-
프로세스와 쓰레드(process & thread)
🔸 프로세스 : 실행 중인 프로그램, 자원(resources)과 쓰레드로 구성
🔸 쓰레드 : 프로세스 내에서 실제 작업을 수행
모든 프로세서는 최소한 하나의 쓰레드를 가지고 있다.
프로세스 : 쓰레드 = 공장 : 일꾼
🔸 싱글 쓰레드 프로세스 = 자원 + 쓰레드
🔸 멀티 쓰레드 프로세스 = 자원 + 쓰레드 + 쓰레드 + ... + 쓰레드"하나의 새로운 프로세스를 생성하는 것보다
하나의 새로운 쓰레드를 생성하는 것이 더 적은 비용이 든다." -
멀티쓰레드의 장단점
🔹 장점 -> 여러모로 좋다
- 시스템 자원을 보다 효율적으로 사용할 수 있다.
- 사용자에 대한 응답성(responseness)이 향상된다.
- 작업이 분리되어 코드가 간결해진다.🔸 단점 -> 프로그래밍 할 때 고려해야 할 사항들이 많다.
- 동기화(synchronization)에 주의해야 한다.
- 교착상태(dead-lock)가 발생하지 않도록 주의해야 한다.
- 각 쓰레드가 효율적으로 고르게 실행될 수 있게 해야한다. -
쓰레드의 구현과 실행
- Thread클래스를 상속
class MyThread extends Thread { public void run() { //Thread클래스의 run()을 오버라이딩 ... - Runnable인터페이스를 구현
class MyThread implements Runnable { public void run() { //Runnable인터페이스의 추상메서드 run()을 구현 ...MyThread t1 = new Thread(); //쓰레드의 생성 t1.start(); //쓰레드의 실행
Runnable r = new MyThread(); Thread t2 = new Thread(r); //Thread(Runnable r) //Thread t2 = new Thread(new MyThread()); t2.start();
- 쓰레드의 실행 - start()
- 쓰레드를 생성한 후에 start()를 호출해야 쓰레드가 작업을 시작한다.
-
start()와 run()
1 . main이 start를 호출
2 . start가 새로운 호출스택을 생성
3 . start 종료 -> 새로운 호출스택에 run 호출
4 . 각각의 쓰레드가 자기만의 호출스택을 가지고 실행 -
main 쓰레드
- main메서드의 코드를 수행하는 쓰레드
- 쓰레드는 '사용자 쓰레드'와 '데몬 쓰레드' 두 종류가 있다.실행 중인 사용자 쓰레드가 하나도 없을 때 프로그램은 종료된다.
-
쓰레드의 I/O블락킹(blocking)
-
쓰레드의 우선순위(priority of thread)
- 작업의 중요도에 따라 쓰레드의 우선순위를 다르게 하여 특정 쓰레드가 더 많은 작업시간을 갖게 할 수 있다. -
쓰레드 그룹
- 서로 관련된 쓰레드를 그룹으로 묶어서 다루기 위한 것
- 모든 쓰레드는 반드시 하나의 쓰레드 그룹에 포함되어 있어야 한다.
- 쓰레드 그룹을 지정하지 않고 생성한 쓰레드는 'main쓰레드 그룹'에 속한다.
- 자신을 생성한 쓰레드(부모 쓰레드)의 그룹과 우선순위를 상속받는다. -
데몬 쓰레드(daemon thread)
- 일반 쓰레드의 작업을 돕는 보조적인 역할을 수행
- 일반 쓰레드가 모두 종료되면 자동적으로 종료된다.
- 가비지 컬렉터, 자동저장, 화면 자동갱신 등에 사용된다.
- 무한루프와 조건문을 이용해서 실행 후 대기하다가 특정조건이 만족되면 작업을 수행하고 다시 대기하도록 작성한다.boolean inDaemon() - 쓰레드가 데몬 쓰레드인지 확인한다. 맞으면 true 만환
void setDaemon(boolean on) - 쓰레드를 데몬 쓰레드로 또는 사용자 쓰레드로 변경.
매개 변수 on을 true로 지정하면 데몬 쓰레드가 된다.* setDeamon(boolean on)은 반드시 start()를 호출하기 전에 실행되어야 한다.
