class 글쓰는기계 {
private let TIL도우미: 키워드서쳐
init() {
self.TIL도우미 = 키워드서쳐()
}
func TIL쓰기() -> String {
let 키워드 = TIL도우미.데이터가져오기()
return "오늘은 \(키워드)에 대해 알아보겠습니다"
}
}
// 저수준 모듈
class 키워드서쳐 {
func 데이터가져오기() -> String {
return "키워드 서쳐가 추천해준 키워드"
}
}
강한 결합도
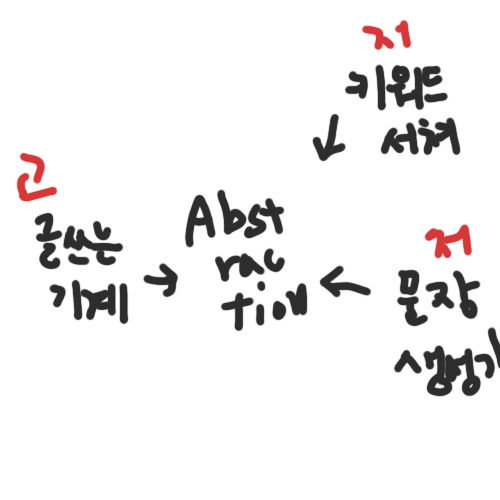
위는 고수준 모듈인 글쓰는기계가 저수준 모듈인 키워드서쳐 에 직접적으로 의존하고 있다.
만약 키워드서쳐가 변경되거나 다른 데이터 소스로 변경되야할 경우 고수준 모듈도 수정해줘야한다. 또한 나중에 저수준 모듈이 늘어날 경우에도 수정이 번거로워진다. 이처럼 강한 의존성을 띄는 경우 결합도(Coupling)가 강하다고 표현한다.
또한 테스트에 있어서 글쓰는기계를 테스트하려면 키워드서쳐 가 필요하다. 개별 단위 테스트가 어려워지고 독립성을 갖기 어렵다.
이러한 문제를 해결하기 위해 의존성 역전 원칙을 적용하면 고수준모듈과 저수준 모듈간의 결합도를 낮출 수 있다. 즉 모듈 간의 독립성을 유지하고 코드 유연성과 확장성을 높일 수 있게 된다.
한줄 요약 : 의존성 역전 원칙을 안지킬 때 추후에 추가,수정,삭제 시 괴로워짐, 단위 테스트 불가
의존성 역전 원칙을 적용
// 추상 클래스 정의
class Abstraction {
func 데이터가져오기() -> String {
fatalError("메서드를 저수준모듈에서 구현하슈")
}
}
// 고수준 모듈
class 글쓰는기계 {
private let TIL도우미: Abstraction
init(도우미: Abstraction) {
self.TIL도우미 = 도우미
}
func TIL쓰기() -> String {
let 키워드 = TIL도우미.데이터가져오기()
return "오늘은 \(키워드)에 대해 알아보겠습니다"
}
}
// 저수준 모듈
class 키워드서쳐: Abstraction {
override func 데이터가져오기() -> String {
return "키워드 서쳐가 추천해준 키워드"
}
}
// 저수준 모듈 2
class 문장생성기: Abstraction {
override func 데이터가져오기() -> String {
return "문장을 만듭니다 만들만들"
}
}
Abstraction이라는 추상클래스를 생성하고 고수준 모듈과 저수준 모듈 모두 이것에 의존하도록 한다. 저수준모듈이 늘어나야할 때 그것에 대해서만 작성하면 되는 것이다. 삭제할 때도 마찬가지.
다음주에 프로토콜을 공부하고 더 편리해지는지 비교해보면 좋을 것 같다.

오늘 배운걸 까먹었을 미래의 나에게..⭐️