
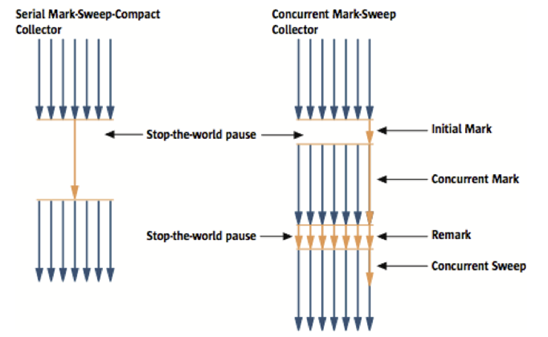
- initial mark
아주 짧은 시간의 STW pause동안 GC Root를 mark한다. 첫번째 포스팅에서 여기까지 집중해서 왔다면 짧은 시간동안 GC root를 어떻게 찾을지 알 수 있을 것이다. 실제 GC root를 찾기 위해서는 아래 2개 이외에 여러가지가 더 이용된다.jvm stack에 있는 stack frame의 local variable array
metaspace의 class space영역의 OOPMAP - Concurrent mark
찾아놓은 GC Root를 따라 도달가능한 객체를 찾는다. 이 때 GC를 수행하는 쓰레드와 애플리케이션을 실행하는 쓰레드를 동시에 실행시키기 때문에 STW가 발생하지 않는다.(이름이 Concurrent Mark다 ㅎㅎ)
참조한 곳
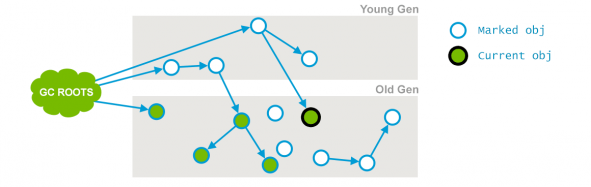
-
Remark
우리는 위에서 mark단계에서 STW가 발생하지 않으면 어떤 문제가 생기는지 살펴본 적이 있다. mark를 수행한뒤 sweep전에 새로운 객체가 할당된 경우 mark되지 않아 수거된다. 이러한 문제들을 해결하기 위해 remark 과정을 거친다. 당연하겠지만 remark시 STW가 필요하다. 그러나 이 STW가 길지 않다. 멀티 쓰레드 방식으로 동작하기 때문이다. -
Concurrent Sweep
최종적으로 reachable객체 이외의 쓰레기를 수거한다. 싱글 쓰레드로 수행되며 이 역시 애플리케이션을 실행하는 쓰레드와 동시에 실행된다. 그래서 sweep시에도 STW가 없다.
또 다시 여기서 발생하는 문제에 대해서 우리는 이미 알고있다. 앞서 살펴본 GC들은 STW시 Sweep과 Compact과정을 수행한다. 그리고 Compact과정은 STW가 반드시 있어야한다.
CMS GC는 sweep간 STW가 발생하지 않는다. 즉 Compact를 수행하지 않기 때문에 메모리 외부단편화가 발생할 수 있다. 이러한 메모리 단편화가 발생했을 때는 Compact를 무조건 수행해야하기 때문에 Concurrent mode Failure가 발생한다. 그리고 이 CMF가 발생하면 STW가 다른 GC보다 길어질 가능성이 높다.(다른 GC는 그때 그때 숙제를 해결하는 느낌이라면 CMS GC는 숙제를 몰아서 하는 느낌이다.ㅠ)
5. G1 GC
G1 GC는 Garbage First Garbage collector의 약어이다. Garbage만 있는 Region을 먼저 회수하기 때문에 Garbage First GC라는 이름이 붙었다.
CMS GC 처럼 mark, sweep에서 STW를 최소화 하면서 Compact과정 까지 지원한다. 많은 양의 메모리가 있는 멀티 프로세서 시스템에서 이용된다.
Heap 영역을 Region이라는 논리적 영역으로 관리한다. 이 Region은 고정된 size를 가지며 JVM이 시작할 때 Region의 크기가 정해진다.