그렇지 않으면 IllegalThreadStateException이 발생한다. -
쓰레드의 상태
① NEW : 쓰레드가 생성되고 아직 start()가 호출되지 않은 상태
② RUNNABLE : 실행 중 또는 실행 가능한 상태
③ BLOCKED : 동기화블럭에 의해서 일시정지된 상태(lock이 풀릴 때까지 기다리는 상태)
④ WAITING, TIMED_WAITING : 쓰레드의 작업이 종료되지는 않았지만 실행가능하지 않은(unrunnable) 일시정지상태. TIMED_WAITING은 일시정지 시간이 지정된 경우를 의미
⑤ TERMINATED : 쓰레드의 작업이 종료된 상태 -
쓰레드의 실행제어
- 쓰레드의 실행을 제어할 수 있는 메서드가 제공된다.🔸 sleep()
- 현재 쓰레드를 지정된 시간동안 멈추게 한다.
- static메서드. 자기 자신에 대해서만 동작한다.
- 예외처리를 해야한다. (InterruptedException이 발생하면 깨어남)
- 특정 쓰레드를 지정해서 멈추게 하는 것은 불가능하다.🔸 interrup()
- 대기상태(WAITING)인 쓰레드를 실행대기 상태(RUNNABLE)로 만든다.void interrupt() : 쓰레드의 interrupted상태를 false에서 true로 변경
boolean inInterrupted() : 쓰레드의 interrupted상태를 반환
static boolean interrupted() : 현재 쓰레드의 interrupted상태를 알려주고, false로 초기화🔸 suspend(), resume(), stop()
- 쓰레드의 실행을 일시정지, 재개, 완전정지 시킨다.void suspend() : 쓰레드를 일시정지 시킨다.
void resume() : suspend()에 의해 일시정지된 쓰레드를 실행대기상태로 만든다.
void stop() : 쓰레드를 즉시 종료시킨다.- suspend(), resume(), stop()은 교착상태에 빠지기 쉬워서 deprecated되었다.
🔸 join()
- 지정된 시간동안 특정 쓰레드가 작업하는 것을 기다린다.void join() //작업이 모두 끝날 때까지
void join(long millis) //천분의 일초 동안
void join(long millis, int nanos) //천분의 일초 + 나노초 동안- 예외처리를 해야 한다.(InterruptedException이 발생하면 작업 재개)
🔸 yield()
- 남은 시간을 다음 쓰레드에게 양보하고, 자신(현재 쓰레드)은 실행대기 한다.
- static메서드. 자기 자신에 대해서만 동작한다.
- yield()와 interrupt()를 적절히 사용하면, 응답성과 효율을 높일 수 있다. -
쓰레드의 동기화(synchronization)
- 멀티 쓰레드 프로세스에서는 다른 쓰레드의 작업에 영향을 미칠 수 있다.
- 진행중인 작업이 다른 쓰레드에게 간섭받지 않게 하려면 '동기화'가 필요쓰레드의 동기화 - 한 쓸드가 진행중인 작업을 다른 쓰레드가 간섭하지 못하게 막는 것
- 동기화하려면 간섭받지 않아야 하는 문장들을 '임계영역'으로 설정
- 임계영역은 락(lock)을 얻은 단 하나의 쓰레드만 출입가능(객체 1개에 락 1개) -
synchronized를 이용한 동기화
- synchronized로 임계영역(lock이 걸리는 영역)을 설정하는 방법 2가지1 . 메서드 전체를 임계 영역으로 지정 public synchronized void calcSum() { ... } //중괄호 전체(메서드 전체)가 임계영역 2 . 특정한 영역을 임계 영역으로 지정 synchronized(객체의 참조변수) { ... } //중괄호 전체가 임계영역🔸 wait()과 notify()
- 동기화의 효율을 높이기 위해 wait()과 notify()를 사용.
- Object클래스에 정의되어 있으며, 동기화 블록 내에서만 사용할 수 있다.wait() - 객체의 lock을 풀고 쓰레드를 해당 객체의 waiting pool에 넣는다.
notify() - waiting pool에서 대기중인 쓰레드 중의 하나를 깨운다.
