들어가며
- 최근 자연어처리 분야는 거대한 사전학습 모델을 원하는 태스크에 맞춰 튜닝하는 방식으로 발전
- 관련 키워드
- in-context learning
- prompting
- fine-tuning
- prefix-tuning
- p-tuning
GPT-3 (Language Models are Few-Shot Learners)
- OpenAI가 발표한 GPT-3는 어마어마한 규모와 더불어 뛰어난 성능을 자랑함
- in-context learning과 prompting이라는 새로운 패러다임을 제시
- 아래 내용은 Section 2. Approach를 정리한 내용

Traditional | Fine-tuning (파인튜닝)
- 파인튜닝이란 원하는 태스크에 특화된 지도학습 데이터셋을 학습시킴으로써 사전학습된 모델(Large Pretrained Language Model)의 가중치(weight)을 업데이트하는 방법
- 가중치를 업데이트한다는 것은, 원하는 태스크에 맞는 언어적 특징을 학습한다는 것을 의미
- 태스크 예시: 감정분석, 기계번역, 요약, 질의응답 등
- 지도학습이기 때문에 정답이 라벨링이 된 굉장히 많은 수의 데이터들이 사용됨
- 굉장히 좋은 성능을 보여주지만, 여러 가지 한계가 존재
- 매 태스크마다 새로운 큰 규모의 데이터셋이 필요
- 일반화가 잘 되지 않는(poor generalization) 문제가 발생할 수 있음
- 언어에 대한 일반적인 지식을 학습한 pretrained model의 파라미터를 원하는 태스크에 맞춰 조정하는 과정에서 일반화 성능이 감소할 수 있음
New | In-context Learning (Few-Shot, One-Shot, Zero-Shot)
- 인컨텍스트 러닝이란, 언어모델의 인풋 앞에 자연어 태스크에 대한 설명과 몇 가지 예시를 더해 모델에 넣으면, 언어모델이 태스크에 맞는 아웃풋을 생성하는 새로운 학습방법
- prepending instructions and a few examples to the task input and generating the output form the Language Model
- 프롬프팅이란, 자연어 이해 및 생성에 있어서 언어모델의 예측을 도울 수 있도록 인풋 컨텍스트에 특별한 템플릿을 사용하는 것을 의미
- leverage special templates in the input context to aid the language model prediction with respect to both understanding and generation
- 가중치(weight)의 업데이트가 일어나지 않음
- 대량의 데이터셋이 필요하지 않음
- 예시의 개수에 따라 크게 퓨샷(2개 이상), 원샷(1개), 제로샷(0개)으로 구분
Few-shot(FS)
- 언어모델이 추론(inference)을 할 때, 태스크에 대한 몇 개의 demonstration(예시)이 주어짐
- context(문맥)와 completion(정답)에 대해서 K개의 예시가 주어지면, 답을 얻고자 하는 context가 주어졌을 때 모델이 completion을 제공
- 장점
- 태스크에 특화된 데이터의 필요성을 감소시킴
- 파인튜닝의 문제점으로 꼽히는 (narrow distribution의 학습으로 인한) 일반화 성능 감소의 가능성을 낮춰줌
- 사전학습된 모델에 내재되어 있는 태스크들 사이의 넓은 분포를 학습하고(=일반화 성능을 놓치지 않으며), 새로운 태스크에 빠르게 적응
- 단점
- SOTA(state-of-the-art) 파인튜닝에 비해 성능이 다소 떨어짐
- 여전히 태스크 특화 데이터가 일부 필요
One-shot(1S)
- 퓨샷과 유사하지만 오직 하나의 demonstration(예시)만 허용
- 사람이 자연어 태스크를 수행하는 방식과 유사
- 예를 들어, 우리는 "이 영화 완전 노잼"이라는 문장을 bad로 분류하라는 하나의 예시만 보더라도, 다른 여러 영화 리뷰에 대해서 "good" 혹은 "bad"로 분류할 수 있음
Zero-shot(0S)
- demonstration(예시)이 없고, 태스크를 설명하는 자연어 설명(instruction)만 주어짐
- 굉장히 편리하지만 가장 어려우며, 1S과 마찬가지로 사람이 하는 방식과 굉장히 유사
- 우리는 "I am a boy"라는 문장을 한국어로 번역하라 라는 instruction만 보고서도 "나는 소년이다"라는 문장을 만들어냄
GPT-3 모델의 아키텍처
- GPT-3는 기본적으로 GPT-2와 동일한 모델과 아키텍처를 가짐
- modified initialization, pre-normalization, reversible tokenization
- Sparse Transformer와 유사하게 트랜스포머의 레이어에 dense / locally banded sparse attention pattern을 번갈아가면서 사용
학습 데이터셋
데이터 수집
- 1) CommonCrawl에서 유사성 기반으로 필터링 진행
- 2) 문서 레벨에서 fuzzy deduplication 수행
- redundancy(불필요한 중복) 방지
- validation set의 integrity(무결성) 보존
- 유사한 내용의 문서를 제거했다고 이해할 수 있음
- 3) high-quality reference corpora 추가
- 유사한 데이터를 제거해 일반화 성능을 달성하고자 함
- 높은 품질의 말뭉치를 포함
데이터 학습
- 단순히 데이터셋의 크기에 비례해 학습 데이터를 샘플링하지는 않음
- 품질이 높다고 판단한 데이터를 더욱 빈번하게 샘플링(=학습에 사용)
- CommonCrawl, Books2는 한 번 미만으로 샘플링
- 다른 데이터셋은 2-3번정도 샘플링
- 높은 품질의 학습 데이터를 위해서 약간의 오버피팅을 허용
- 다만 논문에서는 훈련 셋과 테스트 셋의 데이터가 겹치는 것을 최대한 방지하고자 노력했으나, 약간은 남아있어 영향도가 있었다고 설명
학습 과정
- 모델이 클수록 더욱 큰 배치 사이즈를 필요로 하며, 더욱 작은 learning rate를 필요로 한다는 아이디어에 기초
- 학습 과정에서 OOM(out of memory), 즉 메모리 부족 문제를 방지하고자 함
- model parallelism within each matrix multiply
- model parallelism across layers of the network
- model parallelism(모델 병렬처리)이란 모델의 크기가 너무 커서 하나의 GPU 메모리에서 학습이 불가능할 때, 여러 GPU에 모델의 파라미터를 나누어 연산하는 것을 의미
Prefix Tuning (Prefix-Tuning: Optimizing Continuous Prompts for Generation)
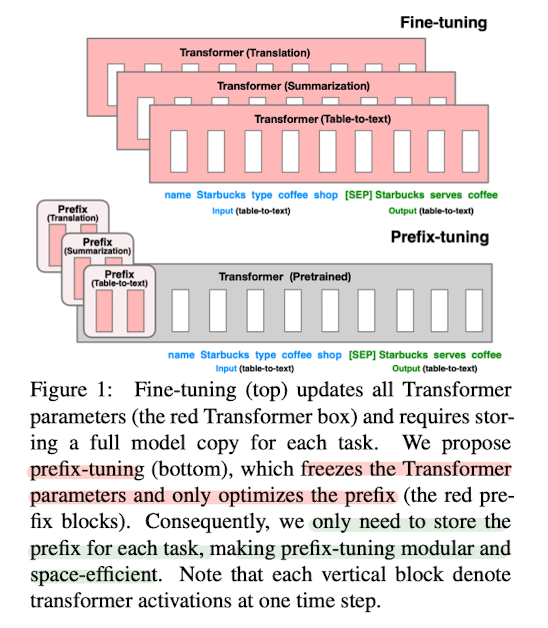
- 2021년 1월에 나온 논문
- GPT-3에서 나온 프롬프팅 기법에서 영감을 얻어 Prefix-Tuning을 창안
- 파인튜닝의 경우 전체 LM(언어모델)의 파라미터를 수정해야 하며 새로운 태스크를 학습함에 있어서 기존 모델의 전체 copy를 필요로 함
- 하지만 Prefix-Tuning은 LM의 파라미터는 freeze, 즉 고정시키고 prefix라고 불리는 작은 연속적인 태스크 특화 벡터(continuous task-specific vector)를 최적화
- 뒤따라오는 토큰들이 prefix를 attend할 수 있도록 함
- NLG(natural language generation), 즉 자연어 생성 태스크에서 파인튜닝에 비해 오직 0.1%의 파라미터만 학습하면서도 파인튜닝과 맞먹는, 학습데이터가 적을 때에는 파인튜닝보다 더 좋은 성능을 달성
이전 연구
- GPT-3의 in-context learning 이후 사전학습된 모델의 파라미터를 고정시킨 채, 파인튜닝보다 더 가벼우면서도 비슷한 성능을 낼 수 있는 방법에 대한 연구가 활발히 이루어짐
- In-context learning은 사람이 작성한(고안한) prompt를 사용
- 사람이 직접 수동으로(manual) 작성했기 때문에 어떻게 작성하느냐에 따라 성능이 크게 달라짐
- 하지만 인간이 이해하는 바와 기계가 이해하는 바가 다르기 때문에, 어떻게 프롬프트를 작성해야 모델로부터 좋은 아웃풋을 얻을 수 있는지는 여전히 연구 대상
- context window (허용 가능한 인풋 길이)보다 더 큰 학습 데이터셋을 이용할 수 없다는 한계
- 사람이 직접 수동으로(manual) 작성했기 때문에 어떻게 작성하느냐에 따라 성능이 크게 달라짐
- 이러한 한계를 극복하고자 사람이 자연어로 작성한 프롬프트를 사용하는 게 아니라 자동으로 discrete, 즉 자연어로 구성된 프롬프트를 찾으려는 연구도 진행됨
- AutoPrompt가 그 중 하나
- 이는 일련의 discrete trigger words(일종의 자연어 프롬프트)를 각각의 인풋 앞에 붙여 사용하는 방식을 취함
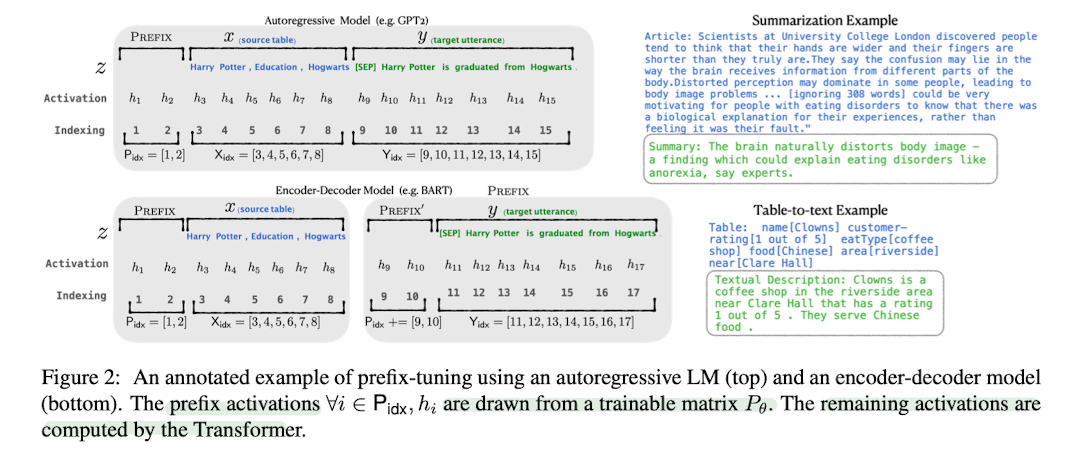
Prefix Tuning
- Prefix Tuning은 이전의 연구에서 더 나아가, 인풋의 앞에 prefix, 즉 일련의 연속적인 태스크 특화 벡터(a sequence of continuous task-specific vectors)를 붙이는 방식
- prefix 뒤에 이어지는 토큰들은 앞에 나온 prefix를 일련의 가상의 토큰인 것처럼 attend
- prefix는 prompt와는 다르게 실제 토큰(=자연어 단어)과 대응되지 않는 free parameter
- 다시 말해, prefix tuning은 별개의 개별적인 토큰(=단어)들의 최적의 집합을 만드는 게 아님
- 연속적인 단어의 임베딩(=숫자로 표현된 단어의 특성)을 최적화하는 데에 초점
- optimize instruction as continuous word embeddings, whose effects will be propagated upward to all Transformer activation layers and rightward to subsequent tokens.
- Prefix는 언제나 인풋의 왼쪽에 위치하기 때문에, 모든 트랜스포머의 activation 레이어와 오른쪽에 뒤이어 나오는 토큰들에 영향을 줄 수 있음
- prefix tuning의 가장 큰 장점은 NLG(자연어 생성) 태스크에서 LM(언어모델)의 파라미터 변경 없이도 모델이 적절한 컨텍스트를 취하도록 할 수 있다는 점
- 예를 들어 "오바마"라는 단어를 언어모델이 생성하도록 만들고 싶다고 가정
- 이를 위해 컨텍스트로 "버락"이라는 common collocation(연어; 함께 자주 결합되어 사용되는 단어)을 prepend하면 모델은 컨텍스트에 적합한 단어에 더 높은 확률값을 할당
- 이러한 아이디어에서 출발해 prefix tuning은 downstream LM을 바람직한 방향으로 가이드할 수 있는 upstream prefix(연속적인 벡터)를 최적의 방향으로 학습
- "버락"이라는 단어는 discrete한 예시라고 볼 수 있지만, 이와 비슷한 맥락(컨텍스트)을 가진 최적의 연속적인 벡터를 학습하는 것이 바로 prefix tuning의 지향점
- prefix tuning은 modular한 특성을 가짐
- 이를 통해 personalization(개인화)가 가능
- 즉 각각의 사용자에 별개의 prefix를 사용하여 한 번의 배치에서 여러 명의 사용자/태스크를 처리할 수 있음
성능비교 (결과)
- table-to-text, summarization 등의 NLG 태스크 수행
- table-to-text의 경우 E2E, WebNLG, DART 데이터 사용, 파인튜닝과 유사한 성능
- summarization task에서는 XSUM 데이터를 사용, 파인튜닝보단 약간 떨어지는 성능
- 데이터가 적을 시에는 두 가지 태스크에 대해 prefix-tuning이 모두 파인튜닝보다 좋은 성능을 보임
P-tuning (GPT Understands, Too)
- 일반적으로 GPT(uni-directional)는 자연어 생성(NLG) 태스크에 강하며 BERT(bi-directional)는 자연어 이해(NLU) 태스크에 강하다고 알려짐
- P-tuning 논문에서는 학습이 가능한 연속적인 프롬프트 임베딩(trainable continuous prompt embeddings)을 통해, NLU에서 GPT가 BERT만큼, 혹은 그보다 더 나은 성능을 낼 수 있다고 주장
이전 연구
- 언어모델은 사전학습을 통해 contextualized text representation, grammar, syntactic, commonsence, world knowledge 등을 배운다고 알려짐
- 즉 문맥이 담고 있는 언어의 정보나 의미론적, 문법적 특성을 배울뿐만 아니라 그 속에 담긴 일반상식이나 세상에 대한 지식까지도 학습
- GPT-3는 이렇듯 일방향으로 학습한(uni-directional) 언어모델이 적절한 manual prompt(손으로 작성한 프롬프트)와 결합하면, 언어모델이 갖고 있는 이런 풍성한 정보들을 활용할 수 있다는 것을 증명
- 하지만 사람이 작성한 프롬프트는 효과적일 수도 있지만 최적의 성능을 내지 못할 수 있으며, 노동집약적
- 성능은 프롬프트의 의미, 형식, 문법(semantic, format, grammar)과 명확한 상관관계를 가지지 않기 때문
- 즉, 사람이 생각했을 때 합리적인 프롬프트가 반드시 언어 모델에 효과적인 것은 아님
- 또한 손으로 작성한 프롬프트에 적용된 마이너한 변화가 굉장히 큰 성능 차이를 야기
- 이를 해결하기 위해 자동으로 discrete prompt (별개의 자연어 토큰으로 이루어진 프롬프트)를 찾아보려는 연구들이 이루어짐
- P-tuning은 여기서 더 나아가 GPT와 NLU 사이의 갭을 메우기 위해 연속적인 공간에서 자동으로 프롬프트를 찾고자 함
- automatically search prompts in the continuous space to bridge the gap between GPT and NLU applications
P-tuning
- P-tuning은 사전학습된 LM(언어모델)에 인풋으로 프롬프트 역할을 하는 연속적인 파라미터를 사용
- discrete prompt searching의 대안으로 gradient descent를 통해 이러한 연속적인 프롬프트를 최적화
- leverages few continuous parameters to serve as prompts fed as the input to the pre-trained LM. then optimize the contiuous prompts using gradient descent as an alternative to discrete prompt searching.
- Gradient Descent란 딥러닝에서 예측값과 실제 정답 사이의 오차를 최소화하고 최적화된 가중치를 학습하기 위해 사용되는 방법
- practical하게 많이 사용하는 Adam 등의 대부분의 optimizer들은 다 Gradient Descent 방법에 그 뿌리를 두고 있음
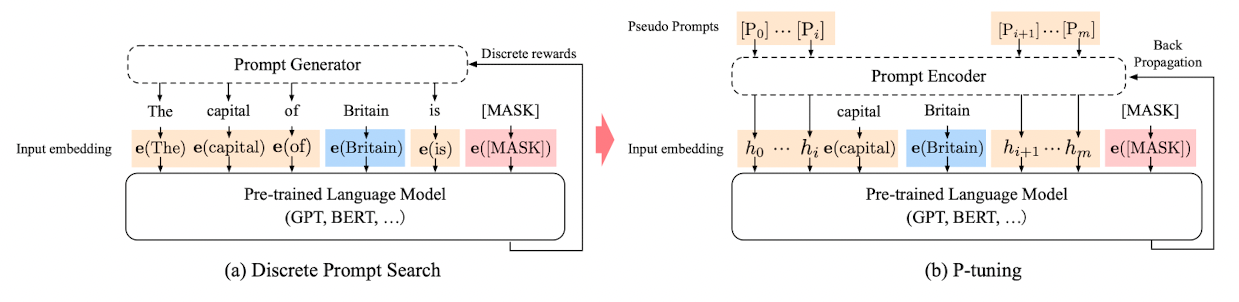
- 파란색으로 표시된 Britain이 context, 빨간색으로 표시된 [MASK]가 target, 나머지 노란색 부분이 prompt token
- P-tuning에서는 pseudo prompt와 prompt encoder가 미분가능한 방법으로 최적화
- 다시 말해, discrete하게 접근하는 것이 아니라, 딥러닝의 기본을 이루는 gradient descent와 back propagation을 통해 trainable embedding tensor를 가정하고 더 나은 연속적인 프롬프트를 찾을 수 있도록 함
- non-invasive modification to the input. replaces the input embeddings of pre-trained LM with its differential output embeddings
- 이러한 연속적인 토큰에 "수도(capital)"와 같은 태스크와 관련된 앵커 토큰(task-related anchor token)을 추가하면 성능이 더욱 향상
P-tuning의 challenge: 최적화 문제
- 단순히 보자면 gradient descent와 back-propagation이라는 쉬운 방법을 적용한 것처럼 보이지만, P-tuning을 적용하기 위해선 해결해야 할 두 가지 문제가 존재
- 1) discreteness
- 사전학습 이후에 원래의 워드 임베딩이 이미 굉장히 discrete한 상태이기 때문에, 학습 대상인 h(trainable embedding tensor)를 랜덤하게 초기화한 이후에 SGD로 최적화를 시키면 local minima에 빠지게 됨
- 모델이 최적의 성능을 내기 위해서는 global minima, 즉 전체 공간을 모두 통틀어서 봤을 때 오차가 가장 작은 값에 도달해야 하는데, local minima는 일부 공간에서의 최소값이기 때문에 여기에 빠지게 되면 global minima를 달성하기 어려움
- 2) association
- 연속적인 프롬프트를 위해서는 prompt embedding이 독립적이지 않고 서로 의존적(dependent)이어야
- 이 두 개의 문제를 해결하기 위해 이 논문에서는 h라는 학습 가능한 임베딩 텐서를 굉장히 작고 가벼운 뉴럴 네트워크로 만들어진 프롬프트 인코더를 이용해 학습
- model the h as a sequence using a prompt encoder consists of a very lite neural network
- 이 뉴럴 네트워크는 LSTM과 ReLU activation으로 이루어진 two-layer perceptron
- 이러한 프롬프트 인코딩의 결과로 나온 output embedding h를 사용하고 LSTM의 head는 버림
성능비교 (결과)
- P-tuning은 벤치마크 데이터로 LAMA와 SuperGLUE를 사용
- LAMA의 경우 knowledge probing(지식 조사) 태스크에 사용
- 예를 들어서 (Dante, born-in, Florence)라는 triple을 cloze 문장으로 변환해 ("Dante was born in [MASK]") 언어모델에게 target을 추론하게 함
- 이런 경우 fine-tuning 기반의 방법보다 P-tuning이 비슷한 성능을 보이거나 더 좋은 성능을 보임
- 이러한 결과에 대해 논문은 fine-tuning의 경우 언어모델의 파라미터를 변경함으로써 중요한 정보를 잊어버릴 가능성이 존재하나, P-tuning의 경우 파라미터의 변경 없이 단지 프롬프트를 통해 언어모델이 갖고 있는 정보를 더 잘 가져올 수 있다고 설명
- SuperGLUE는 8개의 NLU 태스크의 성능을 측정할 수 있는 벤치마크
- SuperGLUE에서 테스트하기 위해 NLU(자연어 이해) 태스크를 빈칸을 채우는 태스크(blank filling)로 재구성
- P-tuning은 초기의 프롬프트 임베딩을 패턴 내의 다른 위치에 넣고 사전학습된 모델과 함께 프롬프트 임베딩을 파인튜닝
- P-tuning puts initial prompt embeddings in different positions within patterns and then finetunes the prompt embeddings together with the pretrained models.
- 이러한 경우, P-tuning과 GPT2를 합친 모델이 기존 자연어이해 태스크에 더 강점을 가지고 있다고 알려진 BERT 기반 모델들보다 비슷하거나 더 뛰어난 성능
- 특히 P-tuning은 low-resource setting, 즉 데이터 등이 부족한 상황에서 더 좋은 성능을 보임
- 하지만 WiC와 같이 cloze question의 형태로 만들 수 없는 태스트들의 경우 파인튜닝이 더 좋은 성능
Prefix tuning VS P-tuning
- 비슷한 시기에 비슷한 아이디어를 기반으로 나온 논문들
- 이 논문에서는 먼저 나온 Prefix tuning과 자신의 P-tuning이 어떻게 다른지를 정리
prefix tuning
- NLG(자연어생성), GPT를 위해 고안
- 프롬프트 토큰을 인풋 시퀀스의 앞에 붙여야 함
- continuous prompt token(연속적인 프롬프트 토큰)을 트랜스포머의 모든 레이어에 concat
p-tuning
- NLU(자연어이해), 모든 종류의 언어모델을 위해 고안
- 토큰을 어느 위치에든 삽입할 수 있음
- continuous prompt token을 인풋에만 붙여도 됨
- 어떻게 anchor prompt를 사용할 수 있을지 소개
의의
- P-tuning과 함께라면 GPT 또한 NLU 과제 수행 가능
- few-shot, fully-supervised 환경에서 GPT, BERT의 성능 향상에 모두 일조 (general method)
- fine-tuning없이 단순히 더 나은 프롬프트를 찾는 것만으로도 언어모델이 갖고 있는 풍부한 지식을 활용할 수 있음
- 특히 P-tuning은 사전학습된 모델의 파라미터들을 변경시키지 않고 단지 더 나은 연속적인 프롬프트를 찾는 것만으로 저장된 지식을 가져올 수 있음
- 더욱 적은 hand-craft(수작업)로 더욱 좋은 성능의 프롬프트를 자동으로 찾을 수 있음
P-tuning v2 (P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks)
