인공지능 및 기계학습 개론 1 - 3주차 Quiz
BayesClassifierClassification_AlgorithmsClassification_ExamplesConditional_ProbabilityNaive_Bayes_Assumption기계학습 개론 1
기계학습 개론1
목록 보기
8/8
- 다음 설명 중 옳지 않은 것은?
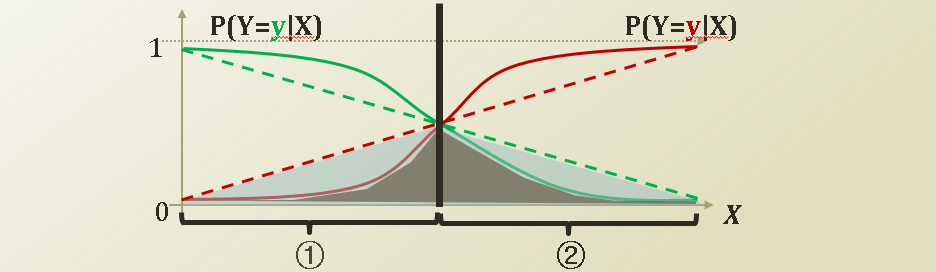
- ① 영역에 해당하는 X에 대해서는 푸른색 y로, ② 영역에 해당하는 X에 대해서는 붉은색 y로 분류하여 예측한다
- 실선 classifier가 점선 classifier보다 Bayes risk가 크다
- 실선 classifier가 점선 classifier에 비해 더 나은 classifier라 할 수 있다
점선 classifier의 Risk가 실선 classifier보다 반달 모양의 파란색 부분만큼 Bayes risk가 큼을 알 수 있다.
- 다음 중 Naïve Bayes Classifier에 대한 설명으로 옳지 않은 것은?
- 텍스트 분석, 예컨대 sentiment analysis 등의 문제에 적용할 수 있다.
- 데이터들 간의 상관관계가 강한 데이터보다, 데이터들의 상관관계가 없는 데이터에서 일반적으로 좋은 성능을 보인다.
- Naïve assumption을 전제로 하는데 이는 단점으로 작용할 수 있다.
- Input feature 간 marginal independence를 가정한다.
Input feature 간 conditional independence를 가정한다.

먼저 EnjoySpt=Yes인 경우와 NO인 경우에 Class Prior 따로 구하면
이다.
그리고 각 Feature간에 EnjoySpt가 Yes일 때의 조건부 확률을 계산하면 다음과 같다.
이를 Naive Bayes Classifier의 식에 따라 모두 곱해주면 다음과 같은 값이 나오게 된다.