출처 : https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
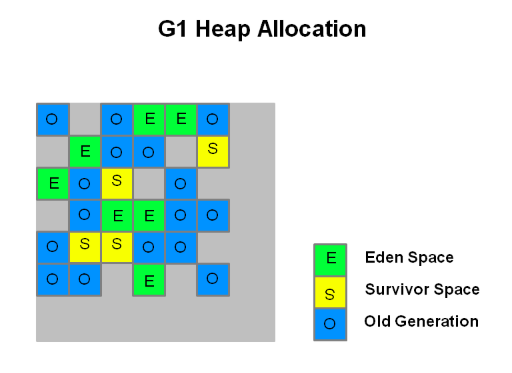
각 Region은 Eden, Survivor, Old, Homongous중 하나로 할당된다. 다른 그림도 보자
출처 : https://www.dynatrace.com/news/blog/understanding-g1-garbage-collector-java-9/

1. G1 GC의 Minor GC
G1 GC의 Minor GC는 기존의 Parallel GC와 유사하다. 다만 지금까지 다룬 전통적인 heap 구조와 다르게 heap영역을 Region을 단위로 나누어 객체를 할당하고 garbage만 있는 region을 빠르게 수거하기 때문에 빈공간을 빨리 확보할 수 있다.
빈 공간을 빨리 확보하는 것은 2가지의 이점이 있다.
1. 조기 promotion의 발생이 다른 GC에 비해 적어질 수 있다.
2. 여유 공간을 빨리 확보하기 때문에 GC 빈도가 줄어들 수 있다.
2. G1 GC의 Major GC
CMS GC와 마찬가지로 여러 단계를 거쳐 수행된다. G1 GC는 5개의 과정이 존재하며 일부 과정은 Minor GC의 일부 과정이다.
-
initial mark
Old Generation에 있는 객체를 참조하는 suvivor region을 마크한다. STW가 발생하는 구간이다. -
root area scan
initial mark단계에서 마킹한 suvivor region에서 Old Generation을 참조하고 있는 객체를 마크한다. 멀티 쓰레드로 동작 하며 애플리케이션 쓰레드도 같이 실행된다.(병렬 + 동시)
Young 영역에서 도달가능한 객체를 마크하는 것은 Minor GC에서 하는 일이다.
그러나 G1 GC는 Major GC 과정에 Minor GC의 과정이 포함되어있다. -
concurrent mark
Old Generation에 reachable 객체를 마킹한다. CMS와 마찬가지로 싱글 쓰레드로 동작하며 STW가 발생하지 않는다. -
remark
Heap영역에 도달 가능한 객체에 대해 리마크를 하여 마킹을 완료한다. 이 과정에서는 STW가 발생한다.(CMS와 같은 이유로) SATP 알고리즘을 통해 initial mark에서도 reachable이고 remark에서도 reachable인 객체를 마킹한다.(그냥 마킹을 하지 않아도 다음 GC에서 수거되겠지만, GC가 한번 발생했을 때 최대한 쓰레기를 수거해 가는 것이 당연히 좋다.) -
copy / clean up
도달 불가능한 객체가 많은 region 순으로 garbage를 수거한다. 수거하기 전 도달 가능한 객체들은 다른 영역으로 복사하고 복사된 영역으로 remapping한 뒤, garbage를 수거한다. 당연히 copy / clean up 시에도 STW가 발생한다.
???왜 5개 단계 중 compact 과정이 없냐? 메모리 단편화가 생기지 않게 정리해야하는데... 라고 생각할 수 있지만 G1 GC에서는 Heap을 region으로 나누어 관리한다. 다시 말해서 eden은 eden끼리, svivor는 survivor끼리, old는 old끼리 연속적일 필요가 없다. 빈 공간을 찾고 복사하는 비효율 적인 방법대신 그냥 새로운 region을 할당해 reachable 객체를 복사하고 unreachable 객체가 있던 region은 clean up 하기만 하면 된다. 그래서 copy / clean up phase가 존재한다.
복잡한 phase만큼 G1 GC는 메모리가 크고 멀티 프로세서 시스템에서 사용되어야 그 진가를 발휘할 수 있다.
6. ZGC
6.1 ZGC 소개
jdk 11버전에 처음 등장하여 jdk 14까지 실험 버전을 제공하였고 jdk 15부터 production ready로 지원되는 GC이다. 오라클 hotspot JVM에서는 다음과 같이 소개한다.
The Z Garbage Collector (ZGC) is a scalable low latency garbage collector. ZGC performs all expensive work concurrently, without stopping the execution of application threads for more than 10ms, which makes is suitable for applications which require low latency and/or use a very large heap (multi-terabytes).
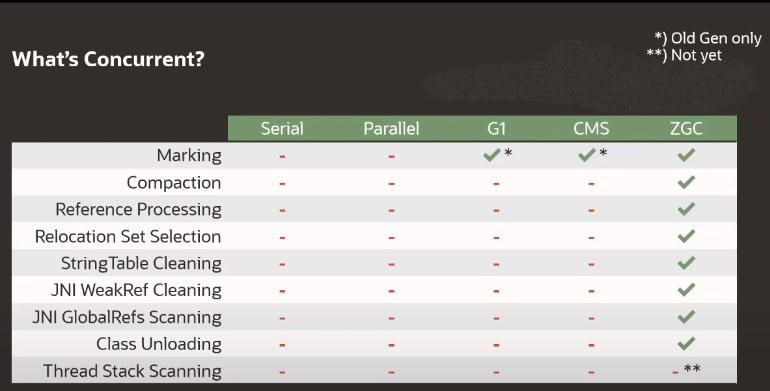
모든 고비용 작업에서도 동시적으로 작동하며 STW로 인한 application 쓰레드의 중단 시간이 10ms이하가 된다고 한다. 아래 그림에서 확인할 수 있듯 G1과 CMS에서는 marking시 concurrent하게 동작 하지만 ZGC는 그 외에 여러 작업에 대해서도 concurrent하게 동작한다.
출처 : https://www.youtube.com/watch?v=88E86quLmQA
출처 : https://www.youtube.com/watch?v=OcfvBoyTvA8
위의 링크들에 zgc에 대한 설명을 30~40분 정도의 동영상으로 제공한다.(ZGC의 개요, design, 사용법과 tuning, longging 등) 아주 도움이 되는 내용들이 많으니 한번 확인해 보면 좋을것 같다.
scalable하기 때문에 Heap size에도 영향을 받지 않고(live-set, root-set size에도 영향을 받지 않는다고 한다.) 저지연을 요구하는 application들이나 multi 테라바이트의 큰 힙크기도 적합하다고 한다.(8MB ~ 16TB)
ZGC는 Zpage를 기준단위로 하여 Heap영역을 나눈다. G1 GC에서 고정된 크기의 region으로 Heap영역을 나누었던 것과 유사하지만, G1 GC는 region이 JVM 시작시 고정된 크기로 정해지는 반면에 Zpage는 동적인 크기로 생성 및 삭제되며 2MB의 배수로 그 크기가 결정된다.
출처 : https://sarc.io/index.php/java/2098-zgc-z-garbage-collectors
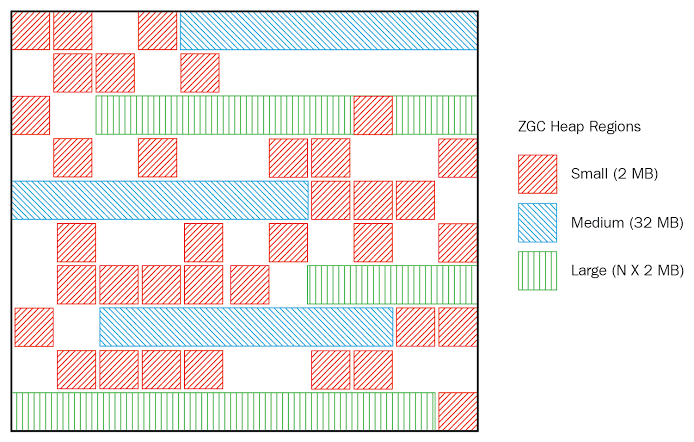
ZGC는 Young과 Old Generation을 구분하지 않고 unreachable 객체를 수거한다. 게다가 메모리 외부 단편화가 생기지 않도록 하는 compact과정을 STW가 없이 수행할 수 있다.
6.2 어떻게 STW없이 compact가 가능한 거냐???
우리는 region이나 zpage처럼 Heap영역을 작은 크기로 분할하게 되면, compact 과정 시 빈공간을 찾아 메모리가 연속적이게 정리하지 않아도 되기 때문에 copy / clean up 이라는 간단한 방법으로 compact가 가능하다는 것을 알고있다.
