Building Agentic RAG with LlamaIndex - 1. Router Query Engine
retrieval-augmented-generation
목록 보기
5/17
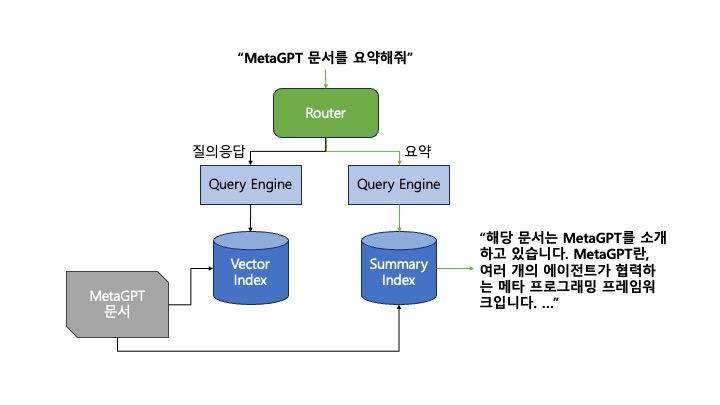
Router
- 쿼리가 주어졌을 때 어떤 쿼리 엔진을 사용할지 선택
- e.g. 요약 쿼리 엔진과 질의응답 쿼리 엔진이 있을 때, 무엇을 선택할지 결정
Index
- 데이터를 기반으로 한 일종의 메타데이터
- 인덱스 별로 다른 retrieval 양상을 보임
- Vector Index는 사용자 쿼리와의 임베딩 유사성을 기반으로 retrieve
- Summary Index는 사용자의 쿼리와 상관 없이 인덱스에 있는 모든 노드를 retrieve
from llama_index.core import SummaryIndex, VectorStoreIndex
summary_index = SummaryIndex(nodes)
vector_index = VectorStoreIndex(nodes)Query Engine
- 인덱스에 저장된 데이터에 대한 쿼리 인터페이스
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
vector_query_engine = vector_index.as_query_engine()Query Tool
- 쿼리 엔진에 메타데이터를 추가한 도구
- 도구가 대답할 수 있는 질문의 종류에 대한 설명이 메타데이터에 포함
from llama_index.core.tools import QueryEngineTool
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to MetaGPT" # 쿼리 엔진의 메타데이터
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description=(
"Useful for retrieving specific context from the MetaGPT paper." # 쿼리 엔진의 메타데이터
),
)Selector
- LlamaIndex는 라우터를 만들 수 있는 여러 개의 Selector 제공
- LLM selector
- 언어모델에 텍스트 프롬프트를 사용해 JSON 형식으로 파싱을 진행
- 상응하는 인덱스가 쿼리되도록 함
- Pydantic selector
- Fucntion Calling API (e.g. OpenAI에서 제공)을 활용해 pydantic selection 객체를 생성
from llama_index.core.query_engine.router_query_engine import RouterQueryEngine
from llama_index.core.selectors import LLMSingleSelector
query_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(), # LLM selector 사용
query_engine_tools=[
summary_tool,
vector_tool,
],
verbose=True # 진행 과정 확인 가능
)
response = query_engine.query("What is the summary of the document?")
Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab