
탐색(Search)이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정이다.
프로그래밍에선 그래프, 트리 등 자료구조 안에서 탐색을 하는 문제를 많이 다룬다.
대표적인 탐색 알고리즘: DFS, BFS
필요한 자료구조 기초
DFS, BFS 를 이해하기 위해선 스택, 재귀함수, 큐에 대해 알아야한다.
스택, 큐, 재귀함수
1. 스택
- 선입후출(FILO)/후입선출(LIFO)의 구조
- 파이썬에서 스택을 이용할 땐 별도의 라이브러리를 사용할 필요가 없다.
기본 리스트에서 append(), pop() 메서드 이용.
2. 큐
-
선입선출(FIFO) 구조
-
파이썬에서 큐를 구현할 땐 collections 모듈에서 제공하는 deque 자료구조를 사용.
- deque란 스택, 큐의 장점을 모두 채택한 구조인데, 데이터를 넣고 빼는 속도가 일반 리스트 자료형에 비해 효율적이다.
(queue 라이브러리 이용보다 더 간단)
from collections import deque queue = deque() #큐 구현 queue.append(5) #원소 추가 queue.popleft() #선입선출 하기 위해 left사용 - deque란 스택, 큐의 장점을 모두 채택한 구조인데, 데이터를 넣고 빼는 속도가 일반 리스트 자료형에 비해 효율적이다.
-
deque 객체를 리스트 자료형으로 변경하고자 한다면 list()를 이용하자.
이 소스코드에선 list(queue)를 하면 리스트로 변환.
3. 재귀함수
-
종료 조건을 꼭 명시해야 한다.
(조건을 빠트릴 시, 보통 파이썬 인터프리터는 호출 횟수 제한이 있으므로 무한대로 진행하진 않고 RecursionError를 출력한다.) -
재귀함수의 수행은 스택 자료구조를 이용한다.
가장 마지막에 호출한 함수가 먼저 수행을 끝내야 그 앞의 호출이 종료되기 때문.따라서 스택을 활용한 알고리즘의 대부분은 재귀함수를 이용하면 간편하게 구현할 수 있다.
DFS가 대표적인 예시이다. -
재귀함수는 간결한 형태를 갖는다.
간결해진 이유는 재귀함수가 수학의 점화식(재귀식)을 그대로 옮겨놓은 코드이기 때문이다.
수학에서 점화식은 특정한 함수를 자신보다 더 작은 변수에 대한 함수와의 관계로 표현한 것을 의미한다.[1] n이 0 혹은 1일 때:
[2] n이 1보다 클 때:
ex) 재귀함수의 대표적 예제: 팩토리얼
# 반복적으로 구현한 n!
def factorial_iterative(n):
result = 1
# 1부터 n까지의 수를 차례대로 곱하기
for i in range(1, n + 1):
result *= i
return result
# 재귀적으로 구현한 n!
def factorial_recursive(n):
if n <= 1: # n이 1 이하인 경우 1을 반환
return 1
# n! = n * (n - 1)!를 그대로 코드로 작성하기
# 점화식 형태 그대로 차용
return n * factorial_recursive(n - 1)그러므로 우리는 점화식에서 종료 조건을 찾을 수 있다.
탐색 알고리즘
DFS(Depth-First Search)
깊이 우선 탐색, 그래프에에서 깊은 부분을 우선적으로 탐색하는 알고리즘.
그래프는 크게 2가지 방식으로 표현한다.
- 인접 행렬(Adjacency Matrix): 2차원 배열에 각 노드의 연결된 형태를 기록
- 인접 리스트(Adjacency List): 리스트로 각 노드의 연결된 노드에 대한 정보만 연결하여 저장.
인접 행렬, 인접 리스트
인접 행렬
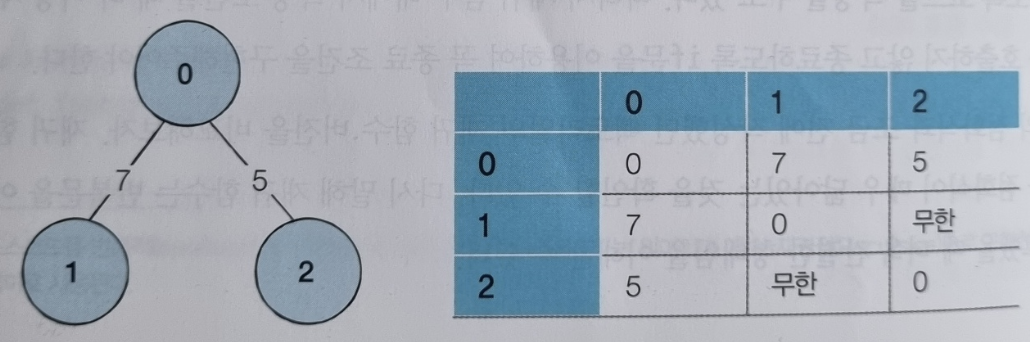 왼쪽의 그래프를 오른쪽의 인접 행렬로 나타낸 것.
왼쪽의 그래프를 오른쪽의 인접 행렬로 나타낸 것.
- 연결되어 있지 않은 노드끼린 무한의 비용을 부여.(ex. 999999999로 초기화)
- 인접행렬 코드
INF = 999999999 # 무한의 비용 선언
# 2차원 리스트를 이용해 인접 행렬 표현
graph = [
[0, 7, 5],
[7, 0, INF],
[5, INF, 0]
]
print(graph)인접 리스트
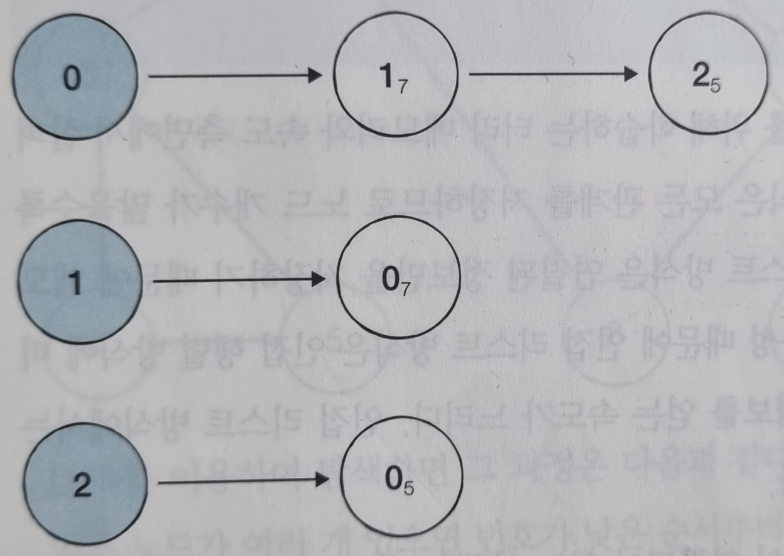
- 각 노드의 연결된 정보만 차례대로 연결하여 저장한다.
- 인접 리스트 코드
# 행(Row)이 3개인 2차원 리스트로 인접 리스트 표현
graph = [[] for _ in range(3)]
# 노드 0에 연결된 노드 정보 저장 (노드, 거리)
graph[0].append((1, 7))
graph[0].append((2, 5))
# 노드 1에 연결된 노드 정보 저장 (노드, 거리)
graph[1].append((0, 7))
# 노드 2에 연결된 노드 정보 저장 (노드, 거리)
graph[2].append((0, 5))
print(graph)
# [[(1, 7), (2, 5)], [(0, 7)], [(0, 5)]]
- 메모리 측면에서 봤을 땐 인접 행렬은 모든 관계를 다 저장해야 하므로 노드의 수가 많을 땐, 메모리가 낭비된다.
따라서 특정한 노드와 연결된 모든 인접 노드를 순회하는 경우, 인접 리스트 방식이 공간의 낭비가 적다.- 하지만 속도 측면에선 특정 두 노드가 연결되어 있는지의 확인할 땐,
행렬 방식에선 graph[1][7] 만 확인하면 되지만, 리스트 방식은 노드 1에 대한 인접 리스트를 앞부터 확인해야 하므로 속도가 느리다.
DFS 알고리즘
- 탐색 시작 노드를 스택에 삽입 -> 해당 노드 방문 처리
- 스택의 최상단(top) 노드에 방문하지 않은 인접 노드가 있으면, 그 인접 노드를 스택에 넣고 방문 처리 한다.
방문하지 않은 인접 노드가 없으면 스택에서 최상단노드를 꺼낸다. - 2번 과정을 더 이상 수행할 수 없을 때까지 반복한다.
- 실제론 스택을 사용하지 않아도 탐색을 수행함에 있어선 데이터 개수가 N개인 경우 O(N)의 시간이 소요된다.
DFS 코드
# DFS 함수 정의
def dfs(graph, v, visited):
# 현재 노드를 방문 처리
visited[v] = True
print(v, end=' ')
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
visited = [False] * 9
# 정의된 DFS 함수 호출
dfs(graph, 1, visited)BFS(Breadth First Search)
너비 우선 탐색, 인접한 노드부터 탐색하는 알고리즘이다.
DFS는 최대한 멀리 있는 노드를 우선으로 탐색하는 반면 BFS는 그 반대이다.
- BFS의 구현은 선입선출 방식인 큐 자료구조를 이용한다.
BFS 알고리즘
- 탐색 시작 노드를 큐에 삽입 -> 방문 처리
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 것을 모두(대체로 작은 번호순) 큐에 삽입 -> 방문처리한다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
BFS 구현 특징
- 앞에 언급한 deque 라이브러리를 사용하는 것이 좋고, O(N)의 시간이 소요된다.
- 일반적인 경우 수행시간이 DFS보다 좋은 편이다.
(재귀함수로 DFS를 구현하면 실제 시스템 동작 특성상 수행시간이 느려질 수 있다. 그러므로 스택 라이브러리를 써서 시간을 줄이는 테크닉이 필요할 때도 있지만,코테에선 보통 DFS보다 BFS구현이 더 빠르게 동작한다.)
BFS 코드
from collections import deque
# BFS 함수 정의
def bfs(graph, start, visited):
# 큐(Queue) 구현을 위해 deque 라이브러리 사용
queue = deque([start])
# 현재 노드를 방문 처리
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
# 큐에서 하나의 원소를 뽑아 출력
v = queue.popleft()
print(v, end=' ')
# 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
# 각 노드가 연결된 정보를 리스트 자료형으로 표현(2차원 리스트)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 리스트 자료형으로 표현(1차원 리스트)
visited = [False] * 9
# 정의된 BFS 함수 호출
bfs(graph, 1, visited)정리
| DFS | BFS | |
|---|---|---|
| 동작 원리 | 스택 | 큐 |
| 구현 방법 | 재귀 함수 이용 | 큐 자료구조 이용 |