또한 compact과정을 동시적으로 수행할 때 발생하는 문제를 위에서 다루었다.
ZGC는 이러한 compact과정을 동시적으로 수행하기 위해 Load Barrier와 Colored Pointer를 사용한다.
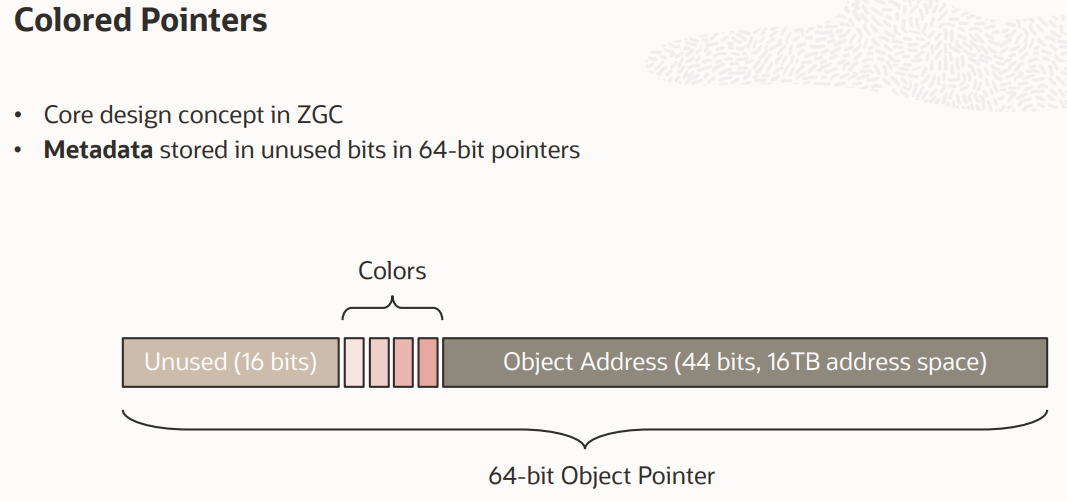
Colored Pointer
참고사항 : 2020년도 자료를 기준으로 조사한 것이다. 이전에는 object address가 42비트로 최대 4TB까지 지원했던것 같다. 2022년도 05월 기준으로 open JDK에서 ZGC가 8MB to 16TB라고 하는 것을 보니 object address가 44비트로 구성된게 맞는 것 같다.
출처 : http://cr.openjdk.java.net/~pliden/slides/ZGC-OracleDevLive-2020.pdf
ZGC의 핵심 디자인 컨셉이다. Colored pointer는 finalizable, remapped, marked 1, marked 0의 4개의 비트를 사용한다. 64bit pointer에서 주소의 범위는 16EB(엑사바이트)이고 현실적으로 이를 다 사용할 수 없다. 또한 ZGC는 8MB ~ 16TB의 힙 크기를 위한 GC이다. 따라서 44bit외에 사용되지 않는 20bits의 일부에 GC의 메타데이터를 저장한다. 이 메타데이터를 통해 객체에 대한 find, mark, locate, remap 등을 수행할 수 있게 된다. 당연히 64비트가 아닌 시스템에서는 사용할 수 없다.
Finalizable : finalizer를 통해서만 참조되는 Object의 Garbage
Remapped : 재배치 여부를 판단하는 mark
mark 1, 0 : reachable object makr
Load Barrier
힙에서 객체 참조가 로딩될 때 JIT 컴파일러를 통해 만들어진 기계어 코드 조각이 삽입된다.
출처 : http://cr.openjdk.java.net/~pliden/slides/ZGC-OracleDevLive-2020.pdf
아래의 그림과 같이 colored pointer가 bad color인지 확인하고 bad color라면 mark/relocate/remapping을 수행한다. 다만 빨간 부분은 JIT 컴파일러에 의해 삽입된 기계어 코드일 것이다.


다음은 colored pointer의 (remapped, marked 1, marked 0)의 mask bit 개요이다.
| GoodMask | BadMask | WeekGoodMask | WeekBadMask | |
|---|---|---|---|---|
| mark 0 | 001 | 110 | 101 | 010 |
| mark 1 | 010 | 101 | 110 | 001 |
| remapped | 100 | 011 | 100 | 011 |
이 mask bit를 이용하여 load barrier가 다음의 작업을 수행한다.
- 포인터가 relocated(재배치된) 객체를 point할 경우 올바른 주소값으로 pointer를 수정한다(remapping).
- marking phase에서 객체의 참조에 대해 colored pointer가 bad color라면 slow_path로 진입한뒤 mark 상태를 업데이트 한다(marking).
- reloacting phase에서 포인터가 재배치될 예정인 객체를 가리킬 경우 해당 객체를 재배치 한 뒤 포인터를 재배치한 위치에 맞게 수정한다(relocating).
6.3 ZGC 동작 단계
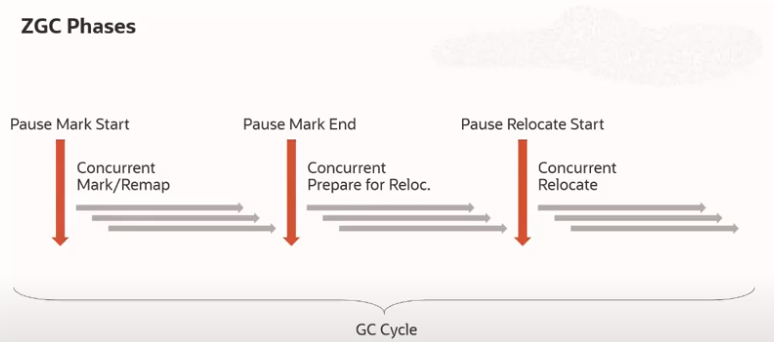
이제 concurrent하게 동작하는 ZGC의 Phase를 이해하기 위한 준비가 끝났다. ZGC는 아래의 그림과 같이 6개의 단계가 존재하고 3개의 pause(STW가 발생)단계가 존재한다.
-
Pause Mark Start
CMS GC, G1 GC의 initial mark과정과 유사하게 STW가 발생하며 GC root set을 만든다. -
Concurrent mark
GC root set에서 시작하여 reachable 객체를 mark한다. Concurrent mark 단계에서 Load barrier가 marking 되지 않은 객체를 detect하고 해당 객체를 marking할 수 있도록 한다. ZGC는 각 Zpage의 live-map이라는 곳에 reachable객체의 정보를 저장한다. 이 live-map은 주어진 인덱스의 객체가 strongly-reachable하거나 final-reachable한지를 저장한다. reachable 객체를 mark하는 GC 쓰레드가 동작하면서 동시에 application 쓰레드도 동작하게 되는데, 이로인해 mark된 객체가 unreachable로 바뀌거나 새로운 객체가 할당 될 수 있다. -
Pause Mark End
STW가 발생하며 새롭게 할당된 객체를 mark한다. -
Concurrent Processing
재배치 하려는 Zpage를 찾아 Relocation Set에 배치한다.4.1 Concurrent Reset Relocation Set - relocation set을 reset하는 과정이다.
4.2 Concurrent Select Relocation Set - relocation set을 선택한다.
4.3 Prepare Relocation Set - relocation set은 unreachable 객체가 존재하여 수거의 대상이 되는 Zpage들이다. 이 때 수거하기 전 Zpage에 있는 reachable 객체들을 새로운 Zpage에 할당하여 재배치하고 재배치된 주소를 다시 매핑해주어야 한다. prepare relocation set은 이러한 remapping에 필요한 forwarding table을 할당하여 remapping을 준비하는 단계이다. -
Pause Relocate Start
STW가 발생하는 구간으로 relocation set에 있는 Zpage들중에서 GC root에서 참조되는 Zpage를 relocate/remap한다. -
Concurrent Relocate
relocation set에서 reachable 객체를 탐지하고 재배치되지 않은 모든 객체를 새로운 Zpage로 재배치한다. 또한 재배치된 객체들에 대한 참조를 Load Barrier를 통해 재배치된 영역을 가리키도록 pointer를 업데이트한다.
여기까지 GC에 대해서 알아보았다. ZGC에 대해서 아주 자세히 설명한 좋은 글이 있어 링크를 첨부한다.
https://www.blog-dreamus.com/post/zgc%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C