- 프롬프트 튜닝은 frozen language model(파라미터를 고정시킨 언어모델)에 연속적인 프롬프트만 튜닝하는 작업을 의미
- 하지만 태스크와 모델 크기에 따라 보편성이 부족하다는 단점
- 이 논문은 이러한 문제의식에서 출발해, 적절하게 최적화된 프롬프트 튜닝이 다양한 모델 규모(scale)와 NLU 태스크에 대해 보편적으로 효과적이라는 것을 증명
- 오직 0.1-3%의 파라미터를 튜닝하는 것만으로도 파인튜닝과 유사한 성능
- 흥미로운 점은 P-tuning version 2라는 이름이 무색하게 이 논문은 prefix-tuning의 기본 구조를 이용해 NLU 태스크에 최적화된 튜닝 방법을 탐구
- 이를 이 논문에선 "deep prompt tuning"이라고 일컬으며, 이는 사전학습된 모델의 모든 레이어에 연속적인 프롬프트를 적용하는 것을 의미
- 사실 핵심적인 아이디어는 prefix tuning과 굉장히 유사
- deep prompt tuning을 통해 작은 모델과 어려운 태스크에 있어서 파인튜닝과의 성능 차이를 줄였다고 함
이전 연구
- 파인튜닝은 목표하는 태스크에 맞춰 모델의 전체 파라미터를 업데이트
- 이는 좋은 성능을 보여주었으나 메모리를 굉장히 많이 잡아먹음
- 반면 프롬프팅은 사전학습된 모델의 모든 파라미터를 고정시키고 자연어로 이루어진 프롬프트로 LM에게 질문을 던지는 방식을 사용
- 이는 학습이 필요없고 오직 모델의 파라미터들을 딱 하나만 copy하면 되었기 때문에 훨씬 효율적
- 다만 사람이 직접 프롬프트를 작성해야 했기 때문에 많은 경우에 sub-optimal, 즉 최적의 프롬프트를 보장할 수 없었음
- 연속적인 프롬프트를 튜닝하는 방식에서는 학습이 가능한 연속적인 임베딩을 인풋 워드 임베딩의 본래 시퀀스에 더하고, 학습 과정에서 오직 연속적인 프롬프트만 업데이트
- 예를 들어서 영화 리뷰 x = "Amazing movie!"를 긍정 혹은 부정으로 분류하고자
- "It is [MASK]"라는 프롬프트를 x(리뷰, 인풋값)에 붙인다고 생각하는 것이 자연스러움
- 마스크 토큰이 good, bad로 분류될 가능성을 조건부 확률(conditional probabilities)로 계산해 예측
- 이 경우에 프롬프트 토큰 {"It", "is", "[MASK]"}은 모델의 단어사전에 포함되며, 시퀀스의 인풋 임베딩은 [e(x), e("It"), e("is"), e("[MASK]")]가 됨
- 하지만 이러한 discrete natural prompt(별개의 단어로 이루어진 자연어 프롬프트)로는 최적의 결과를 낼 수 없음
- 따라서 P-tuning은 prompt token을 trainable continuous embeddings으로 대체
- 인풋 시퀀스는 따라서 [e(x), h0, ..., hi, e("[MASK]")]로 변화하였기 때문에, differentially optimized (미분을 이용해 최적화)가 가능
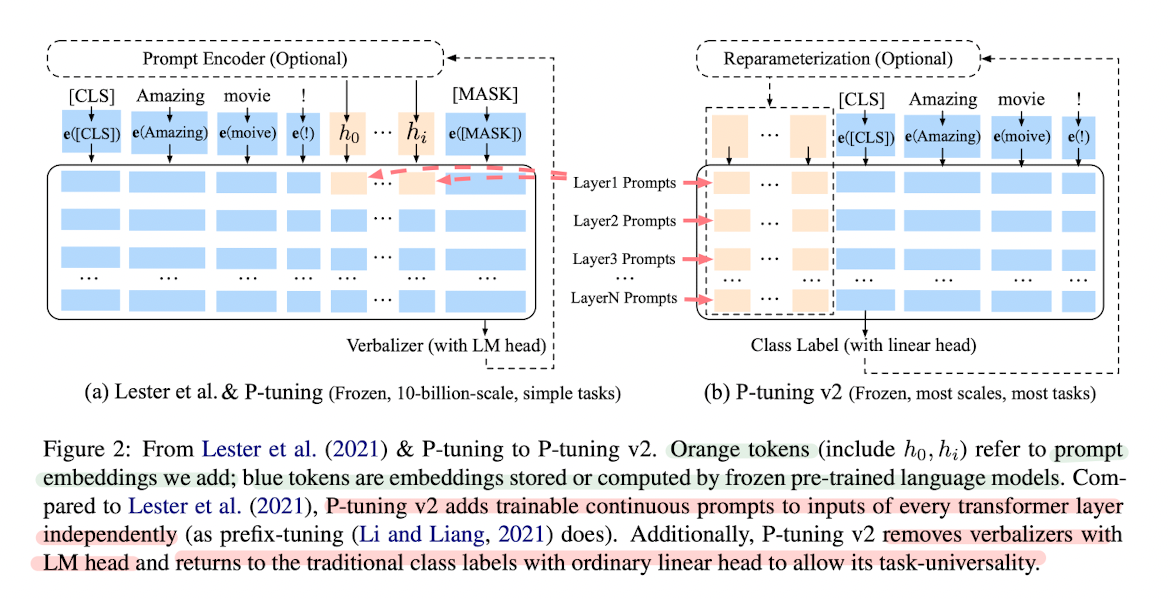
P-tuning version 2
- Prefix tuning은 원래 NLG를 위해 제안되었으나, 이 논문의 저자들은 이 구조가 NLU에도 효과적이라는 사실을 발견
- P-tuning에서 연속적인 프롬프트는 트랜스포머의 첫 번째 레이어에 인풋 임베딩에 삽입
- 하지만 이는 두 개의 최적화 문제를 야기한다.