notifyAll() - waiting pool에서 대기중인 모든 쓰레드를 깨운다. -
람다식(Lambda Expression)
- 함수(메서드)를 간단한 '식(expression)'으로 표현하는 방법- 익명 함수(이름이 없는 함수, anonymous function)
① 반환타입과 이름을 지우고
② 매개변수() 뒤에 -> 넣기- 함수와 메서드 차이 : 근본적으로는 동일. 함수는 일반적 용어, 메서드는 객체지향개념 용어
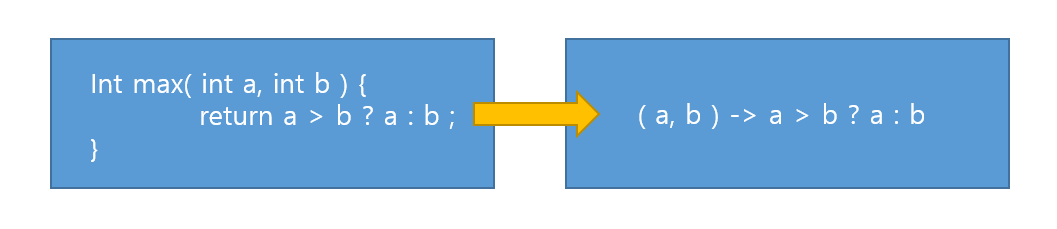
-
람다식 작성하기
1 .메서드의 이름과 반환타입을 제거하고 '->'를 블록{} 앞에 추가한다.
2 .반환값이 있는 경우, 식이나 값만 적고 return문 생략 가능(끝에 ';' 안 붙임)
3 .매개변수의 타입이 추론 가능하면 생략가능(대부분의 경우 생략가능) -
람다식 작성하기 - 주의사항
1 .매개변수가 하나인 경우, 괄호() 생략가능(타입이 없을 때만)
2 .블록 안의 문장이 하나뿐 일 때, 괄호{} 생략가능(끝에 ';' 안붙임)
단, 하나뿐인 문장이 return문이면 괄호{} 생략불가 -
람다식은 익명 함수x 익명 객체o
- 람다식은 익명 함수가 아니라 익명 객체이다. -
함수형 인터페이스
- 함수형 인터페이스는 단 하나의 추상 메서드만 선언된 인터페이스
- 함수형 인터페이스 타입의 참조변수로 람다식을 참조할 수 있음
(단, 함수형 인터페이스의 메서드와 람다식의 매개변수 개수와 반환타입이 일치해야 함) -
함수형 인터페이스 타입의 매개변수, 반환타입
- 함수형 인터페이스 타입의 매개변수
@FunctionalInterface interface MyFunction { void myMethod(); }
void aMethod(MyFunction f) { f.myMethod(); //MyFunction에 정의된 메서드 호출 }
MyFunction f = () -> System.out.println("myMethod()"); aMethod(f);
aMethod(() -> System.out.println("myMethod()")); //위와 같은 문장- 함수형 인터페이스 타입의 반환타입
MyFunction myMethod() { MyFunction f = () -> {}; return f; }
MyFunction myMethod() { return () -> {}; } //위의 문장을 람다로 작성한 것 -
java.util.function패키지
- 자주 사용되는 다양한 함수형 인터페이스를 제공

-
Predicate의 결합
- and(), or(), negate()로 두 Predicate를 하나로 결합(default메서드)
- 등가비교를 위한 Predicate의 작성에는 isEqual()를 사용(static 메서드) -
메서드 참조(method reference)
- 하나의 메서드만 호출하는 람다식은 '메서드 참조'로 간단히 할 수 있다.

⛔ 메서드 참조를 람다로 변경하는 연습⛔
-
스트림 (Stream)
- 다양한 데이터 소스를 표준화된 방법으로 다루기 위한 것List< Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream< Integer> intStream = list.stream(); //컬렉션
Stream< String> strStream = Stream.of(new String[]{"a", "b", "c"}); //배열
Stream< Integer> evenStream = Stream.iterate(0, n->n+2); //0, 2, 4, 6...
Stream< Double> randomStream = Stream = Stream.generate(Math::random); //람다식
IntStream intStream = new Random().ints(5); // 난수 스트림(크기가 5)- 스트림이 제공하는 기능 - 중간 연산과 최종 연산
중간 연산 - 연산결과가 스트림인 연산. 반복적으로 적용가능
최종 연산 - 연산결과가 스트림이 아닌 연산. 단 한번만 적용가능(스트림의 요소를 소모) -
스트림의 특징
🔸 스트림은 데이터 소스로부터 데이터를 읽기만 할 뿐 변경하지 않는다.
🔸 스트림은 Iterator처럼 일회용이다. 필요하면 다시 스트림을 생성해야 함.
🔸 최종 연산 전까지 중간연산이 수행되지 않는다. - 지연된 연산
🔸 스트림은 작업을 내부 반복으로 처리한다.
🔸 스트림의 작업을 병렬로 처리 - 병렬스트림(멀티쓰레드)
🔸 기본형 스트림 - IntStream, LongStream, DoubleStream
- 오토박싱&언박싱의 비효율이 제거됨(Stream< Integer> 대신 IntStream사용)
- 숫자와 관련된 유용한 메서드를 Stream< T>보다 더 많이 제공 -
스트림 만들기 - 컬렉션
- Collection인터페이스의 stream()으로 컬렉션을 스트림으로 변환Stream<E> stream() //Collection인터페이스의 메서드 List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); Stream<Integer> intStream = list.stream(); //list를 스트림으로 변환 //스트림의 모든 요소를 출력 intStream.forEach(System.out::print); //12345 intStream.forEach(System.out::print); //error. 스트림이 이미 닫혔다. -
스트림 만들기 - 임의의 수
- 난수를 요소로 갖는 스트림 생성하기IntStream intStream = new Random().ints(); //무한 스트림 intStream.limit(5).forEach(System.out::pringln); //5개의 요소만 출력한다. IntStream intStream = new Random().ints(5); //크기가 5인 난수 스트림을 반환 ``` -
스트림 만들기 - 특정 범위의 정수
- 특정 범위의 정수를 요소로 갖는 스트림 생성하지(IntStream, LongStream)IntStream IntStream.range(int begin, int end) IntStream IntStream.rangeClosed(int begin, int end) IntStream intStream = IntStream.range(1, 5); //1,2,3,4 IntStream intStream - IntStream.rangeClosed(1, 5); //1,2,3,4,5 ``` -
스트림 만들기 - 람다식 iterate(), generate()
- 람다식을 소스로 하는 스트림 생성하기static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) //이전 요소에 종속적 static <T> Stream<T> generate(Supplier<T> s) //이전 요소에 독립적- iterate()는 이전 요소를 seed로 해서 다름 요소를 계산한다.
- generate()는 seed를 사용하지 않는다. -
스트림 만들기 - 파일과 빈 스트림
- 파일을 소스로 하는 스트림 생성하기Stream<Path> Files.list(Path dir) //Path는 파일 또는 디렉토리 Stream<String> Files.lines(Path path) Stream<String< Files.lines(Path path, Charset cs) Stream<String> lines() //BufferedReader클래스의 메서드- 비어있는 스트림 생성하기
Stream emptyStream = Stream.empty(); //empty()는 빈 스트림을 생성해서 반환한다. long count = emptyStream.count(); //count의 값은 0 -
스트림의 연산
- 스트림이 제공하는 기능 : 중간 연산과 최종 연산중간 연산 - 연산결과가 스트림인 연산. 반복적으로 적용가능
최종 연산 - 연산결과가 스트림이 아닌 연산. 단 한번만 적용가능(스트림의 요소를 소모) -
스트림의 중간연산
🔸 스트림 자르기 - skip(), limit()
Stream<T> skip(long n) //앞에서부터 n개 건너뛰기 Stream<T> limit(long maxSize) //maxSize 이후의 요소는 잘라냄
🔸 스트림의 요소 걸러내기 - filter(), distinct()
Stream<T> filter(Predicate<? super T> predicate) //조건에 맞지 않는 요소 제거 Stream<T> distinct() //중복제거
🔸 스트림 정렬하기 - sorted()
Stream<T> sorted() //스트림 요소의 기본정렬(Comparable)로 정렬 Stream<T> sorted(Comparator<? super T> comparator) //지정된 Comparator로 정렬🔸 Comparator의 comparing()으로 정렬 기준을 제공
comparing(Function<T, U> keyExtractor) comparing(Function<T, U> keyExtractor, Comparator<U> keyComparator)🔸 추가 정렬 기준을 제공할 때는 thenComparing()을 사용
thenComparing(Comparator<T> other) thedComparing(Function<T, U> keyExtractor) thenComparing(Function<T, U> keyExtractor, Comparator<U> keyComp)🔸 스트림의 요소 변환하기 - map()
Stream<R> map(Function<? super T, ? extends R> mapper) //Stream<T> -> Stream<R>
🔸 스트림의 요소를 소비하지 않고 엿보기 - peek()
Stream<T> peek(Consumer<? super T> action) //중간 연산(스트림을 소비x) void forEach(Consumer<? super T> action) //최종 연산(스트림을 소비o)
🔸 스트림의 스트림을 스트림을 변환 - flatMap()
Stream<String[]> strArrStrm = Stream.of(new String[]{"abc", "def", "ghi"}, new String[]{"ABC", "GHI", "JKLMN"}); Stream<Stream<String>> strStrStrm = strArrStrm.map(Arrays::stream); Stream<String> strStrStrm = strArrStrm.flatMap(Arrays::stream); //Arrays.stream(T[]) -
Optional< T>
🔸 T타입 객체의 래퍼클래스 - Optional< T>
- 모든 타입의 객체 저장 가능
- null을 직접 다루는 것은 위험하기 때문에 간접적으로 null 다루기 위해 사용
① NullPointException 발생 가능
② null을 사용하려면 null체크를 해야 -> if문 필요 -> 코드가 길어짐public final class Optional<T> { private final T value; //T타입의 참조변수 ... } -
Optional< T>객체 생성하기
- Optional< T>객체를 생성하는 다양한 방법String str = "abc" Optional<String> optVal = Optional.of(str); Optional<String> optVal = Optional.of("abc"); Optional<String> optVal = Optional.of(null); //NullPointException Optional<String> optVal = Optional.ofNullable(null); //OK- null대신 빈 Optional< T>객체를 사용하자
Optional<String> optVal = null; //널로 초기화. 바람직하지 않음 Optional<String> optVal = Optinal.<String>empty(); //빈객체로 초기화- Optional객체의 값 가져오기 - get(), orElse(), orElseGet(), orElseThrow()
Optinal<String> optVal = Optionam.of("abc"); String str1 = optVal.get(); //optVal에 저장된 값을 반환. null이면 예외발생 String str2 = optVal.orElse(""); //optVal에 저장된 값이 null일 때는, ""를 반환 String str3 = optVal.orElseGet(String::new); ..람다식 사용가능 () -> new String() String str4 = optVal.orElseThrow(NullPointerException::new); //널이면 예외발생- isPresent() - Optinal객체의 값이 null이면 false, 아니면 true를 반환
if(Optinal.ofNullable (str).isPresent()) { //if(str != null) { System.out.println(str); } -
스트림의 최종연산 - forEach()
- 스트림의 모든 요소에 지정된 작업을 수행 - forEach(), forEachOrdered()void forEach(Consumer<? super T> action) //병렬스트림인 경우 순서가 보장되지 않음 void forEachOrdered(Consumer<? super T> action) //병렬스트림인 경우에도 순서가 보장됨 -
스트림의 최종연산 - 조건 검사
- 조건 검사 - allMatch(), anyMatch(), noneMatch()boolean allMatch (Predicate<? super T> predicate) //모든 요소가 조건을 만족시키면 true boolean anyMatch (Predicate<? super T> predicate) //한 요소라도 조건을 만족시키면 true boolean noneMatch (Predicate<? super T> predicate) //모든 요소가 조건을 만족시키지 않으면 true- 조건에 일치하는 요소 찾기 - findFirst(), findAny()
Optional<T> findFirst() //첫 번째 요소를 반환. 순차 스트림에 사용 Optional<T> findAny() //아무거나 하나를 반환. 병렬 스트림에 사용 -
스트림의 최종연산 - reduce()
- 스트림의 요소를 하나씩 줄여가며 누적연산 수행 - reduce()Optional<T> reduce(BinaryOperator<T> accumulator) T reduce(T identity, BinatyOperator<T> accumulator) U reduce(T identity, Bifunction<U, T, U> accumulator, BinaryOperator<U> combiner)
identity - 초기값
accumulator - 이전 연산결과와 스트림의 요소에 수행할 연산
combiner - 병렬처리된 결과를 합치는데 사용할 연산(병렬 스트림) -
collect()와 Collectors
- collect()는 Collecors를 매개변수로 하는 스트림의 최종연산Object collect(Collector collector) //Collector를 구현한 클래스의 객체를 매개변수로 Object collect(Supplier supplier, BiConsumer accumulator, BiConsumer combiner) //잘 안쓰인- Collector는 수집(collect)에 필요한 메서드를 정의해 놓은 인터페이스
- Collectors 클래스는 다양한 기능의 컬렉터(Collector를 구현한 클래스)를 제공 -
스트림을 컬렉션, 배열로 변환 -> collect method 사용
- 스트림을 컬렉션으로 변환 - toList(), toSet(), toMap(), toCollection()
- 스트림을 배열로 변환 - toArray() -
스트림의 통계 - counting(), summingInt() -> collect method 사용
- 스트림의 통계정보 제공 - counting(), summingInt(), maxBy(), minBy()... -
스트림을 리듀싱 - reducing() -> Collectors 사용
-스트림을 리듀싱 - reducing()Collector reducing(BinaryOperator<T> op) Collector reducing(T identity, BinaryOperator<T> op) Collector reducing(U identity, Function<T, U> mapper, BinaryOperator<U> op) //map + reduce- 문자열 스트림의 요소를 모두 연결 - joining()