- 1) limited amount of parameters to tune
- 대부분의 LM은 최대 512개의 토큰으로 이루어진 시퀀스 길이를 지원
- 연속적인 프롬프트를 넣으면 인풋에서 컨텍스트를 넣을 자리가 줄어듦
- 즉 튜닝할 수 있는 파라미터의 수에 제한이 생김
- 2) limited stability when tuning with very deep transformers
- 트랜스포머가 깊어질수록 프롬프트의 영향이 줄어듦
- 모델이 깊을수록 (=레이어를 많이 쌓을수록) 저 멀리 초반 인풋에 넣었던 프롬프트의 효과가 떨어짐
- 1) limited amount of parameters to tune
- 이를 해결하기 위해 P-tuning v2에서는 prefix tuning처럼 multi-layer prompt(deep prompt tuning), 즉 여러 레이어에 프롬프트를 붙이는 방법을 사용
- 각기 다른 레이어에 위치한 프롬프트는 인풋 시퀀스에 prefix 토큰으로 더해지고, 다른 interlayer들과는 독립적
- 이를 통해 더 많은 수의 태스크 특화 파라미터를 튜닝, 더 깊은 레이어에 더해진 프롬프트를 통해 결과 예측에 더 직접적이고 주요한 영향
- 이를 위해 기존 프롬프트 튜닝에 사용되었던 버벌라이저(Verbalizer) 대신 [CLS]와 토큰 분류를 사용
- 버벌라이저는 사전학습된 언어모델의 head에 사용하기 위해 숫자로 이루어진 one-hot 클래스 레이블을 의미있는 단어들로 만든 것
- 이게 실제적인 의미를 가진 레이블이나 문장 임베딩이 필요한 시나리오에 있어서 프롬프트 튜닝의 적용에 제약을 가함
- 이 때문에 [CLS]를 사용하는 전통적인 패러다임으로 회귀했다고 한다. (CLS label classification paradigm with random-initialized linear head)
성능비교 (결과)
- NLU 태스크에서 GLUE, SuperGLUE 데이터셋을 사용
- BERT 기반 모델들 (BERT-large, RoBERTa-large, DeBERATa-large)과 GLM-xlarge/xxlarge를 사용
- 이는 모두 NLU를 위해 고안된 bidirectional model
- 트랜스포머 모델의 모든 파라미터는 고정하였으며, 오직 태스크 특화 파라미터인 연속적인 프롬프트만을 튜닝
- 비슷한 조건의 파인튜닝과 비교해 0.1%의 파라미터만을 튜닝
- full-data supervised learning setting
- 괄목할만한 결과는 스케일과 태스크에 상관없이 파인튜닝과 일반적으로 견줄만한 성능을 보여준다는 점
- 참고로 이 논문이 제안하는 몇 가지 최적화를 위한 방법을 살펴보자면
- 1) reparameterization의 효과는 태스크와 데이터셋에 따라서 다르며 (성능이 더 나빠지기도 한다)
- 2) 태스크마다 최적의 성능을 내는 prompt length가 다르고
- 3) multi-task learning은 선택이지만 상당히 도움이 됨
- 특히 3번은 몇몇 어려운 sequence task에 있어서 P-tuning v2를 보완할 수 있었음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab